







数据库分布式核心内容无非就是数据切分(Sharding),以及切分后对数据的定位、整合。数据切分就是将数据分散存储到多个数据库中,使得单一数据库中的数据量变小,通过扩充主机的数量缓解单一数据库的性能问题,从而达到提升数据库操作性能的目的。
而划分又分为垂直划分和水平划分
垂直划分
垂直划分 又分为数据库垂直划分 和 表垂直划分
- 数据库垂直划分
指的是将一个库里面的表按逻辑进行划分、不同业务的表 被放到不同的主机上,垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。

- 表垂直划分:
指的是对表进行垂直划分,既按字段(列)进行划分,一般是将不经常访问、长度较大、访问较频繁的分出去。
内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能,分出去后单行数据变小、一个磁盘块所能存储的数据数目变多,效率提升!
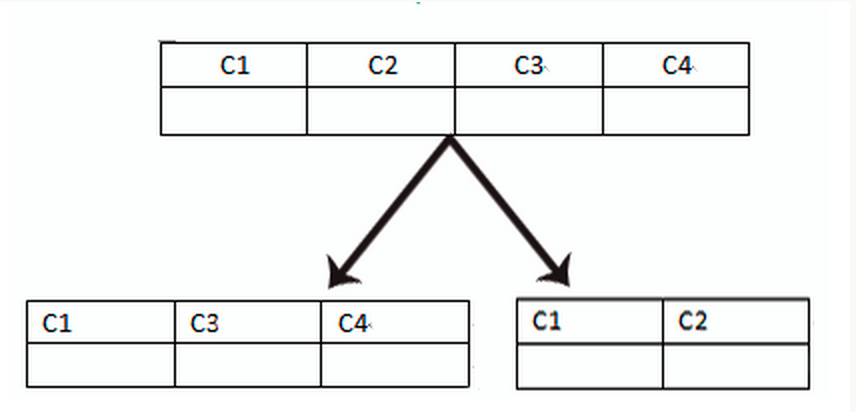
水平划分
垂直划分不能解决数据量过大的情况,于是用到了水平划分
水平划分可分为分库分表和库内分表
库内分表:
指的是将表按水平划分,但划分出的表还是在同一个数据库里面
分库分表:
指的是表按水平划分,并把表分散到不同的数据库里面,部署在不同主机上
库内分表只解决了单一表数据量过大的问题,但没有将表分布到不同机器的库上,因此对于减轻MySQL数据库的压力来说,帮助不是很大,大家还是竞争同一个物理机的CPU、内存、网络IO,最好通过分库分表来解决。
- 根据数值划分
很容易理解,就是按照范围去划分呗,例如id为1-100 db1;101-200 db2;....;
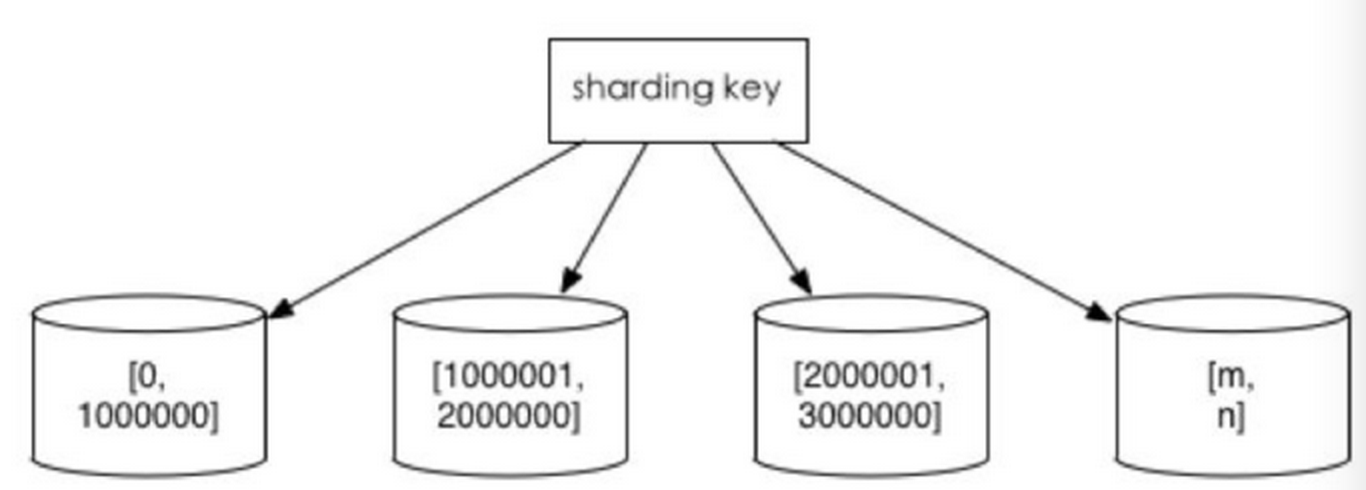
优点就是我可以很容易根据id去推算到我这个数据在哪个db中,也方便今后的扩展,比如我要多扩展一个表,那么这个表存储201-300的数据。
