







文章目录
一维数组
数组是由数据类型相同的一系列元素组成。
一维数组的创建和初始化
数组的创建
type_t arr_name[const_int_n];
float f[100]; // 含有100个float类型元素的数组。
char c[200]; // 含有200个char类型元素的数组。
int i[250]; // 含有250个int类型元素的数组。
type_t,表示数组内元素的数据类型。arr_name, 表示数组名。const_int_n,表示数组大小,必须是整型常量表达式。
变长数组
C99之前的标准前,创建数组时只能在方括号[]中使用整型常量表达式。注意:sizeof表达式被视为整型常量,#define定义的标识符常量也是常量,而const修饰的常变量在C语言中被视为具有常属性的变量。
在C99中引入了变长数组的概念,允许变量出现在[]。(前提编译器支持C99)
#define NUM 10
const int a = 1;
int b = 1;
int arr[10]; // 合法
int arr1[5 * 2]; // 合法
int arr2[sizeof(int) * 1]; // 合法
int arr3[NUM]; // 合法
int arr6[-1]; // 不合法,数组大小必须大于0
int arr7[1.5]; // 不合法,数组
int arr4[a]; // C99前不支持
int arr5[b]; // C99前不支持
数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
float f[3] = {1.0,2.0,3.0};
// 字符数组初始化的两种方式
char arr2[5] = {'a','b','c','d'};
char arr3[5] = "abcd"; // 字符串字面量默认尾部添加\0,\0占有位置
...
不完全初始化
当初始化的元素个数小于数组大小时,未被赋值的元素默认初始化为0。
int arr[10] = {1,2,3}; //不完全初始化

char arr[5] = {'a','b','c'};
char arr[5] = "abc";

字符数组内赋整型
- 给字符数组内赋值数字整型,如果在ASCII码值范围内,则会被解析成ASCII值对应的字符。
char arr[3] = {'a',98,'c'};

不指定元素个数
如果在创建数组时,不指定元素个数,则必须初始化,数组的大小由初始化的元素个数决定。
int arr[] = { 1,2,3 };
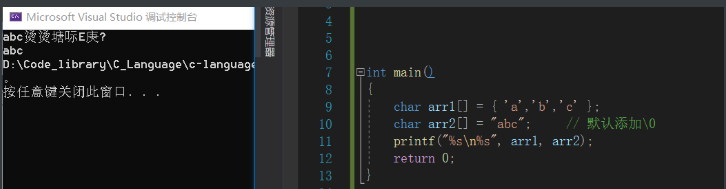
char arr1[] = { 'a','b','c' };
char arr2[] = "abc"; // 默认添加\0

arr1和arr2 同样初始化为abc,但是元素的个数却不相同,从调试结果看出 arr2 默认在末尾添加了一个\0, 这也是双引号引起的字符串字面量的特点。

从输出结果可以看到,以字符串格式打印两个数组的内容,arr1数组没有\0结束标志,所以在打印完abc后会继续打印随机值,直到遇到\0结束。
再对比strlen()函数和sizeof操作符的结果,可以看出sizeof计算的数组所占空间的大小,初始化为3个元素则占3个byte,而strlen() 计算字符串长度时是以\0为结束标志,并且不统计\0。

数组未初始化
如果数组未初始化,直接访问数组获得的值会是内存相应位置上的现有值。(系统不同,输出的结果不同)
int main()
{
int arr[10];
int i = 0;
printf("%2s%14s\n",'i','arr[i]');
for(i = 0;i < 10;i++)
{
printf("%2d%14d\n",i,arr[i]);
}
return 0;
}

