







机器学习概述
机器学习与人工智能、深度学习关系
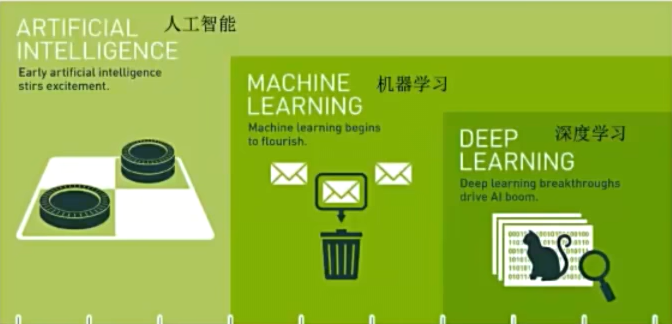
什么是机器学习
机器学习是从数据中自动分析获取模型,并利用模型对未知数据进行预测。
直观理解:
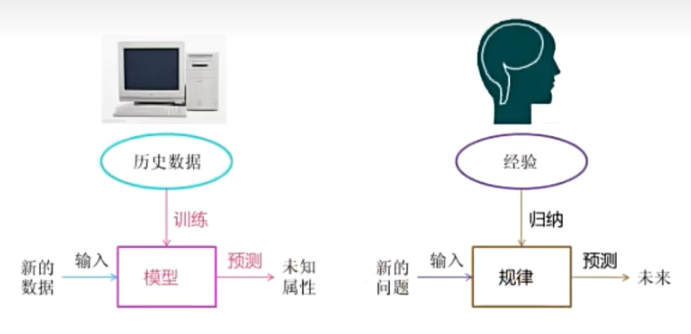
所以是从历史数据中获取规律,那么这些历史数据是怎么构成的呢?
数据集
结构:特征值+目标值
正式定义:
特征值与目标值
特征值(Features):
描述数据的属性(通常是多列),用X表示。
例如:房价预测中的面积、地段、房龄。
目标值(Target):
模型要预测的结果(通常是单列),用y表示。
例如:最终的房价。
case:用“相亲”比喻机器学习
假设你是一个相亲网站的AI,任务是预测两个人是否适合结婚。你需要收集数据并让模型学习规律:
特征值(Features):
就是模型的“输入线索”,比如:
年龄、身高、收入、兴趣爱好、学历
相当于你作为媒人时,会问对方的“条件”。
目标值(Target):
是模型要“猜”的结果,比如:
是否成功结婚(是/否)
相当于你最终看到的“相亲结果”。
算法
一、监督学习(Supervised Learning)
核心思想:像老师教学生,给算法“标准答案”(即目标值y)去学习规律。
- 典型案例:
分类问题 → 预测类别
例:垃圾邮件识别(是/否)、癌症诊断(恶性/良性)
回归问题 → 预测数值
例:房价预测、股票价格
- 常用算法:
算法名称 比喻 适用场景
线性回归 用尺子画最拟合的直线 房价趋势预测
