







数据驱动的思想在于参数与参数名的对应关系,一对一,多对多,然后对数据进行拆分
1、首先我们分析一下unittest的DDT数据驱动:
第一步,导包这里要用到ddt,data,unpack
先讲一下unpack的作用就是拆分,要不然数据就是一个整体
from ddt import ddt, data, unpack
注意看清楚@data里面的内容:
{‘name’: ‘1’,‘password’:‘111’},
{‘name’: ‘2’,‘password’:‘222’}
@data({'name': '1','password':'111'},{'name': '2','password':'222'})
@unpack
def test_01(self,name,password):
print(name)
print(password)
此时这是两个单字典,这个时候要注意参数名要和字典的键值对应来读取,此时结果应该为
1
111
2
222
注意这是如果@data变成了
@data([{‘name’: ‘1’,‘password’:‘111’},{‘name’: ‘2’,‘password’:‘222’}])
多了列表嵌套
@data([{'name': '1','password':'111'},{'name': '2','password':'222'}])
def test_01(self,name,password):
print(name)
print(password)
如果还是和之前一样读取的话结果就变成了
{'name': '1', 'password': '111'}
{'name': '2', 'password': '222'}
这样就不好搞了,他就是一个单列表了不能再拆分就失去了参数化的效果
接着看后面有字典形式怎么操作。
参数化总不能手写吧,肯定要读取文件
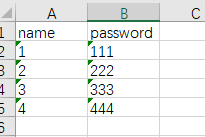
搞一个execl文件
def ReadExecl(self,filename):
path=os.path.abspath('..')+'/'+'data'+'/'+filename+'.xlsx'
work=xlrd.open_workbook(path)
sheet=work.sheet_by_name('Sheet1')
nrows=sheet.nrows
dataList=[]
for rows in range(nrows):
data=sheet.row_values(rows)
dataList.append(data)
# 第一行是标题
title=dataList[0]
data=dataList[1:]
return data
这是搞成了列表形式
[['1','111'],['2','222'],['3','333']]
如何引入呢?这里*表示所有数据
@data(*Read().ReadExecl('data_execl'))
@unpack
def test_01(self,name,password):
print(name,password)
如果写文件读取的时候不小心搞成了字典形式呢?
def ReadExecl1(self,filename):
path=os.path.abspath('..')+'/'+'data'+'/'+filename+'.xlsx'
work=xlrd.open_workbook(path)
sheet=work.sheet_by_name('Sheet1')
nrows=sheet.nrows
dataList=[]
for rows in range(nrows):
data=sheet.row_values(rows)
dataList.append(data)
# 第一行是标题
title=dataList[0]
datas=dataList[1:]
new=[]
for data in datas:
dic={}
for i in range(len(data)):
dic[title[i]]=data[i]
new.append(dic)
return new
上面是写成字典形式
[{'name': '1', 'password': '111'}, {'name': '2', 'password': '222'}, {'name': '3', 'password': '333'}, {'name': '4', 'password': '444'}]
这个时候就不能用unpack了因为已经只是一个列表了
@data(*Read().ReadExecl1('data_execl'))
def test_01(self,name):
print(name['name'],name['password'])
二、pytest参数化
pytest参数化的话自带方法
@pytest.mark.parametrize(‘参数名’,[参数])
两个参数的话
@pytest.mark.parametrze('参数名1,参数名2',[['1','111'],['2','222'])
#Read().ReadExecl('data_execl')=
# [['1', '111'], ['2', '222'], ['3', '333'], ['4', '444']]
@pytest.mark.parametrize('name,password',Read().ReadExecl('data_execl'))
def test_03(self,name,password):
print(name,password)
#Read().ReadExecl1('data_execl')=
#[{'name': '1', 'password': '111'}, {'name': '2', 'password': '222'}, {'name': '3', 'password': '333'}, {'name': '4', 'password': '444'}]
@pytest.mark.parametrize('name',Read().ReadExecl1('data_execl'))
def test_03(self,name):
print(name['name'],name['password'])
数据驱动主要还是数据文件的读取的问题,给他处理成相应的格式,然后记住一对一原则多对多原则就不难了
@pytest的参数一定要列表嵌套















 1891
1891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