上面提到数组属于自动存储类别,指的是这些数组在函数内部声明,且声明时未使用static关键字。
不同的存储类别由不同的属性,对于一些其他存储类别的变量和数组。如果在声明时未初始化、编译器会自动把它们设置未0。
指定初始化器
指定初始化器是C99中新增的一个特性,利用该特性可以指定数组中哪个元素被初始化。
在C99之前,如果只想初始化一个下标非0的元素,必须要将它之前的元素全部初始化。
// 例如初始化下标为2个元素
int arr[5] = {0,0,3};
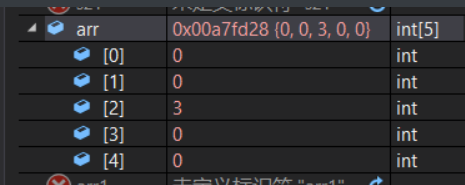
而在C99中规定,可以在初始化的{}中使用带[]的下标,来指明要初始化数组中的哪个元素。
int arr[5] = { [2] = 3 };
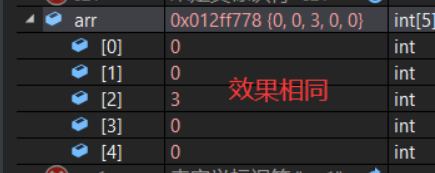
在使用指定初始化器时还应该注意两点
指定初始化器之前如果有未初始化的元素,而之后也有元素,那么之后的元素将按照指定初始化器的下标往后继续排列。指定初始化器可以覆盖前面已经被初始化元素的值。
int main()
{
int arr[10] = {1,2,[4]=5,6,7,8,9,10,[0]=3};
return 0;
}

从调试信息可以看到,arr[2]、arr[3] 未初始化,指定初始化器[4]后面的值,从arr[4]往后排列,而arr[0]的指定初始化器[0] 覆盖了。
一维数组的使用
要使用数组中的元素,需要通过[]下标引用操作符,并在其中指定数组的下标来访问元素,数组的下标从0开始,到数组大小 - 1 结束。
在之前我们简单的学习过指针变量和解引用操作符*,而其实数组变量和下标引用操作符[]和它们很相似,数组的变量名是数组第一个元素的地址,而下标引用操作符[]相当于*(数组名 + 下标)通过解引用找到对应下标的元素。
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d %d", arr[0], arr[9]);
return 0;
}

数组元素赋值
- 声明数组后,如果未初始化,可以使用循环遍历数组来给数组中的每个元素赋值。
int main()
{
int arr[10];
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for(i = 0;i<sz;i++)
{
arr[i] = i;
}
return 0;
}

- 而如果想获取数组中每个元素的值也可以通过这种方式。
int main()
{
int arr[10];
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
// 赋值
for (i = 0; i < sz; i++)
{
arr[i] = i;
}
// 获取
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]); // 将循环变量作为数组的下标
}
return 0;
}

- 字符数组可以使用
%s以字符串格式打印数组。
int main()
{
char arr[] = "abcdefg";
printf("%s\n",arr);
return 0;
}

注意:C语言中不允许把数组作为一个单元赋给另外一个数组,初始化以外也不允许使用花括号{}的形式来赋值。
int main()
{
int arr1[5] = {1,2,3,4,5};
int arr2[5];
arr2 = arr1; // 错误
arr2[5] = arr1[5]; // 下标越界
arr2[5] = {1,2,3,4,5} // 错误
return 0;
// 创建数组时[count_num] 指的是元素个数
// 而在使用时[num] 指的是下标号
}
下标越界
下标越界是指,在访问数组元素时,指定数组的下标是大于等于数组元素的个数,在给数组元素赋值时,赋予值的个数超过数组元素的个数。
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
for(i = 0;i <= sizeof(arr) / sizeof(arr[0]);i++ )
{
printf("%d ", arr[i]);
}
return 0;
}
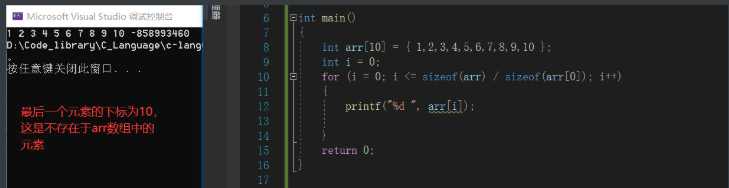
可以看到使用了越界的下标虽然编译器未报错,但是打印出来的值内存当前位置上存在的值。因为在C标准中,使用越界下标的结果是未定义的。
为什么这么明显的错误,编译器却不报错呢?
因为如果不检查边界,C程序可以运行的更快,编译器没有必要捕获所有的下标错误,因为在程序运行前,数组下标值中可能尚未确定。如果了安全起见,编译器就必须在运行时添加额外代码检查数组的每个下标值,但是这会影响程序的运行速度。
int main()
{
int arr[5] = {1,2,3,4,5,6};
int i = 0;
for(i = 0; i < sizeof(arr) / sizeof(arr[0]);i++)
{
printf("%d ",arr[i]);
}
return 0;
}
一维数组在内存中的存储
数组元素在内存中的存储空间是连续的,我们可以通过遍历数组来打印每个元素的地址。
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for(i = 0;i < sz; i++)
{
printf("&arr[%d] == %p",i,&arr[i]);
}
return 0;
}

