






语法
val newRdd = oldRdd.mapPartitionsWithIndex{case (num, datas) => {func}}源码
def mapPartitionsWithIndex[U](f : scala.Function2[scala.Int, scala.Iterator[T], scala.Iterator[U]], preservesPartitioning : scala.Boolean = { /* compiled code */ })(implicit evidence$9 : scala.reflect.ClassTag[U]) : org.apache.spark.rdd.RDD[U] = { /* compiled code */ }
- 1
作用
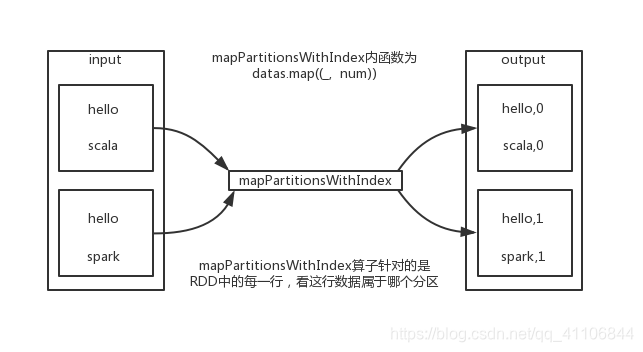
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U]
例子
package com.day1 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object oper { def main(args: Array[String]): Unit = { val config:SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordCount") // 创建上下文对象 val sc = new SparkContext(config) // mapPartitionsWithIndex算子 val listRdd:RDD[Int] = sc.makeRDD(1 to 10,2) val tupleRdd: RDD[(Int, String)] = listRdd.mapPartitionsWithIndex { case (num, datas) => { datas.map((_, "分区号为:" + num)) } } tupleRdd.collect().foreach(println) } } 输入: 1 2 3 4 5 6 7 8 9 10 输出: (1,分区号为:0) (2,分区号为:0) (3,分区号为:0) (4,分区号为:0) (5,分区号为:0) (6,分区号为:1) (7,分区号为:1) (8,分区号为:1) (9,分区号为:1) (10,分区号为:1)
示意图















05-06
 1194
1194
1194
06-08
448
448
03-18
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









