







一、批量下载文件
网页分析
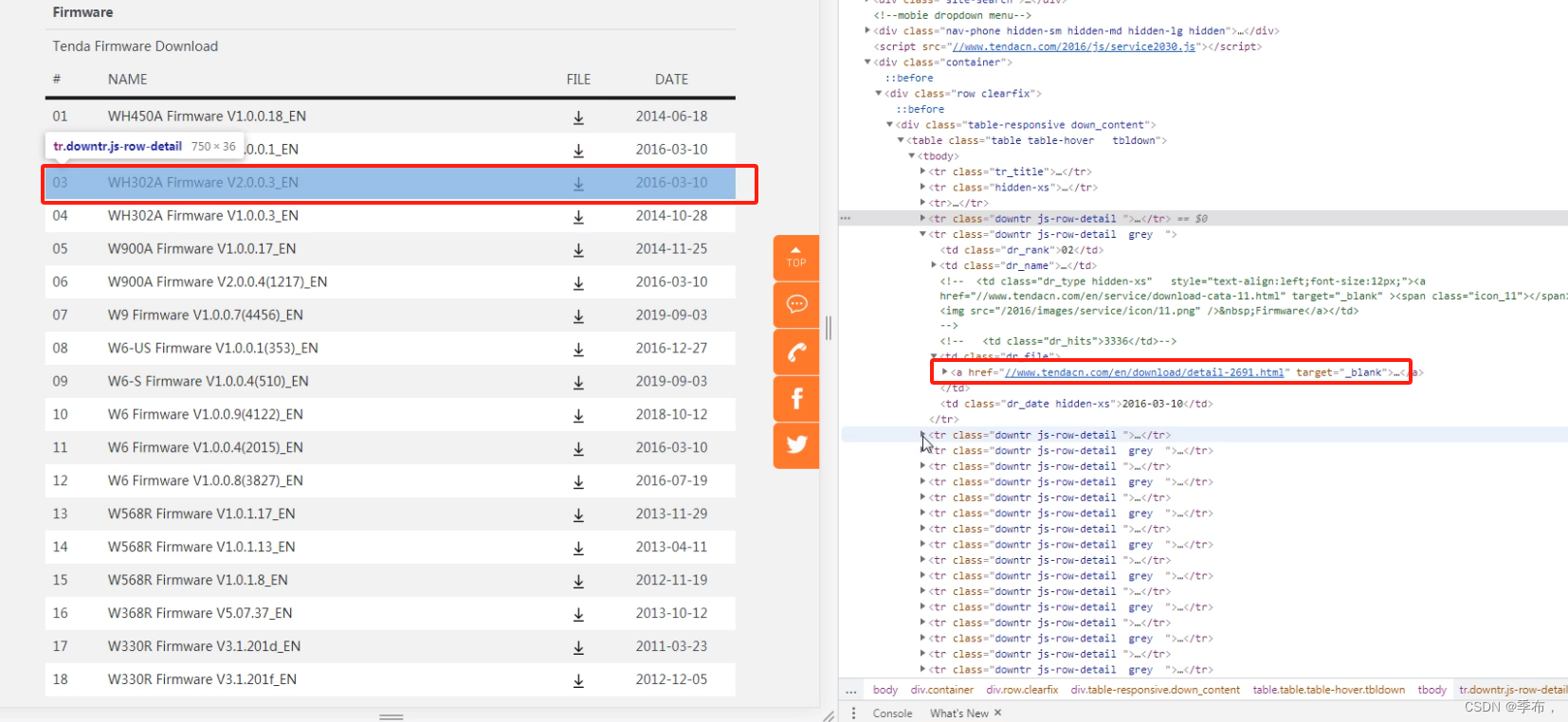
点击跳转到下载页面
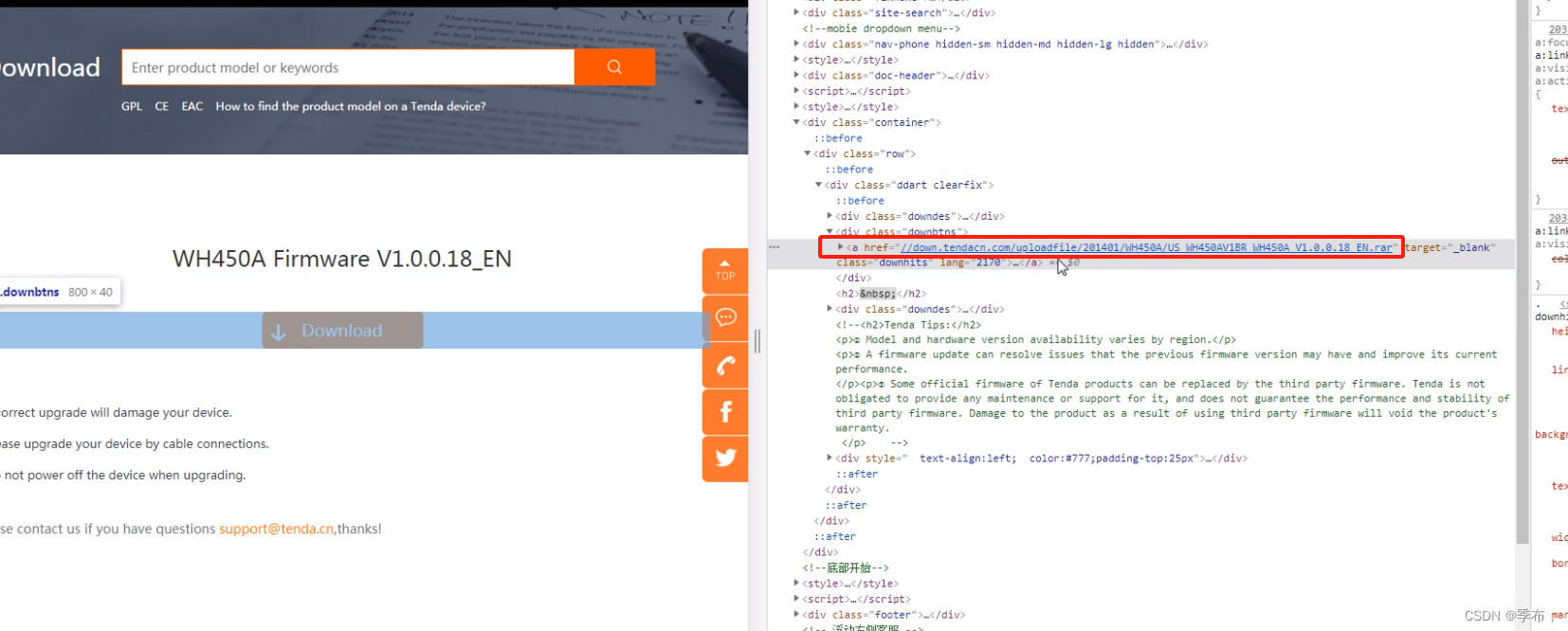
from selenium import webdriver
import time
def get_link_list():
# 创建浏览器对象
driver = webdriver.Chrome(
executable_path=r'C:\Users\nlp_1\Desktop\chromedriver\chromedriver-win32\chromedriver.exe')
url = 'https://www.tendacn.com/en/service/download-cata-11.html'
driver.get(url)
# 等待
driver.implicitly_wait(10)
css_elem = driver.find_elements_by_css_selector('.dr_file > a')
link_list = []
for link in css_elem:
page_link = link.get_attribute('href')
print(page_link)
link_list.append(page_link)
driver.close()
driver.quit()
return link_list
def get_download_links(link_list):
download_link_list = []
for i,link in enumerate(link_list):
if i == 0:
driver = webdriver.Chrome(
executable_path=r'C:\Users\nlp_1\Desktop\chromedriver\chromedriver-win32\chromedriver.exe')
driver.get(link)
else:
js = f'window.open("{link}")'
driver.execute_script(js)
# 每打开一个链接切换到该页面也就是最新的这个
driver.switch_to.window(driver.window_handles[-1])
download_elem = driver.find_element_by_css_selector('.downbtns > a')
download_link = download_elem.get_attribute('href')
download_link_list.append(download_link)
totals = len(download_link_list)
print(f'一共有{totals}个下载链接!')