结果可以看出地址的显示格式为16进制,也就是1,2,3,4,5,6,7,8,9,a,b,c,d,e,f。通过简单的计算可以发现,每个地址间相差为4,而int类型的变量在内存中所占空间也是4个字节,所以可以确定,数组的存放是连续的,数组的下标和地址都是从前往后连续增长的。
二维数组
二维数组本质上是以数组作为数组元素的数组,即“数组的数组”。二维数组又称为矩阵,行列数相等的矩阵称为方阵。
— 转载自百度百科
二维数组的创建和初始化
二维数组的创建同样需要指明数组元素的数据类型,数组名,和方括号1[count_int_n]代表主数组内的数组元素的个数,方括号2[count_int_n]每个数组元素内元素的个数。
类型说明符 数组名[count_int_n1][count_int_n2]
可以将第一个括号内的常量看作行数,第二个括号内的常量看作列数。
int arr[3][4]; // 3行4列,数组元素为int类型

图片中直观反映了,二维数组里每个元素的位置及它们的下标。
其他元素的创建方法同理
char arr1[3][4]; // 3行4列,数组元素为char类型
float arr2[5][6]; // 5行6列,数组元素为float类型
double arr3[7][8]; // 7行8列,数组元素为double类型
二维数组的初始化
二维数组的初始化建立再一维数组初始化的基础上,每一行其实就是一个一维数组,因此可以将{}中嵌套若干个{}中间用逗号,分隔,表示每一行数组的初始化。
int main()
{
int arr[3][4] = {{0,1,2},{3,4,5},{7,8,9}};
return 0;
}

可以看到,每一行中只赋值了前3个元素,而最后一个元素默认初始化为0,因此二维数组中不完全初始化的结果与一维数组相同。
同时如果下标越界只有对越界的行有影响,并不会影响到其他行的初始化。
另外,二维数组的初始化也可以采用一维数组初始化的方式,即只用一个{}来包含初始化的值,默认从[0][0] 开始赋值,本行结束再继续从下一行的首元素开始赋值。
int main()
{
int arr[3][4] = { 1,2,3,4,5,6 };
return 0;
}

从图中可以看到声明一个3行四列的二维数组,数组大小为12,初始化{1,2,3,4,5,6} 从[0][0]开始赋值,本行结束继续从下一行首元素开始赋值,未初始的元素默认初始化未0。
列数不可以省略
二维数组再初始化时,行数可以省略,但列数一定不能省略。
// 行列同时省略
int main()
{
int arr[][] = { {0,1,2},{3,4,5},{7,8,9} };
int arr1[][] = { 1,2,3,4,5,6,7,8 };
return 0;
}
// 编译器会报错

// 省略列
int main()
{
int arr[3][] = { {0,1,2},{3,4,5},{7,8,9} };
int arr1[3][] = { 1,2,3,4,5,6,7,8 };
return 0;
}
// 编译器同样报错

// 省略行
int main()
{
int arr[][4] = { {0,1,2},{3,4,5},{7,8,9} };
int arr1[][4] = { 1,2,3,4,5,6,7,8 };
return 0;
}
// 编译器未报错

