







前言
关于爬虫的基本知识推荐阅读:Python爬虫从入门到应用(超全讲解)
该知识点需要提前安装相关依赖:pip install lxml
1. 基本知识
XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语言
在XML文档中通过路径表达式(path expression)来定位节点,这些路径描述了节点在层次结构中的位置
一、节点:
在XML文档中,所有的内容都以节点的形式存在
主要有两种类型的节点:
- 元素节点(Element Nodes):代表XML文档中的元素,比如
<book>、<title>等 - 文本节点(Text Nodes):代表元素节点中的文本内容
二、路径表达式:(XPath使用路径表达式来选取节点或节点集。路径表达式可以基于节点名称、位置、属性等来定位节点)
常见的路径表达式包括:
/:从根节点开始选择节点//:选取节点,不考虑它们的位置.:选取当前节点..:选取当前节点的父节点@:选取属性
三、轴(Axis):(轴定义了相对于当前节点的节点集)
常用的轴包括:
ancestor:选取所有祖先节点child:选取所有子节点parent:选取父节点preceding-sibling:选取当前节点之前的所有同级节点following-sibling:选取当前节点之后的所有同级节点
四、操作符:(支持一系列操作符,用于比较、计算和连接表达式)
包括算术运算符(+、-、*、div、mod)、关系运算符(=、!=、<、>、<=、>=)等
五、函数(Functions):(一系列内置函数,用于执行各种操作,如字符串处理、数值计算、节点操作等)
常见的函数包括 string()、contains()、count()、concat()等
2. 常用API
-
xpath()方法:根据XPath表达式选择节点或节点集合 -
text 属性:获取节点的文本内容
-
attrib 属性:获取节点的属性值
-
find()方法:查找第一个匹配的节点 -
findall()方法:查找所有匹配的节点
以下是方法示例:
from lxml import etree
# XML字符串
xml_str = '''
<bookstore>
<book category="Fiction">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="Non-Fiction">
<title lang="en">The Elements of Style</title>
<author>William Strunk Jr.</author>
<year>1999</year>
<price>9.95</price>
</book>
</bookstore>
'''
# 创建Element对象
root = etree.fromstring(xml_str)
以下为方法示例:
# xpath() 方法示例
titles = root.xpath('//title/text()')
print("Titles:")
for title in titles:
print(title)
截图如下:

text属性 输出:First Book Title: Harry Potter
# text 属性示例
first_book_title = root.xpath('/bookstore/book[1]/title')[0].text
print("\nFirst Book Title:", first_book_title)
attrib属性 输出:First Book Category: Fiction
# attrib 属性示例
first_book_category = root.xpath('/bookstore/book[1]/@category')[0]
print("\nFirst Book Category:", first_book_category)
find方法 输出:First Non-Fiction Book Title: The Elements of Style
# find() 方法示例
first_non_fiction_book_title = root.find('.//book[@category="Non-Fiction"]/title')
print("\nFirst Non-Fiction Book Title:", first_non_fiction_book_title.text)
findall方法
# findall() 方法示例
all_authors = root.findall('.//author')
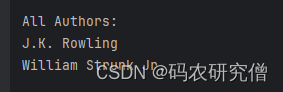
print("\nAll Authors:")
for author in all_authors:
print(author.text)
截图如下:
3. 简易Demo
根据以上的API以及输出结果,可稍微了解一些知识
以下为简单的XML示例来演示XPath的使用
还是刚刚那个xml文档,不过弄成文件放置
from lxml import etree
def main():
# 读取XML文件
with open('books.xml', 'r') as file:
xml_data = file.read()
# 解析XML
root = etree.fromstring(xml_data)
# 使用XPath选择所有书籍的标题
titles = root.xpath('/bookstore/book/title/text()')
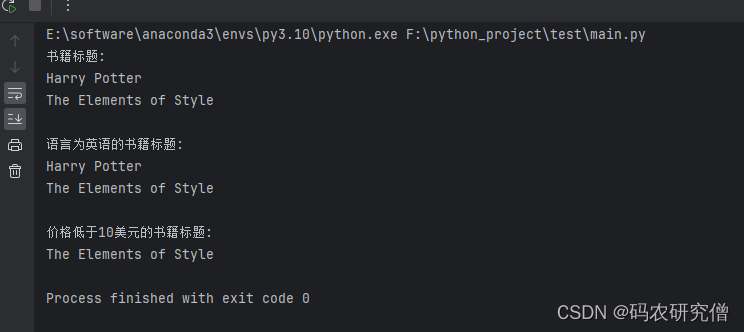
print("书籍标题:")
for title in titles:
print(title)
# 使用XPath选择所有语言为英语的书籍标题
english_titles = root.xpath('/bookstore/book/title[@lang="en"]/text()')
print("\n语言为英语的书籍标题:")
for title in english_titles:
print(title)
# 使用XPath选择所有价格低于10美元的书籍标题
cheap_titles = root.xpath('/bookstore/book[price < 10]/title/text()')
print("\n价格低于10美元的书籍标题:")
for title in cheap_titles:
print(title)
if __name__ == "__main__":
main()
截图如下:
注意我在上述Demo中都用到etree.fromstring(),但在其他文章又看到etree.HTML()
接下来阐述下这几个的差异:
| etree.HTML() | etree.parse() | etree.fromstring() |
|---|---|---|
| 解析HTML字符串,将传入的字符串解析为HTML文档,并构建相应的ElementTree对象 | 解析本地文件或可读文件对象中的XML或HTML文档 | 解析XML字符串,类似于etree.HTML() |
对于这几个函数的选择:
- 本地的HTML文件,可以使用
etree.parse()函数来解析 - HTML字符串,可以使用
etree.HTML()函数来解析 - 对于XML字符串,可以使用
etree.fromstring()函数
再次举例一个html的例子:
from lxml import etree
html = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试</title>
</head>
<body>
<div class="container">
<header>
<h1>欢迎来到我的网站</h1>
<nav>
<ul>
<li><a href="https://www.example.com/">首页</a></li>
<li><a href="https://www.example.com/about">关于我们</a></li>
<li><a href="https://www.example.com/contact">联系我们</a></li>
</ul>
</nav>
</header>
<section>
<h2>最新文章</h2>
<article>
<h3>文章标题1</h3>
<p>文章内容1</p>
</article>
<article>
<h3>文章标题2</h3>
<p>文章内容2</p>
</article>
</section>
<aside>
<h2>侧边栏</h2>
<ul>
<li>链接1</li>
<li>链接2</li>
<li>链接3</li>
</ul>
</aside>
<footer>
<p>版权所有 © 2024</p>
</footer>
</div>
</body>
</html>
'''
# 解析HTML
root = etree.HTML(html)
# 选择所有链接
links = root.xpath('//a')
print("所有链接:")
for link in links:
print("文本:", link.text)
print("URL:", link.attrib['href'])
# 查找侧边栏中的链接
sidebar_links = root.xpath('//aside//li')
print("\n侧边栏链接:")
for link in sidebar_links:
print("文本:", link.text)
结果输出如下:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