driver.quit()
return download_link_list
def download_file(download_link_List):
for i,doanload_link in enumerate(download_link_List):
js = f'window.open("{doanload_link}")'
driver.execute_script(js)
print(30*'-')
print(doanload_link)
time.sleep(6)
print(f'第{i + 1}个文件正在下载中……')
# 程序执行入口
if __name__ == '__main__':
link_list = get_link_list()
download_link_List = get_download_links(link_list)
options = webdriver.ChromeOptions()
options.add_argument('--ignore-certificate-errors')
driver = webdriver.Chrome(options=options)
download_file(download_link_List)
二、网页自动化点击上报

# 指定账户名和密码登录
def login():
# 随机点一下 ,以便显示登录页面
driver.find_element_by_id('bodyMain').click()
# id=“username”是打开的网址中,账号登录的输入框,输入字符串“用户名”
username = input('请输入你的用户名:')
password = input('请输入你的密码:')
print('登录中……')
driver.find_element_by_id('username').send_keys(username)
driver.find_element_by_id('password').send_keys(password)
# id="submit"是点击登录, click() 是模拟点击
driver.find_element_by_id("submit").click()
time.sleep(2)
print('登录成功\n')
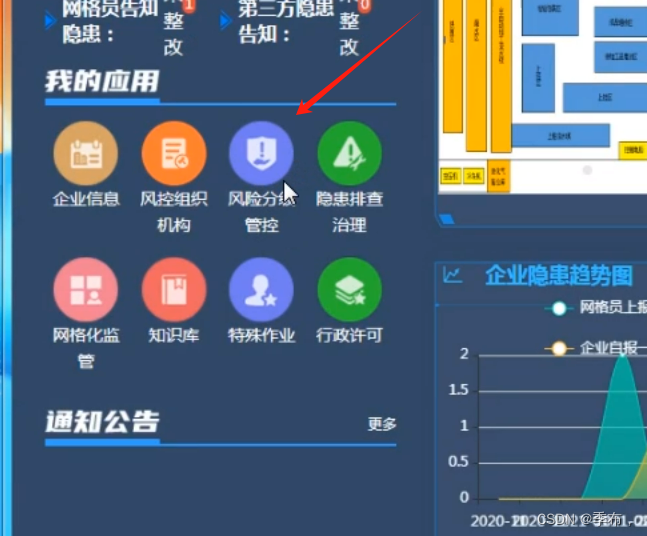
# 点击 风险分级管控
driver.implicitly_wait(5)
risk_grade_control = driver.find_element_by_link_text("风险分级管控")
risk_grade_control.click()
time.sleep(2)
print('已点击【风险分级管】\n')
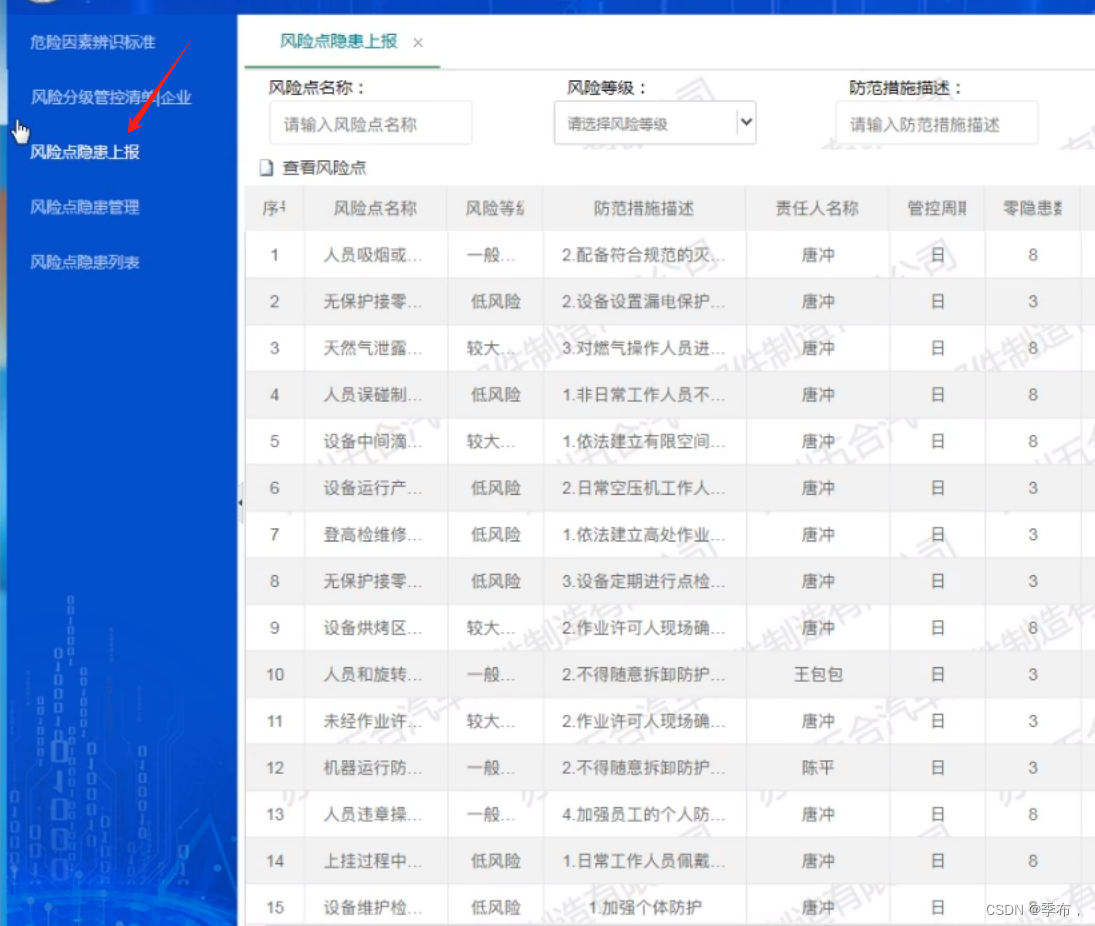
# 点击 风险点隐患上报
driver.implicitly_wait(5)
xpth = driver.find_element_by_xpath("//div[@data-tid='e9c7735c77284173a243f8e47999ee8d']")
xpth.click()
time.sleep(2)
print('已点击【风险点隐患上报】\n')

注意:可能点击 “风险点隐患上报” 右边页面是异步加载的找不到对应的文本按钮
# 重定向页面,确保操作的是当前窗口页面内容
driver.switch_to.default_content()
frame = driver.find_elements_by_tag_name('iframe')[0]
driver.switch_to.frame(frame)
time.sleep(1)
完整代码
# 导入相关库和模块
from selenium import webdriver
import time
# 指定账户名和密码登录
def login():
# 随机点一下 ,以便显示登录页面
driver.find_element_by_id('bodyMain').click()