从上面测试可以发现,列数一定不能省略。同时,采用嵌套花括号{}的方式初始化,行数是由内嵌{}的个数决定的,而使用单花括号{}的方式初始化,行数 = 初始化的元素个数 / 列数。
二维数组的使用
借用上面的图片可以发现,如果想访问一个元素只需要指定这个元素所在的行下标和列下标即可。
行下标从0开始,每一行的列下标也是从0开始。

int main()
{
int arr[3][4] = { {0,1,2},{3,4,5},{7,8,9} };
printf("%d %d\n ",arr[1][1],arr[2][2]);
// 打印第2行第2列值为4的元素 和 第3行第3列值为9的元素
return 0;
}

数组赋值
二维数组在在赋值时因为需要同时指定行下标和列下标,因此需要用到双重循环来给元素赋值,外层循环负责行数,内层循环负责列数。
列数 == 行数组大小 / 元素大小
行数 == 二维数组大小 / 元素大小 / 列数
int main()
{
int arr[3][4] = {0};
int i = 0;
int j = 0;
int col = sizeof(arr[0]) / sizeof(arr[0][0]);
int row = sizeof(arr) / sizeof(arr[0][0]) / col;
for ( i = 0; i < row; i++)
{
for (j = 0; j < col; j++)
{
arr[i][j] = j; // 第i行下标为j的元素。
}
}
return 0;
}

如果需要遍历访问数组,方法与赋值相同。
// 打印上面二维数组的每一个元素
int main()
{
int arr[3][4] = {0};
int i = 0;
int j = 0;
int col = sizeof(arr[0]) / sizeof(arr[0][0]);
int row = sizeof(arr) / sizeof(arr[0][0]) / col;
// 赋值
for ( i = 0; i < row; i++)
{
for (j = 0; j < col; j++)
{
arr[i][j] = j; // 第i行下标为j的元素。
}
}
// 打印
for ( i = 0; i < row; i++)
{
for (j = 0; j < col; j++)
{
printf("%d ",arr[i][j]);
}
printf("\n"); // 打印完一行后换行
}
return 0;
}
二维数组在内存中的存储
二维数组在内存中的存储位置依然是连续的,从下面结果可以得出。
// 打印上面二维数组的每一个元素的地址
int main()
{
int arr[3][4] = { 0 };
int i = 0;
int j = 0;
int col = sizeof(arr[0]) / sizeof(int);
int row = sizeof(arr) / sizeof(arr[0][0]) / col;
// 赋值
for (i = 0; i < row; i++)
{
for (j = 0; j < col; j++)
{
arr[i][j] = j; // 第i行下标为j的元素。
}
}
// 打印
for (i = 0; i < row; i++)
{
printf("-----第%d------",i);
for (j = 0; j < col; j++)
{
printf("&arr[%d][%d] = %p\n",i,j,&arr[i][j]);
}
}
return 0;
}

我们平时为了方便理解,经常把二维数组以矩阵的形式展示出来。

实际在内存中它是这样形式存储的。
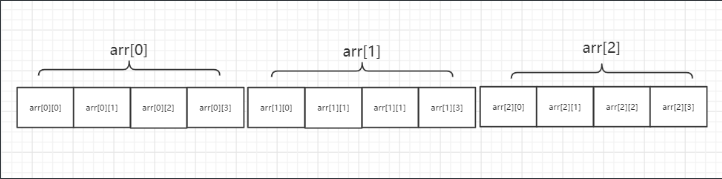
我们可以将arr[i]看作是一维数组的数组名,而arr[i][j] 看作为该数组中的每一个元素。
数组与指针
指针在初始C语言中简单介绍过,可以把指针看作地址,把地址看作指针。通过地址找到(指向)内存中所在的那块空间。
而前面也介绍过数组名通常情况下是数组首元素的地址,因此假设创建一个数组arr[],那么arr == &arr[0],两者都是常量,不会被改变。
int main()
{
int arr[] = { 1 };
int* p1 = arr;
int* p2 = &arr[0];
if (p1 == p2)
{
printf("p1 = %p\n", p1);
printf("p2 = %p\n", p2);
printf("*p1 = %d\n", *p1);
printf("*p2 = %d\n", *p2);
}
return 0;
}

