









有相关需求可以添加微信 ydw2755,可代 Hadoop集群搭建/MapReduce程序开发/数据大屏项目/IDEA远程运行MapReduce/Hadoop相关问题等
| 主机 | IP | 节点情况 |
|---|---|---|
| hadoop1 | 192.168.31.108 | 主节点 |
| hadoop2 | 192.168.31.109 | 子节点 |
| hadoop3 | 192.168.31.110 | 子节点 |
| 软件 | 版本 |
|---|---|
| CentOS 虚拟机 | 7.x |
| JDK | 1.8 |
| Hadoop | 3.1.3 |
网络配置
选择桥接网络
编辑网卡
cd /etc/sysconfig/network-scripts
vi ifcfg-eno16777736
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
IPV6_AUTOCONF=no
IPV6_DEFROUTE=no
IPV6_PEERDNS=no
IPV6_PEERROUTES=no
IPV6_FAILURE_FATAL=no
NAME=eno16777736
UUID=b3229a81-000a-4b8a-b6b8-c296f9519bde
DEVICE=eno16777736
ONBOOT=yes
IPADDR=192.168.31.108
NETMASK=255.255.255.0
GATEWAY=192.168.31.1
DNS=192.168.31.1
| IPADDR | 静态 IP,和 windows 主机同一个网段 |
|---|---|
| NETMASK | 子网掩码 |
| GATEWAY | 网关 |
| DNS | DNS 服务 |

重启网络
service network restart
ping 主机和百度试下有无问题
ping 192.168.31.13
ping www.baidu.com
桥接模式可省略```bash
vi /etc/resolv.conf
```bash
nameserver 8.8.8.8
nameserver 8.8.4.4
前置环境
JDK
sudo yum update -y
卸载原 JDK,如果存在```bash
rpm -qa|grep java
然后通过 rpm -e --nodeps 后面跟系统自带的jdk名 这个命令来删除系统自带的jdk
```bash
rpm -e --nodeps java-版本开头的
yum -y install java-1.8.0-openjdk-devel.x86_64
修改主机名
vi /etc/hostname
hadoop1
主机 IP 映射
vi /etc/hosts
192.168.31.108 hadoop1
192.168.31.109 hadoop2
192.168.31.110 hadoop3
克隆两个虚拟机出来
创建完整性克隆
网络配置
uuidgen ens33
vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
hadoop2