# id=“username”是打开的网址中,账号登录的输入框,输入字符串“用户名”
username = input('请输入你的用户名:')
password = input('请输入你的密码:')
print('登录中……')
driver.find_element_by_id('username').send_keys(username)
driver.find_element_by_id('password').send_keys(password)
# id="submit"是点击登录, click() 是模拟点击
driver.find_element_by_id("submit").click()
time.sleep(2)
print('登录成功\n')
# 免输入密码和账户名登录
def vip_login():
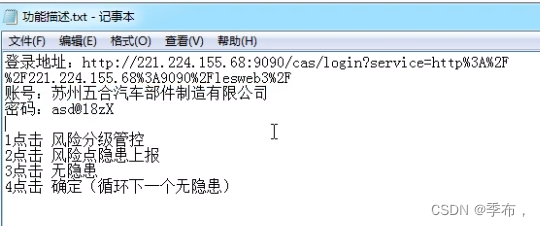
# 苏州五合汽车部件制造有限公司
# 张家港市友成高新材料有限公司
print('这是vip直接登录模式(免输户名和密码),登录中……')
driver.find_element_by_id('bodyMain').click()
driver.find_element_by_id('username').send_keys('苏州五合汽车部件制造有限公司')
driver.find_element_by_id('password').send_keys('ghj@18zXX')
driver.find_element_by_id("submit").click()
time.sleep(2)
print('vip免输入模式,登录成功!\n')
# 到达要处理的页面
def to_page():
# 点击 风险分级管控
driver.implicitly_wait(5)
risk_grade_control = driver.find_element_by_link_text("风险分级管控")
risk_grade_control.click()
time.sleep(2)
print('已点击【风险分级管】\n')
# 点击 风险点隐患上报
driver.implicitly_wait(5)
xpth = driver.find_element_by_xpath("//div[@data-tid='e9c7735c77284173a243f8e47999ee8d']")
xpth.click()
time.sleep(2)
print('已点击【风险点隐患上报】\n')
# 重定向页面,确保操作的是当前窗口页面内容
driver.switch_to.default_content()
frame = driver.find_elements_by_tag_name('iframe')[0]
driver.switch_to.frame(frame)
time.sleep(1)
# 点击 无隐患,处理一个页面
def deal_one_page(index=0):
time.sleep(2)
print()
print(30 * '-')
print()
for i in range(20):
if index == totals // 20 and i == totals % 20:
print(f'总共{20 * index + i}条,已经全部点击完成!')
driver.close()
break
print(f'第{20 * index + i + 1}条开始点击处理……')
if i == 0:
driver.find_elements_by_partial_link_text('无隐患')[i].click()
driver.find_elements_by_partial_link_text('无隐患')[i].click()
print('等待弹窗出现,并准备点击【确定】……')
time.sleep(2)
try:
driver.implicitly_wait(5) # seconds
elem_yes = driver.find_element_by_partial_link_text('确定')
