







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
缓存穿透
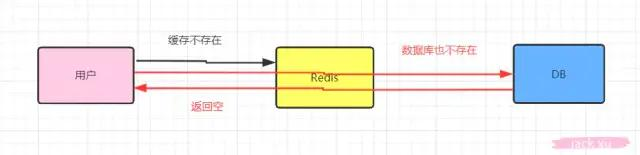
- 大家看下这幅图,用户可能进行了一次条件错误的查询,这时候redis是不存在的,按照常规流程就是去数据库找了,可是这是一次错误的条件查询,数据库当然也不会存在,也不会往redis里面写值,返回给用户一个空,这样的操作一次两次还好,可是次数多了还了得,我放redis本来就是为了挡一挡,减轻数据库的压力,现在redis变成了形同虚设,每次还是去数据库查找了,这个就叫做缓存穿透,相当于redis不存在了,被击穿了,
- 我们可以在redis缓存一个空字符串或者特殊字符串,比如&&,下次我们去redis中查询的时候,当取到的值是空或者&&,我们就知道这个值在数据库中是没有的,就不会在去数据库中查询,ps:这里缓存不存在key的时候一定要设置过期时间,不然当数据库已经新增了这一条记录的时候,这样会导致缓存和数据库不一致的情况
- 上面这个是重复查询同一个不存在的值的情况,如果应用每次查询的不存在的值是不一样的呢?即使你每次都缓存特殊字符串也没用,因为它的值不一样,比如我们的数据库用户id是111,112,113,114依次递增,但是别人要攻击你,故意拿-100,-936,-545这种乱七八糟的key来查询,这时候redis和数据库这种值都是不存在的,人家每次拿的key也不一样,你就算缓存了也没用,这时候数据库的压力是相当大,比上面这种情况可怕的多,怎么办呢,这时候我们今天的主角布隆过滤器就登场了。
经典面试题
问:如何在海量元素中(例如 10 亿无序、不定长、不重复)快速判断一个元素是否存在?
放入集合
- 最简单的想法就是把这么多数据放到数据结构里去,比如List、Map、Tree,一搜不就出来了吗,比如map.get(),我们假设一个元素1个字节的字段,10亿的数据大概需要 900G的内存空间,这个对于普通的服务器来说是承受不了的,当然面试官也不希望听到你这个答案,因为太笨了吧,我们肯定是要用一种好的方法,巧妙的方法来解决
位图
- 这里引入一种节省空间的数据结构,位图,他是一个有序的数组,只有两个值,0 和 1。0代表不存在,1代表存在。

- 现在我们还需要一个映射关系,你总得知道某个元素在哪个位置上吧,然后在去看这个位置上是0还是1,怎么解决这个问题呢,那就要用到哈希函数,
哈希函数
- 用哈希函数有两个好处,第一是哈希函数无论输入值的长度是多少,得到的输出值长度是固定的,
- 第二是他的分布是均匀的,如果全挤的一块去那还怎么区分,比如MD5、SHA-1这些就是常见的哈希算法。

哈希冲突
- 我们通过哈希函数计算以后就可以到相应的位置去找是否存在了,我们看红色的线,24和147经过哈希函数得到的哈希值是一样的,我们把这种情况叫做哈希冲突或者哈希碰撞
降低哈希碰撞的概率
哈希碰撞是不可避免的,我们能做的就是降低哈希碰撞的概率.
- 第一种是可以扩大维数组的长度或者说位图容量,因为我们的函数是分布均匀的,所以位图容量越大,在同一个位置发生哈希碰撞的概率就越小。但是越大的位图容量,意味着越多的内存消耗,所以我们想想能不能通过其他的方式来解决
- 第二种方式就是经过多几个哈希函数的计算,你想啊,24和147现在经过一次计算就碰撞了,那我经过5次,10次,100次计算还能碰撞的话那真的是缘分了,你们可以在一起了,但也不是越多次哈希函数计算越好,因为这样很快就会填满位图,而且计算也是需要消耗时间,所以我们需要在时间和空间上寻求一个平衡
布隆过滤器
背景:
- 在 1970年的时候,有一个叫做布隆的前辈对于判断海量元素中元素是否存在的问题进行了研究,也就是到底需要多大的位图容量和多少个哈希函数,它发表了一篇论文,提出的这个容器就叫做布隆过滤器。
原理分析:

判断是否存在
- 大家来看下这个图,我们看集合里面3个元素,现在我们要存了,比如说a,经过f1(a),f2(a),f3(a)经过三个哈希函数的计算,在相应的位置上存入1,元素b,c也是通过这三个函数计算放入相应的位置。当取的时候,元素a通过f1(a)函数计算,发现这个位置上是1,没问题,第二个位置也是1,第三个位置上也是1,这时候我们说这个a在布隆过滤器中是存在的,没毛病.
假阳性
- 同理我们看下面的这个d,通过三次计算发现得到的结果也都是1,那么我们能说d在布隆过滤器中是存在的吗,显然是不行的,我们仔细看d得到的三个1其实是f1(a),f1(b),f2©存进去的,并不是d自己存进去的,这个还是哈希碰撞导致的,我们把这种本来不存在布隆过滤器中的元素误判为存在的情况叫做=假阳性(False Positive Probability,FPP)。
判断是否不存在
- 我们再来看另一个元素,e 元素。我们要判断它在容器里面是否存在,一样地要用这三个函数去计算。第一个位置是 1,第二个位置是1,第三个位置是0。那么e元素能不能判断是否在布隆过滤器中?答案是肯定的,e一定不存在。你想啊,如果e存在的话,他存进去的时候这三个位置都置为1,现在查出来有一个位置是0,证明他没存进去啊。
重要的结论
- 从容器的角度来说:
如果布隆过滤器判断不存在,则一定不存在
如果布隆过滤器判断元素在集合中存在,则不一定存在
布隆过滤器工作位置
- 第一步是将数据库所有的数据加载到布隆过滤器。
- 第二步当有请求来的时候先去布隆过滤器查询,如果bf说没有,
- 第三步直接返回。如果bf说有,在往下走之前的流程

布隆过滤器应用场景
- Redis实现布隆过滤器,避免缓存穿透
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- 网页爬虫对URL去重,避免爬取相同的 URL 地址;
- Google Chrome 使用布隆过滤器识别恶意 URL;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
- Google BigTable,Apache HBbase 和 Apache Cassandra使用布隆过滤器减少对不存在的行和列的查找。
布隆过滤器的优缺点
1、优点
- 相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。
- 另外, Hash函数相互之间没有关系,方便由硬件并行实现。
- 布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
- 布隆过滤器可以表示全集,其它任何数据结构都不能。
2、缺点
- 但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。常见的补救办法是建立一个小的白名单,存储那些可能被误判的元素。但是如果元素数量太少,则使用散列表足矣。
- 另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1. 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面.
这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。 - 在降低误算率方面,有不少工作,使得出现了很多布隆过滤器的变种。















 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