从打印结果可以看出,数组名 == 数组首元素的地址。
我们可以将数组的地址赋值给指针变量,来修改指针变量的值,达到使用数组的效果。
int main()
{
int arr[5] = { 1,2,3,4,5 };
char str[5] = { 'a','b','c','d','e' };
int* pi = arr; // 将数组首元素的地址赋值给指针变量
char* pc = str;
int i = 0;
printf("%10s %25s\n", "int", "char");
for (i = 0; i < 5; i++)
{
printf("arr[%d].val == %-8d | str[%d].val == %-8c\n", i, *(pi + i),i, *(pc + i));
printf("arr[%d].addr == %p | str[%d].addr == %p\n", i, pi + i,i, pc + i);
}
return 0;
}

通过 指针 +n的方法可以高效的获取到数组中的元素,在C语言中指针 +n是指增加n个存储单元,对于数组来说,它指向的当前地址后面第n个元素的地址。
从打印结果可以看出int类型的数组和char类型的数组所增加的值是不同的,int每次加4,char每次加1,这是因为,int类型的数据所占内存空间为4btye,char类型的数据所占内存空间为1btye,这也是为什么在声明指针变量时需要在指针变量前加上数据类型,它代表的不是指针的数据类型,而是它所指向对象的数据类型。
数组和指针的关系
通过上面的例子,可以发现下面两种表示方式是等价的
// 取地址的结果相同
// arr + n == &arr[n] , n>=0 && n< 元素个数
// str + n == &str[n] , n>=0 && n< 元素个数
// 解引用的结果相同
//*(arr+n) == arr[n]; , n>=0 && n< 元素个数
//*(str+n) == str[n]; , n>=0 && n< 元素个数
// 上面验证使用的是指针变量pi和pc,不过pi == arr ,
代码验证
int main()
{
int arr[5] = { 1,2,3,4,5 };
char str[5] = { 'a','b','c','d','e' };
int* pi = arr; // 将数组首元素的地址赋值给指针变量
char* pc = str;
int i = 0;
printf("%10s %25s\n", "int", "char");
printf("%p == %p | %p == %p\n", arr + 2, &arr[2], str + 2, &str[2]);
printf("%8d == %-8d | %8c == %-8c\n", *(arr + 2), arr[2], *(str + 2),str[2]);
return 0;
}

也就是说想获取数组中的一个元素,可以有*(addr + idx) 和 arr_name[idx]两种方法,而获取它们的地址也有addr + idx 和 &arr_name[idx]两种方法。
这里需要注意*(addr + idx) 和 *addr + idx , 前者表示先指向后面的地址,再解引用获取地址里的值;而后者则是先解引用获取当前地址的值,再将这个值+ idx,两种写法的结果是完全不同的,后者相当于(*addr) + idx。
可以发现数组和指针的关系十分密切,我们对数组名的操作可以同样运用在存放相同数组元素地址的指针变量上,但是数组名和指针又不是完全相同。
数组名和指针变量的区别
数组名虽然存放的是首元素的地址,但是它不等于指针变量。数组名有两点不同于指针变量的地方。
sizeof在计算数组名时,会返回整个数组所有元素大小的合,这个值是根据不同的数据类型来计算的,而指针变量返回的就是本身的大小,32bit平台下4btye,64bit平台下8btye,这是指针变量这种数据类型的特点,因为它是用来存放地址的。
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[5];
printf("arr.sz == %d\n", sizeof(arr));
printf("p.sz == %d\n", sizeof(p));
return 0;
}