......同hadoop1配置
UUID=换成上面生成的UUID
DEVICE=eno16777736
ONBOOT=yes
IPADDR=192.168.31.109
NETMASK=255.255.255.0
GATEWAY=192.168.31.1
DNS=192.168.31.1
hadoop3
......同hadoop1配置
UUID=换成上面生成的UUID
DEVICE=eno16777736
ONBOOT=yes
IPADDR=192.168.31.110
NETMASK=255.255.255.0
GATEWAY=192.168.31.1
DNS=192.168.31.1
重启网络
service network restart
nmcli connection show
修改主机名
hadoop2 和 hadoop3 主机名改成对应的
vi /etc/hostname
免密登录
hadoop1、hadoop2、hadoop3
rm -rf /root/.ssh
hadoop1、hadoop2、hadoop3,一路回车
ssh-keygen -t rsa
hadoop1、hadoop2、hadoop3
cd /root/.ssh
hadoop1
mv id_rsa.pub id_rsa1.pub
hadoop2
mv id_rsa.pub id_rsa2.pub
hadoop3
mv id_rsa.pub id_rsa3.pub
hadoop1
scp id_rsa1.pub root@hadoop2:/root/.ssh/ && scp id_rsa1.pub root@hadoop3:/root/.ssh/
hadoop2
scp id_rsa2.pub root@hadoop1:/root/.ssh/ && scp id_rsa2.pub root@hadoop3:/root/.ssh/
hadoop3
scp id_rsa3.pub root@hadoop1:/root/.ssh/ && scp id_rsa3.pub root@hadoop2:/root/.ssh/
hadoop1、hadoop2、hadoop3
rm /root/.ssh/authorized_keys
hadoop1、hadoop2、hadoop3
cat id_rsa1.pub id_rsa2.pub id_rsa3.pub >> authorized_keys
hadoop 安装配置
以下操作都在 hadoop1 主节点执行
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
放到 home 目录下
cd /home && tar -zxvf hadoop-3.1.3.tar.gz
环境变量配置
echo "" >> /etc/profile && \
echo 'export HADOOP_PATH=/home/hadoop-3.1.3' >> /etc/profile && \
echo 'export PATH=$PATH:$HADOOP_PATH/bin:$HADOOP_PATH/sbin' >> /etc/profile
source /etc/profile
hadoop 环境配置