缺点就是,我有些数据访问比较频繁,有些不频繁,例如101-200经常访问,而201-300不经常访问,那这会导致不同主机压力分配不均匀,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询。
- 根据数值取模划分
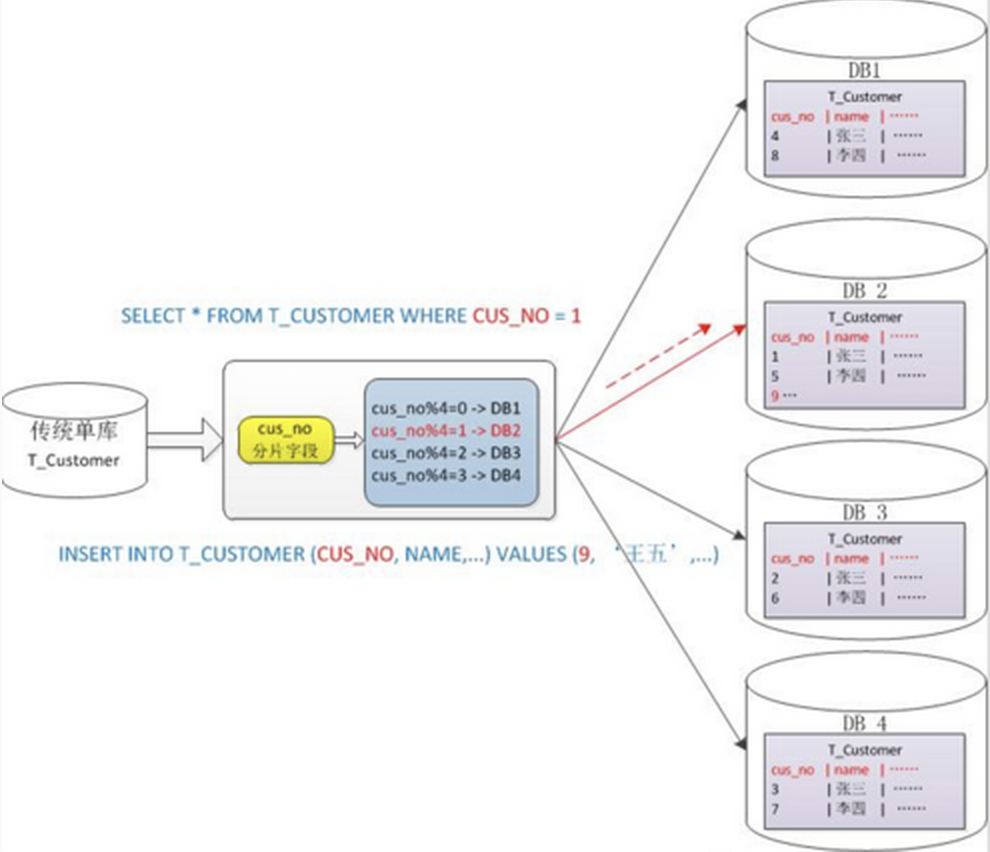
取模大家都会吧!,就是将某个字段例如 id 先取hash然后取模,相比于基于数值的,此方法可以让数据均匀分布,不会出现主机压力分配不均匀的情况。
缺点是:
- 后期分片集群扩容时,需要迁移旧的数据,也就是说我要新增主机的数量,那么我用的hash算法肯定要变化,导致的是一些数据要从一个主机转移到另一个主机(使用一致性hash算法能较好的避免这个问题)
什么是一致性hash算法,为什么其能便于拓展呢?

这就是一致性hash算法,可以看到我们将机器的序列id,以及对象的id序列化,然后投影到一个环状的空间(0-2^32-1),那么我们怎么看哪些对象分配在哪个机器上呢?原则是顺时针方法。
m4->t4 m3->t2,每个对象按照虚线箭头分配到相应的机器,那么如果要新增一个机器呢,大家可以看图,新增一个机器节点后,需要调整的机器只有两个,同理 删除机器节点,需要调整的也是两个。这就方便我们今后对机器进行拓展!
- 容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带cusno时,将会导致无法定位数据库,从而需要同时向4个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累
















 974
974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











