







存储过程
概念:
-
存储过程 (Stored Procedure) 是在大型数据库系统中 , 一组为了完成特定功能的SQL 语句集 .
-
存储在数据库中 , 经过第一次编译后再次调用不需要再次编译 , 用户通过指定存储过程的名字并给出参数 (如果该存储过程带有参数) 来执行它.
-
存储过程是数据库中的一个重要对象 ; 存储过程中可以包含 逻辑控制语句 和 数据操纵语句
-
它可以接受参数 , 输出参数 ,返回单个或多个结果集以及返回值 ;
存储过程的优点:
- 执行速度快:
存储过程创建是就已经通过语法检查和性能优化,在执行时无需每次编译。存储在数据库服务器,性能高。 - 允许模块化设计:
只需创建存储过程一次并将其存储在数据库中,以后即可在程序中调用该过程任意次。存储过程可由在数据库编程方面有专长的人员创建,并可独立于程序源代码而单独修改 。 - 提高系统安全性:
可将存储过程作为用户存取数据的管道。可以限制用户对数据表的存取权限,建立特定的存储过程供用户使用,完成对数据的访问。 存储过程的定义文本可以被加密,使用户不能查看其内容。 - 减少网络流量:
一个需要数百行Transact-SQL代码的操作由一条执行过程代码的单独语句就可实现,而不需要在网络中发送数百行代码。
存储过程的缺点
- 存储过程会使得 数据库占用的系统资源加大(cpu、memory),数据库毕竟主要用来做数据存取的,并不进行复杂的业务逻辑操作。
- 因为存储过程依旧是sql,所以没办法像编程语言那样写出复杂业务逻辑对应的存储过程。
- 存储过程不容易进行调试。
- 存储过程书写及维护难度都比较大。
存储过程–语法:
结束标记:DELIMITER
- 在MySQL中,默认以分号; 为分隔符
- 在写存储过程、存储函数、触发器时,编译器会当做SQL语句来进行处理,编译过程会出现错误,所以要事先用”delimiter @”声明@(或者其他,由用户自己定义)为当前的段分隔符
DELIMITER 结束标记
DELIMITER $
创建一个存储过程
create procedure GetUsers()
begin
select * from user;
end;
参数列表
1、参数列表包括三部分 参数模式 参数名 参数类型
参数模式
- IN:该参数可以作为输入
- OUT:该参数可以作为输出
- INOUT:该参数既可以作为输入 也可以作为输出
2、如果存储过程体只有一句话,begin end 可以省略。
-
存储过程体中的每条sql语句的结尾要求必须加分号;
-
存储过程的结尾可以使用 DELIMITER 重新设置
调用存储过程
无参的
call GetUsers();
. 有参的
- 调用此存储过程 , 必须指定3个变量名,所有 MySql 变量都必须以@开始, 如下所示 :
call GetScores(@minScore, @avgScore, @maxScore);
- 该调用并没有任何输出 , 只是把调用的结果赋给了调用时传入的变量 @minScore, @avgScore, @maxScore , 然后即可调用显示该变量的值 :
select @minScore, @avgScore, @maxScore;
删除存储过程
drop procedure if exists GetUsers;
查看存储过程
show procedure status where db='数据库名';
案例:
空参列表
DELIMITER $
create procedure myp1()
begin
INSERT into stu(name,kecheng,fenshu)
values('a','a','a'),('b','b','b'),('c','c','c');
end $
#调用
call myp1() $
创建带in模式参数的存储过程
create procedure myp2(in beautyName varchar(20))
begin
select bo.*
from boys bo
right join beauty b on bo.id = b.id
where b.name = beautyName
end $
#调用
call myp2('aaa')$
创建out模式的存储过程
案例一;

DELIMITER $
CREATE PROCEDURE myp8(IN name1 VARCHAR(20),OUT fenshu VARCHAR(20))
BEGIN
SELECT stu.fenshu INTO fenshu
FROM stu
WHERE stu.name = name1;
END $
CALL myp8('tom',@fenshu)$
SELECT @fenshu $