vi /home/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
加入下面配置
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
查看 hadoop 是否配置成功,显示版本
hadoop version

cd /home/hadoop-3.1.3/etc/hadoop
配置文件
core-site.xml
<!-- hadoop的核心配置文件 -->
<configuration>
<property>
<!-- 指定namenode(主节点)在hadoop1虚拟机上 -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<!-- 块大小 -->
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<!-- hadoop的临时目录 -->
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
hdfs-site.xml
<!-- 配置datanode(子节点)进程 -->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<!-- 指定HDFS副本的数量(一般几个子节点就设置为几个) -->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
</configuration>
mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<!-- MapReduce的核心配置文件,指定MapReduce的运行框架为YARN -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
# Hadoop的安装目录
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop-3.1.3</value>
</property>
</configuration>
** yarn-site.xm**
<configuration>
<!-- 指定YARN集群的管理者(ResourceManager)的地址 -->
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
<property>
<!-- NodeManager的附属服务 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
配置节点
echo 'hadoop1' >> masters
echo 'hadoop2' >> slaves && echo 'hadoop3' >> slaves
vi workers
加入下面内容
hadoop1
hadoop2
hadoop3
scp -r /home/hadoop-3.1.3 root@hadoop2:/home/
scp -r /home/hadoop-3.1.3 root@hadoop3:/home/