- 当
&数组名时,此时得到的结果是整个数组的地址,而取指针变量的地址,得到的结果就是指针变量自己的地址。
int main()
{
// 这里将 p 的接受值改为数组第一个元素的地址
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];
printf("arr = %p\n", arr);
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr = %p\n", &arr);
printf("&*p = %p\n", &(*p));
printf("&p = %p\n", &p);
return 0;
}

从打印的结果来看,&p 确实是指针变量p 的地址,但是前四个地址显示的都是数组首元素的地址,那么和&arr的结果与上面的结论就不同了,可事实是,&arr 虽然打印出来的是数组首元素第一个的地址,但是它代表的是整个数组的开始。我们现在给每个地址都加 1 看看会发生什么。
int main()
{
// 这里将 p 的接受值改为数组第一个元素的地址
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];
printf("arr = %p\n", arr);
printf("arr + 1 = %p\n", arr + 1);
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0] + 1 = %p\n", &arr[0] + 1);
printf("&arr = %p\n", &arr);
printf("&arr + 1 = %p\n", &arr + 1);
printf("&*p = %p\n", &(*p));
printf("&*p + 1 = %p\n", &(*p) + 1);
printf("&p = %p\n", &p);
printf("&p + 1 = %p\n", &p + 1);
return 0;
}

从这次的打印结果可以看到除了 &arr 其他4个的地址+ 1都指向了下一块内存空间的地址,相差为4,(因为数组是int类型每个元素的大小为4个字节,也就是占有4个内存块);而只有&arr + 1相差了40,这40是如何的出来的呢?因为我们数组里有10个int类型元素,每个元素占有4btye的内存空间,也就是占有4个内存块 因此总共相差40,这也就说明了&arr获取的是整个数组的地址。
以上两点是使用数组名的例外的情况,其他情况下数组名存放的都是数组首元素的地址。
不过当用指针变量接受数组内元素的地址时,也可以通过下标引用操作符来找到指定的元素,数组中默认第一个元素下标为0,而指针变量则是接收到的那个元素的下标为0。
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[5];
printf("arr[0] == %d\n", arr[0]);
printf("p[0] == %d\n", p[0]);
return 0;
}

从打印结果可以看出,arr[0]是数组第一个元素,而p[0]则是p接收到的那个地址指向的元素。
数组在函数中的使用
如果想在函数中处理数组,需要将数组名作为实参传递给形参,注意:传递的不是整个数组而是数组第一个元素的地址,而接收数组地址的形参有两种声明方式。
指针表示法
既然传递的参数是地址,首先想到的是用指针变量来作为形参,这种方式是可行的。
当形参指针变量接收到这个地址时,我们可以通过之前介绍的两种方式来获取到数组元素。
使用单目操作符+ -
+ 可以获取数组下一个元素的地址,-则可以获取到数组上一个元素的地址。
// 形参为指针变量
void get_ptr(int* ptr)
{
int i = 0;
for (i = 0; i < 10; i++)
{
printf("ptr[%d].value == %d\n",i, *(ptr + i));
printf("ptr[%d].addr == %p\n",i, ptr + i);
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
get_ptr(arr);
return 0;
}

使用解引用操作符[]
// 形参为指针变量
void get_ptr(int* ptr)
{
int i = 0;
for (i = 0; i < 10; i++)
{
printf("ptr[%d].value == %d\n", i,ptr[i]);
printf("ptr[%d].addr == %p\n", i,&ptr[i]);
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
get_ptr(arr);
return 0;
}

"数组"表示法
我们可以在声明一个形如"数组"形式的形参,这里"数组" 括双引号表示它并不是数组。
获取元素的方式和指针变量相同。
// 形参为"数组"形式
void get_arr(int arr[])
{
int i = 0;
for (i = 0; i < 10; i++)
{
printf("*(arr + %d).val == %-9d | arr[%d].value == %d\n", i, *(arr + i), i, arr[i]);
printf("arr + %d.addr == %p | arr[%d].addr == %p\n", i, arr + i, i, &arr[i]);
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
get_ptr(arr);
return 0;
}

