







众所周知,Hadoop主要有三种运行模式
- 单机模式(服务器一台,数据由linux管理)
- 伪分布式模式(服务器一台,数据由HDFS管理)
- 完全分布式模式(服务器节点很多,数据分布在多台设备HDFS管理)
目前博主主要学习完全分布式模式。配置完全分布式的步骤如下:
我们这一章主要是进行文件的拷贝(因为只完成了一台客户机的环境配置)
1.scp介绍命令
可以实现服务器与服务器数据之间的拷贝
scp -r $pdir/$fname $user@host:$pdir/$fname
命令 递归 要拷贝的文件名/名称 目的地用户/主机:目的的路径/名称
2.拷贝文件
2.1我们将hadoop102上的文件拷贝到hadoop103上
scp -r jdk1.8.0_212/ liuc1997@hadoop103:/opt/modul/

然后叫你输入密码,就开始复制了。来hadoop103看一下,复制成功!
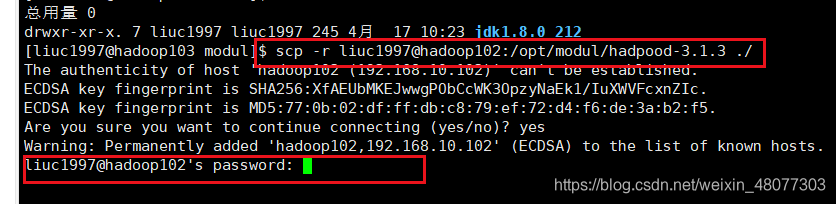
2.2 我们这次在hadoop103上将hadoop102上的文件拿过来
scp -r liuc1997@hadoop102:/opt/modul/hadoop-3.1.3 ./
然后就会叫你输入hadoop102的密码。
然后就会出现复制的进程,最后结束后查看一下:

没有问题。
2.3利用hadoop103将hadoop102的数据拷贝到hadoop104上
这是两个跟自己毫无关系的服务器也可以操控他们。
scp -r liuc1997@hadoop102:/opt/modul/* liuc1997@hadoop104:/opt/modul/
依次输入hadoop102和hadoop104的密码
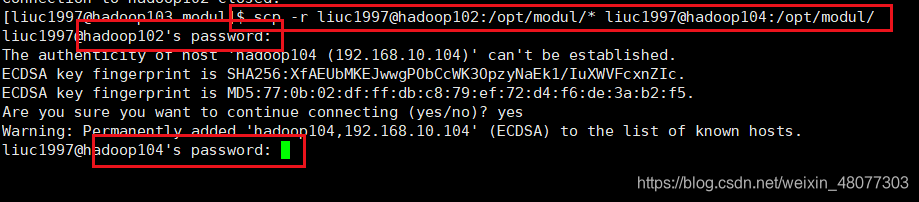
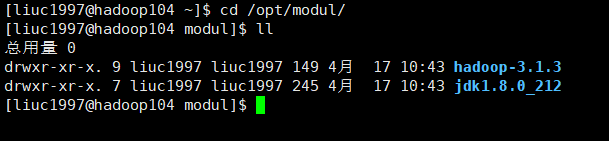
然后就开始了。来到hadoop104上看一下,复制成功。
2.rsync介绍命令
上面介绍的复制命令scp是指把整个文件夹都拷贝过来,而同步是指对两个文件的差异部分进行更新。 第一次同步等同于拷贝。
可以实现服务器与服务器数据之间的同步
rsync -av $pdir/$fname $user@host:$pdir/$fname
命令 显示复制过程 要同步的文件名/名称 目的地用户/主机:目的的路径/名称
2.1复制差异信息
我们在hadoop102的主机上hadoop-3.1.3文件下先创建一个文件hello.txt,然后将该文件复制给hadoop104,看看效果。
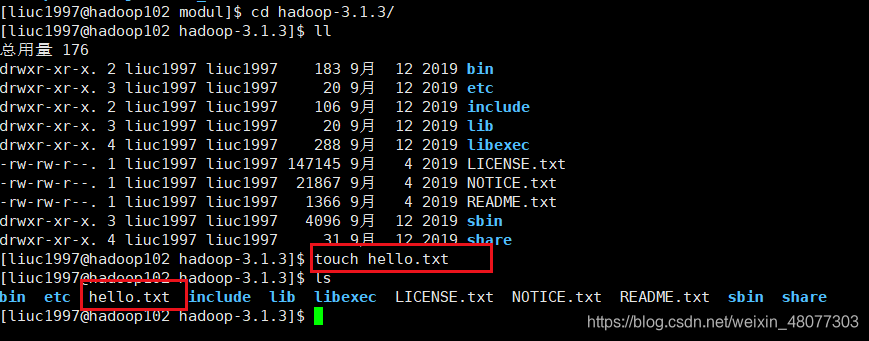
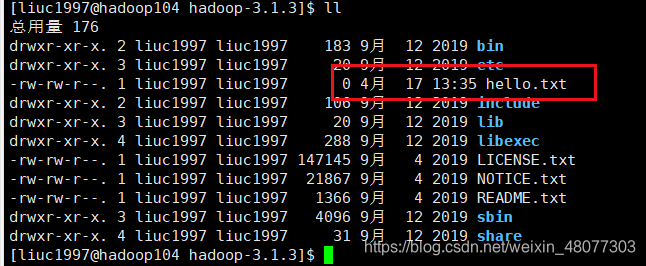
将更改后的文件复制给104主句
rsync -av hadoop-3.1.3/ liuc1997@hadoop104:/opt/modul/hadoop-3.1.3/
然后飞快的运行之后,在104的主机上就能看见这个文件。
2.2制作同步脚本
我们cd~到用户目录下,创建一个bin目录
cd ~
mkdir bin
cd bin
vim xsync
将下面内容粘过去,我们就创建了一个文件同步工具
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#遍历所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ___________________host_________________
#3.遍历所有目录,挨个发送
for file in $@
do
#4.判断文件是否存在
if [ -e $file ]
then
#5.获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#获取文件夹名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
然后我们cd ~ 输入
同步三台机器的bin目录
xsync bin/


















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