决策树 连环问答式判断 贷款审批
随机森林 多个专家投票决策 电商用户流失预警
SVM(支持向量机) 找最大间隔的分界线 图像分类 - 关键特点:
必须有已标注的数据(即既有X也有y)
模型训练后可以预测新数据的y值
二、无监督学习(Unsupervised Learning)
核心思想:像让孩子自己整理玩具,没有标准答案,算法自行发现数据中的模式。
- 典型案例:
-
聚类(Clustering) → 自动分组
例:用户分群、新闻话题归类 -
降维(Dimensionality Reduction) → 压缩数据
例:3D数据可视化展示到2D
- 常用算法:
算法名称 比喻 适用场景
K-Means 按距离划分小组 市场客户细分
PCA 提取最关键特征 人脸识别预处理
Apriori 找频繁出现的组合 超市商品关联推荐 - 关键特点:
只有特征值X,没有目标值y
结果通常需要人工解读意义
三、强化学习(Reinforcement Learning)
核心思想:像训练小狗,通过“奖励/惩罚”让算法自己摸索最佳策略。
- 典型案例:
游戏AI(如AlphaGo)
自动驾驶决策
机器人控制
- 核心概念:
Agent(智能体):学习的AI
Environment(环境):交互的世界
Reward(奖励):行为的反馈信号
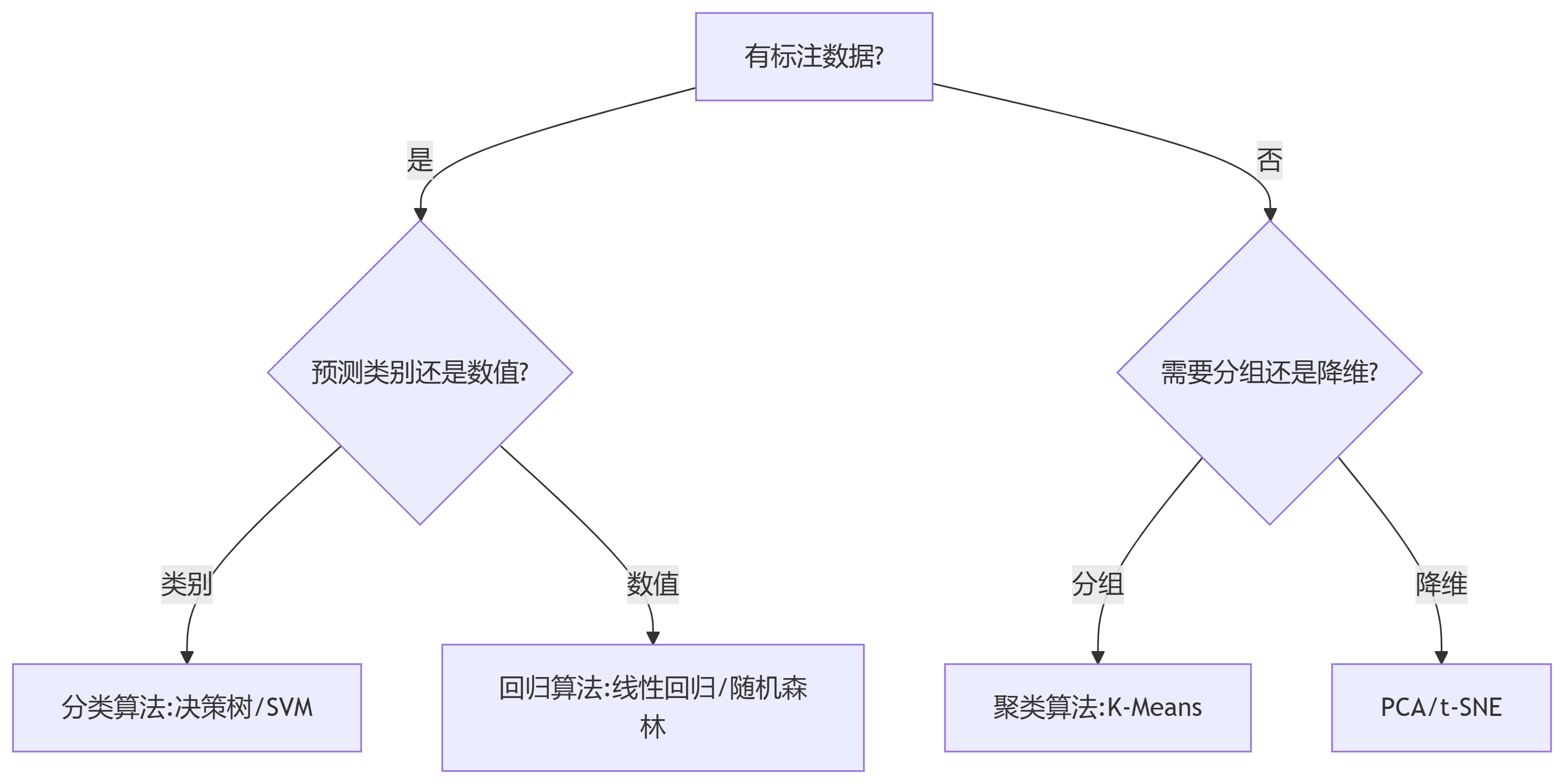
四、算法选择流程图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