elem_yes.click()
except:
print('稍等,正在处理……') # 再次重点击‘无隐患’
driver.find_elements_by_partial_link_text('无隐患')[i].click()
time.sleep(3) # 之前5秒合适
driver.implicitly_wait(5) # seconds
elem_yes = driver.find_element_by_partial_link_text('确定')
elem_yes.click()
print('已经点击【确定】,弹窗正在退出……')
print(f'第{20 * index + i + 1}条无隐患已经上报!')
print()
print(30 * '-')
print()
time.sleep(1)
# 点击 无隐患,翻页并处理全部页面
def deal_all_page(totals):
for index in range(totals // 20 + 1):
time.sleep(3)
deal_one_page(index)
print()
print(f'-----第{index + 1}页已经完成-----')
print(f'--------------------------------')
print()
try:
driver.find_element_by_id('mini-25').click()
except:
driver.find_element_by_id('mini-25').click()
time.sleep(2)
def get_totals():
driver.implicitly_wait(10) # seconds
driver.find_element_by_id('mini-26').click()
driver.implicitly_wait(10)
end_page_elem = driver.find_elements_by_xpath(".//span[@class='mini-pager-index']/span")[0]
end_page = end_page_elem.text.strip('/')
time.sleep(3)
end_page_count = driver.find_elements_by_partial_link_text('无隐患')
totals = (int(end_page) - 1) * 20 + len(end_page_count)
print(f'一共{totals}条记录待点击处理')
driver.implicitly_wait(10) # seconds
driver.find_element_by_id('mini-23').click()
time.sleep(3)
return totals
def main():
# vip_login()
login()
to_page()
time.sleep(3)
global totals
totals = get_totals()
deal_all_page(totals)
if __name__ == "__main__":
totals = None
# 调用环境变量指定的 Chrome 浏览器创建浏览器对象
driver = webdriver.Chrome()
# get 方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择
print('正在启动网页自动化办公程序……\n')
time.sleep(2)
driver.get("http://221.224.155.68:9090/cas/login?service=http%3A%2F%2F221.224.155.68%3A9090%2Flesweb3%2F")
print('正在打开目标网站……\n')
time.sleep(2)
main()
















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