两种表示方法的关系
从上面的代码中,我们可以发现int arr[] == int* ptr ,它们实际上表示的都是一个指向int类型的指针,而int arr[] 只有在函数声明或函数定义的函数头中才能代替int* ptr。
因此下面的函数声明和函数定义是等价的。
// 函数声明
void get_arr(int arr[]);
void get_arr(int []); //函数声明可以省略参数名
void get_arr(int* arr);
void get_arr(int* );
// 函数定义
void get_arr(int arr[])
{
;
}
void get_arr(int* arr)
{
;
}
选择用"数组"表示法来声明形参,可以让代码可读性更高,表示了接收到的地址是数组元素的地址。
选择指针表示法,尤其与递增运算符一起使用时,更加接近机器语言,因此在编译时能生成效率更高的代码。
传递数组大小
在上面讲到,数组名作为实参传递是数组首元素的地址,而不是整个数组,这一点可以通过在函数内部打印这个形参的大小来确认。
int get_size(int arr[])
{
return sizeof(arr);
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("arr.size == %d\n", sizeof(arr));
printf("get_size == %d\n",get_size(arr);)
return 0;
}

那么如果想在如果需要在函数内部遍历数组,需要获取到数组的起点和终点,而形参只是数组的起点,那终点如何获取呢?
有两种方法可以实现
将数组大小以参数传递
可以在主调函数内计算数组的大小,并以参数的形式传给被调函数。
int sum(int arr[], int sz)
{
int i = 0;
int total = 0;
for (i = 0; i < sz; i++)
{
total += arr[i];
}
return total;
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
printf("sum == %d\n", sum(arr, sz));
return 0;
}

传递数组首元素地址和数组结束位置
用数组的第一个元素的地址,和数组最后一个元素后面的第一个位置的地址来作为被调函数内数组的起点和终点,C语言允许指向数组后面第一个位置的指针式有效指针。
int sump(int* start, int* end)
{
int total = 0;
while(start < end)
{
total += *start++; // 简介写法
// total += *start;
// start++;
}
}
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);
printf("sum == %d\n",sum(arr,arr + sz);); // 起点,终点
return 0;
}

start的地址从数组第一个元素开始,end的地址是数组最后一个元素后一个位置,这个位置是未定义的,虽然C语言保证了对它的指向是有效的,但是对该位置上的值未作任何保证。
分析total += *start++
*start++,单目操作符*和++优先级相同,但是结合律从右往左,因此start++ 先被捆绑在一起。
又因为后置++是先使用再自增,因此解引用操作符*先通过start现在的地址找到对应内存空间中存放的值。
接着start再自增,指向下一块内存空间。
最后 total += 之前解引用得到的值,因此这种写法的执行顺序和逻辑与被注释代码的逻辑相同,结果也相同。
冒泡排序
函数实现冒泡排序,需要注意的地方在于,形参存放的只是数组首元素的地址,因此并不能在被调函数中计算数组的大小,而是要在数组所在的主调函数内计算数组大小,并以函数参数的形式传递。
而它的功能实现也并不复杂,在之前的文章中也有提及,这里做了一些优化就是创建了一个flag变量用来假设本次循环为有序数组,flag默认为 1如果本次循环是无序数组则会进入比较两个元素大小的if语句中,其实只要在交换两个元素的位置后将flag的变量赋值为0继续下一次循环,当有一次循环没有进入比较两个元素大小的if语句中时,则说明这个这个数组已经是有序的,接着进入下一个判断flag真假的if语句中,break; 跳出整个循环。
// 冒泡排序
void bubble_sort(int arr[], int sz)
{
int i = 0;
int j = 0;
for (i = 0; i < sz - 1; i++)
{
for (j = 0; j < sz - i - 1; j++)
{
// 默认本次循环为有序数组
int flag = 1;
if (arr[j] < arr[j + 1])
{
int tmp = 0;
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
// 如果进入这个if,则说明数组无序
flag = 0;
}
if (flag)
{
// 如果进入这个if,说明数组已经有序
break;
}
}
}
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
bubble_sort(arr, sz);
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}















 3165
3165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