启动
创建目录
hadoop1 和上面配置文件里配置的目录一致
mkdir -p /usr/hadoop/tmp && \
mkdir -p /usr/hadoop/dfs/name && \
mkdir -p /usr/hadoop/dfs/data
hadoop1
scp -r /usr/hadoop/ hadoop2:/usr/
scp -r /usr/hadoop/ hadoop3:/usr/
格式化
hadoop namenode -format
启动
cd /home/hadoop-3.1.3/sbin
start-all.sh
授权
hadoop fs -chmod -R 777 /
查看节点
hdfs dfsadmin -report
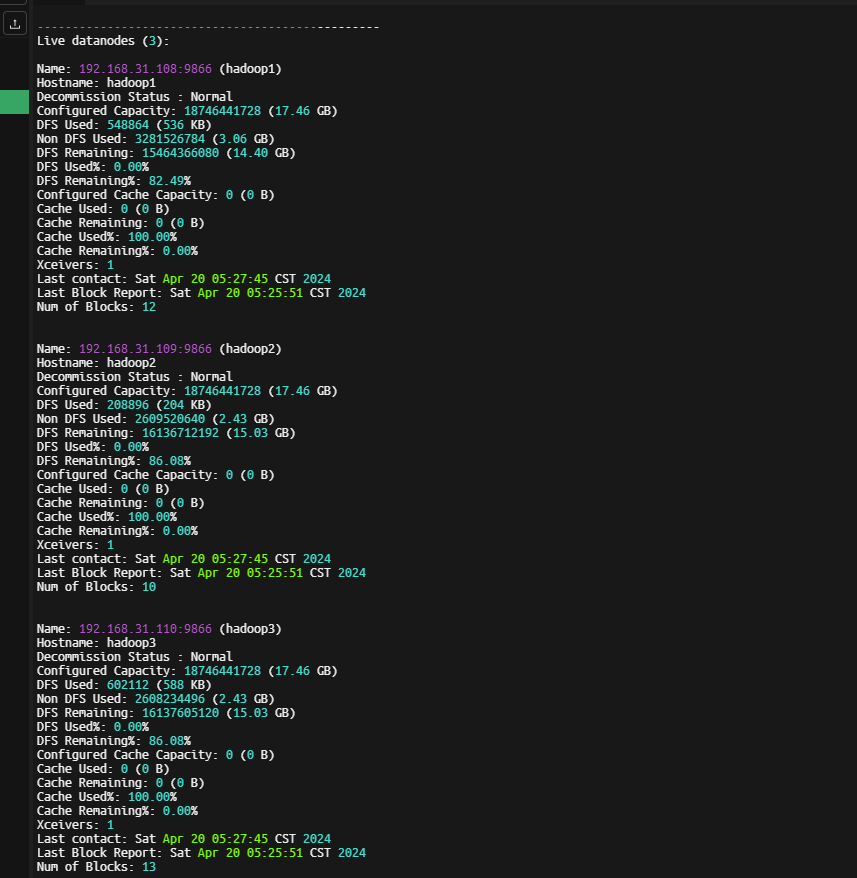
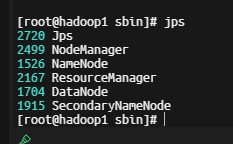
jps
访问
关闭防火墙
systemctl stop firewalld.service
windows 主机
C:\Windows\System32\drivers\etc
加入下面配置
192.168.31.108 hadoop1
192.168.31.109 hadoop2
192.168.31.110 hadoop3
打开 cmd 输入下面命令,刷新 DNS
ipconfig /flushdns
启动失败后重新启动
rm -rf /usr/hadoop/tmp && rm -rf /usr/hadoop/dfs/name && rm -rf /usr/hadoop/dfs/data && \
rm -rf /home/hadoop-3.1.3/logs
mkdir -p /usr/hadoop/tmp && \
mkdir -p /usr/hadoop/dfs/name && \
mkdir -p /usr/hadoop/dfs/data
hdfs dfsadmin -refreshNodes
hadoop namenode -format
HDFS
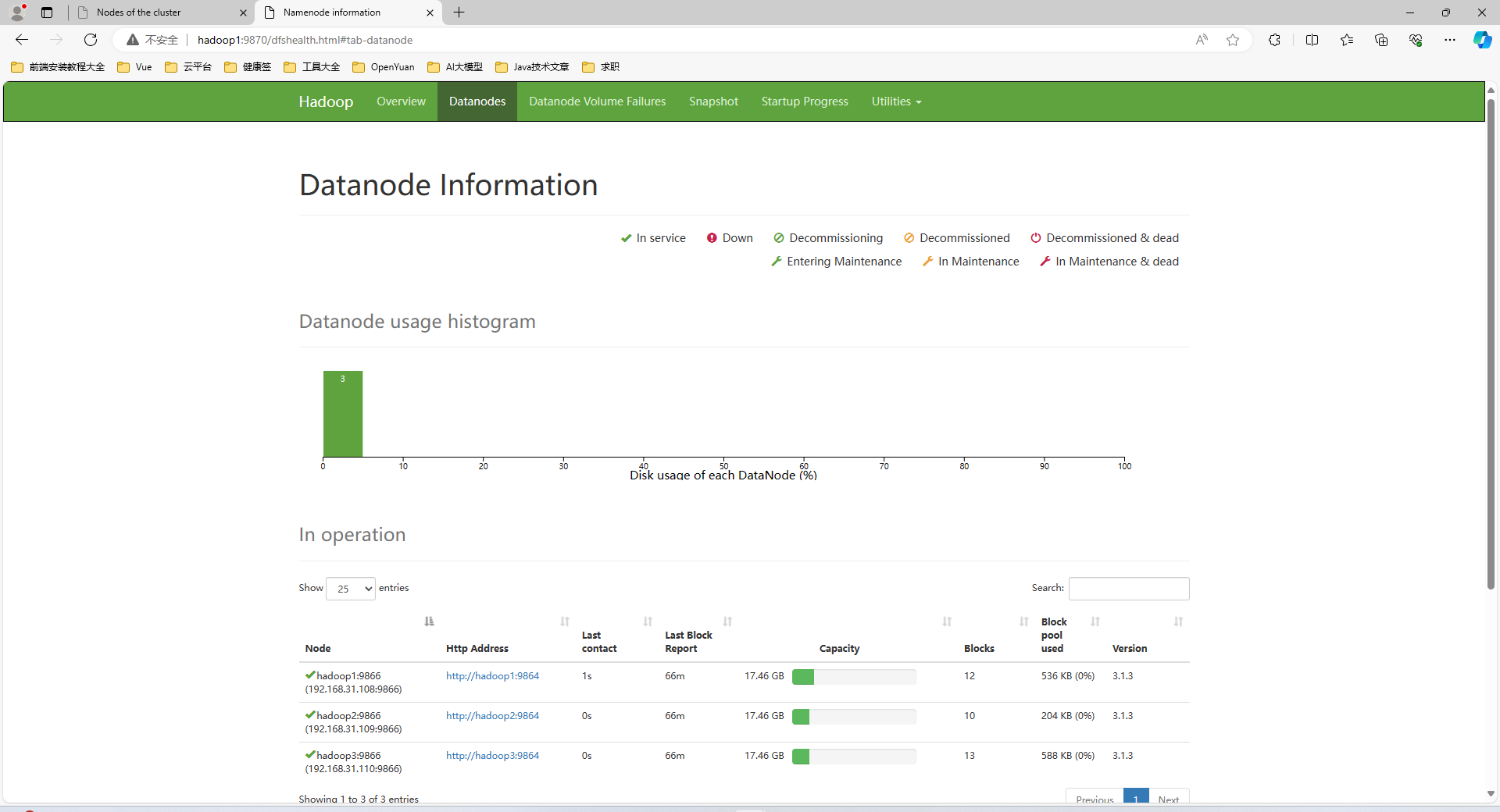
Yarn
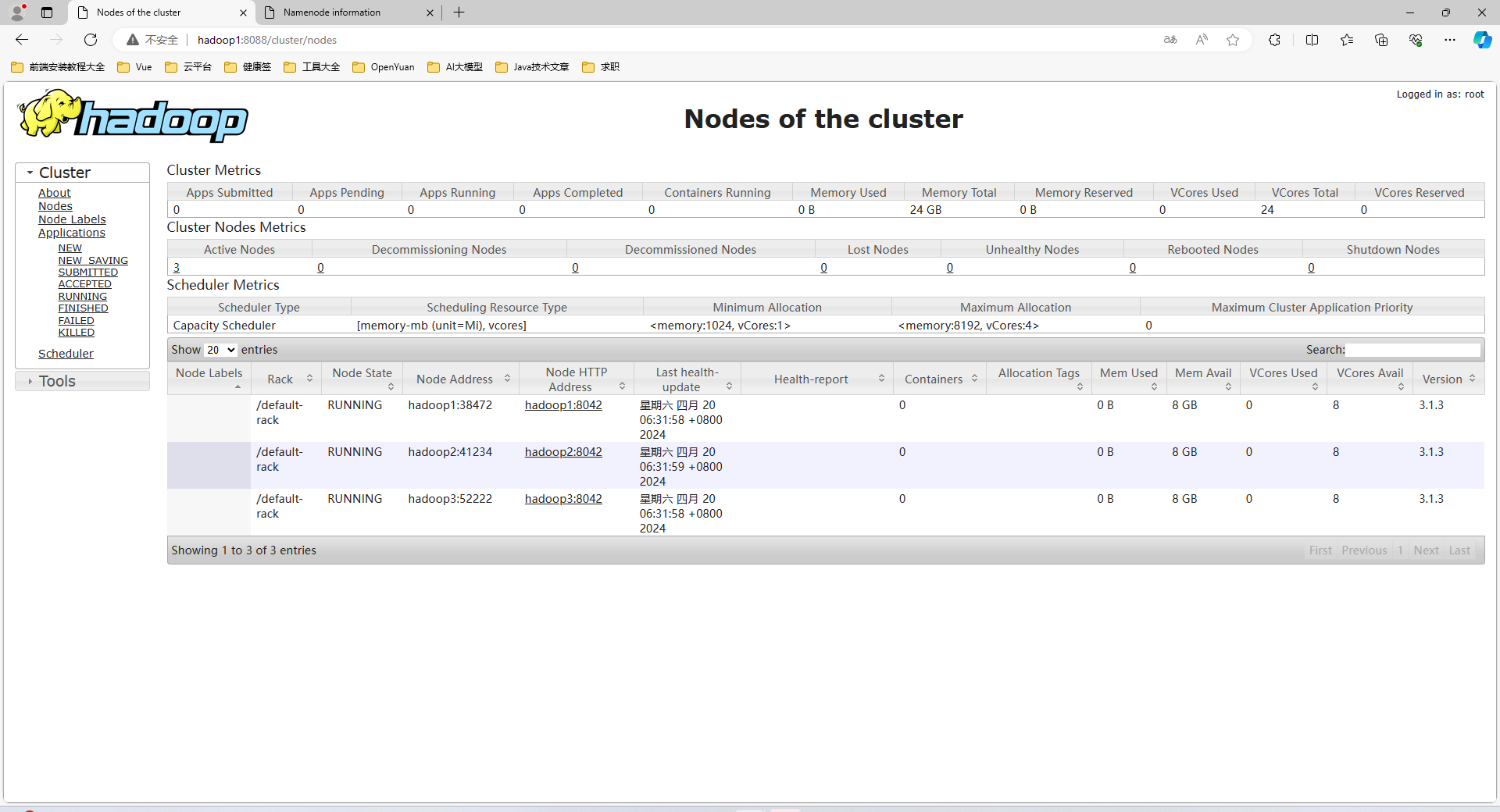
其他问题
权限问题
hadoop fs -chmod -R 777 /
移除安全模式
hadoop dfsadmin -safemode leave
格式化节点
hdfs dfsadmin -refreshNodes
启动失败重启
先删除文件
rm -rf /usr/hadoop/tmp && rm -rf /usr/hadoop/dfs/name && rm -rf /usr/hadoop/dfs/data
mkdir -p /usr/hadoop/tmp && \
mkdir -p /usr/hadoop/dfs/name && \
mkdir -p /usr/hadoop/dfs/data
hadoop namenode -format
再重新启动
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