案例二;
create procedure myp5(in beautyName varchar(20),out boyname varchar(20))
begin
select bo.boyname into boyname
from boys bo
inner join beauty b on bo.id = b.boyname
where b.name = beautyName
end $
调用
set @bName$
call myp5('a',@bName)$
select @bName $
2.返回多个out
create procedure myp6(in beautyName varchar(20),out boyname varchar(20),out userCp int)
begin
select bo.boyname,bo.userCP into boyname,userCp
from boys bo
inner join beauty b on bo.id = b.boyname
where b.name = beautyName
end $
调用
call myp6('a',@bName,@userCp)$
inout 模式参数的存储过程
create procedure myp7(inout a int,inout b int)
begin
set a= a*2;
set b= b*2;
end $
调用
set @m=10$;
set @n=20$;
call myp7(@m,@n)$
select @m,@n
定义变量
-
如果希望MySQL执行批量插入的操作,那么至少要有一个计数器来计算当前插入的是第几次。
-
这里的变量是用在存储过程中的SQL语句中的,变量的作用范围在BEGIN … END 中。
-
没有DEFAULT子句,初始值为NULL。
定义变量的操作 :DECLARE
DECLARE name,address VARCHAR; -- 发现了吗,SQL中一般都喜欢先定义变量再定义类型,与Java是相反的。
DECLARE age INT DEFAULT 20; -- 指定默认值。若没有DEFAULT子句,初始值为NULL。
为变量赋值
SET name = 'jay'; -- 为name变量设置值
DECLARE var1,var2,var3 INT;
SET var1 = 10,var2 = 20; -- 其实为了简化记忆其语法,可以分开来写
-- SET var1 = 10;
-- SET var2 = 20;
SET var3 = var1 + var2;
案例:
如下表,在做了去除主键约束后,我又添加了一条id=1的数据。现在希望查询出id为1的记录的数量。
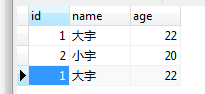
DROP PROCEDURE IF EXISTS contStById;
DELIMITER // -- 定义存储过程结束符号为//
CREATE PROCEDURE contStById(IN sid INT(11),OUT result INT(11)) -- 定义输入变量
BEGIN
DECLARE sCount INT;
SELECT COUNT(*) INTO sCount FROM t_student WHERE id = sid;
SET result = sCount; -- 用变量为输出结果设值
END // -- 结束符要加
DELIMITER ; -- 重新定义存储过程结束符为分号
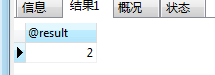
CALL contStById(1,@result);
SELECT @result;
存储函数 (自定义函数)
- 存储函数与存储过程本质上是一样的,都是封装一系列SQL语句,简化调用。
- 有且仅有一个 返回值
语法:
创建:
CREATE FUNCTION func_name ([param_name type[,...]])
RETURNS type
[characteristic ...]
BEGIN
routine_body
END;
参数说明:
- func_name :存储函数的名称。
- param_name type:可选项,指定存储函数的参数。type参数用于指定存储函数的参数类型,该类型可以是MySQL数据库中所有支持的类型。
- RETURNS type:指定返回值的类型。必选
- characteristic:可选项,指定存储函数的特性。
- routine_body:SQL代码内容。
调用存储函数:
- 在MySQL中,存储函数的使用方法与MySQL内部函数的使用方法基本相同。用户自定义的存储函数与MySQL内部函数性质相同。区别在于,存储函数是用户自定义的。而内部函数由MySQL自带。其语法结构如下:
SELECT func_name([parameter[,…]]);
修改存储函数
- MySQL中,通过ALTER FUNCTION 语句来修改存储函数,其语法格式如下:
ALTER FUNCTION func_name [characteristic ...]
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
上面这个语法结构是MySQL官方给出的,修改的内容可以包含SQL语句也可以不包含,既可以是读数据的SQL也可以是修改数据的SQL还有权限。此外在修改function的时候还需要注意你不能使用这个语句来修改函数的参数以及函数体,如果你想改变这些的话你就需要删除掉这个函数然后重新创建
插看存储函数:
SHOW FUNCTION status
删除存储函数:
MySQL中使用DROP FUNCTION语句来删除存储函数。
DROP FUNCTION IF EXISTS func_user;
案例:
创建存储函数,实现根据用户编号,获取用户姓名功能。
- 先创建tb_user(用户信息表),并添加数据。
-- 创建用户信息表
CREATE TABLE IF NOT EXISTS tb_user
(
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '用户编号',
name VARCHAR(50) NOT NULL COMMENT '用户姓名'
) COMMENT = '用户信息表';
-- 添加数据
INSERT INTO tb_user(name) VALUES('pan_junbiao的博客');
INSERT INTO tb_user(name) VALUES('KevinPan');
INSERT INTO tb_user(name) VALUES('pan_junbiao');
INSERT INTO tb_user(name) VALUES('阿标');
INSERT INTO tb_user(name) VALUES('panjunbiao');
INSERT INTO tb_user(name) VALUES('pan_junbiao的CSDN博客');
INSERT INTO tb_user(name) VALUES('https://blog.csdn.net/pan_junbiao');

2. 创建存储函数
-- 创建存储函数
DELIMITER $
DROP FUNCTION IF EXISTS func_user;
CREATE FUNCTION func_user(in_id INT)
RETURNS VARCHAR(50)
BEGIN
DECLARE out_name VARCHAR(50);
SELECT NAME INTO out_name FROM tb_user
WHERE id = in_id;
RETURN out_name;
END $;
3. 调用存储函数
-- 调用存储函数
SELECT func_user(1);
SELECT func_user(2);
SELECT func_user(3);
SELECT func_user(4);
SELECT func_user(5);
SELECT func_user(6);
SELECT func_user(7);


存储过程、存储函数和触发器的对比:
(1)基本区别:

存储过程:
优点:
-
有if/else,case,while等控制语句,通过编写存储过程,可以实现一些逻辑比较复杂的功能;
-
模块化;对一些功能进行了封装,代码的复用;
-
响应速度快,只有在首次执行时需要经过编译和优化步骤,后被调用直接执行,省去了重新编写代码计算的步骤。
-
减少网络传输。存储过程直接就在数据库服务器上跑,所有的数据访问都在服务器内部进行,不需要传输数据到其它终端。
-
方便DBA优化。所有的SQL集中在一个地方
缺点:
- 复杂的业务逻辑。没办法应用缓存。
触发器
优点:
- 安全。可以基于数据库的值使用户具有操作数据库的某种权利。可以跟踪用户对数据库的操作。
- 触发器能够拒绝或回退那些破坏相关完整性的变化,取消试图进行数据更新的事务。当插入一个与其主健不匹配的外部键时,这种触发器会起作用。
缺点:
- 数据集数据量又较大时,触发器效果会非常低(因为自动计算数据值,需要变动整个数据集导致效率下降)
- 对于批量操作并不适合使用触发器,使用触发器实现的业务逻辑在出现问题时很难进行定位。
(2) 注意事项:
在MySQL中,默认以分号为分隔符,在写存储过程、存储函数、触发器时,编译器会当做SQL语句来进行处理,编译过程会出现错误,所以要事先用”delimiter @”声明@(或者其他,由用户自己定义)为当前的段分隔符,让编译器把两个@之间的内容当做存储过程、存储函数、触发器的代码,在写完整个内容完之后再”delimiter ;”将分隔符还原。















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









