






#########################################################################################
环境准备:
虚拟机3台,均可连外网
master
0001:192.168.10.13
worker
0002:192.168.10.14
0003:192.168.10.15
最低2cpu 2G内存,我虚拟机硬盘配置的100G
所有节点禁用交换分区swap,禁用防火墙Firewalld iptables禁用 disabled selinux
uname -a 内核需3.08以上版本
docker版本:docker 17.12.0-ce kube组件版本:1.14.10.0
###########################################################################################
在所有节点安装docker:
安装docker之前需安装必要软件
yum install -y yum-utils device-mapper-persistent-data lvm2
安装docker17.12.0yum源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
如果已有旧版本,需卸载后再装docker
yum remove docker docker-common docker-selinux docker-engine
rm -rf /var/lib/docker/*
查看仓库中所有的docker软件版本,选择合适版本安装
yum list docker-ce --showduplicates | sort -r
安装指定版本docker
yum install docker-ce-17.12.0.ce
安装完成后检查docker版本
docker --version

启动docker,并设置开机自启
systemctl start docker && systemctl enable docker
################################################################################################
Kubernetes安装分为Etcd、Kubernetes、Flannel、Rancher2.0几部分。
安装etcd
添加额外yum源:没有可网上查找同版本的源kubelete1.14.10.0
[root@0001 yum.repos.d]# cat local.repo
[local]
name=local
baseurl=http://foreman.lilinlin.science:8080
gpgcheck=0
enable=1
安装etcd (etcd自带高可用,这里只在主节点上安装了,也可以在三个节点上都配置etcd达到更安全)
yum install -y etcd
配置etcd,修改配置文件/etc/etcd/etc.conf
#[Member]
#ETCD_CORS=""
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
#ETCD_WAL_DIR=""
ETCD_LISTEN_PEER_URLS="http://172.29.5.182:2380"
ETCD_LISTEN_CLIENT_URLS="http://172.29.5.182:2379,http://127.0.0.1:2379"
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
ETCD_NAME="node01"
#ETCD_SNAPSHOT_COUNT="100000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
#ETCD_QUOTA_BACKEND_BYTES="0"
#ETCD_MAX_REQUEST_BYTES="1572864"
#ETCD_GRPC_KEEPALIVE_MIN_TIME="5s"
#ETCD_GRPC_KEEPALIVE_INTERVAL="2h0m0s"
#ETCD_GRPC_KEEPALIVE_TIMEOUT="20s"
#
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://172.29.5.182:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://172.29.5.182:2379,http://172.29.5.185:2379,http://172.29.5.199:2379"
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_FALLBACK="proxy"
#ETCD_DISCOVERY_PROXY=""
#ETCD_DISCOVERY_SRV=""
ETCD_INITIAL_CLUSTER="node01=http://172.29.5.182:2380,node02=http://172.29.5.185:2380,node03=http://172.29.5.199:2380"
#ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
#ETCD_INITIAL_CLUSTER_STATE="new"
#ETCD_STRICT_RECONFIG_CHECK="true"
#ETCD_ENABLE_V2="true"
#
#[Proxy]
#ETCD_PROXY="off"
#ETCD_PROXY_FAILURE_WAIT="5000"
#ETCD_PROXY_REFRESH_INTERVAL="30000"
#ETCD_PROXY_DIAL_TIMEOUT="1000"
#ETCD_PROXY_WRITE_TIMEOUT="5000"
#ETCD_PROXY_READ_TIMEOUT="0"
#
#[Security]
#ETCD_CERT_FILE=""
#ETCD_KEY_FILE=""
#ETCD_CLIENT_CERT_AUTH="false"
#ETCD_TRUSTED_CA_FILE=""
#ETCD_AUTO_TLS="false"
#ETCD_PEER_CERT_FILE=""
#ETCD_PEER_KEY_FILE=""
#ETCD_PEER_CLIENT_CERT_AUTH="false"
#ETCD_PEER_TRUSTED_CA_FILE=""
#ETCD_PEER_AUTO_TLS="false"
#
#[Logging]
#ETCD_DEBUG="false"
#ETCD_LOG_PACKAGE_LEVELS=""
#ETCD_LOG_OUTPUT="default"
#
#[Unsafe]
#ETCD_FORCE_NEW_CLUSTER="false"
#
#[Version]
#ETCD_VERSION="false"
#ETCD_AUTO_COMPACTION_RETENTION="0"
#
#[Profiling]
#ETCD_ENABLE_PPROF="false"
#ETCD_METRICS="basic"
#
#[Auth]
#ETCD_AUTH_TOKEN="simple"
开启etcd并设置开机自启
[root@0001 ~]# systemctl start etcd && systemctl enable etcd
安装指定版本的kube组件
yum install kubectl-1.14.10 kubelet-1.14.10 kubeadm-1.14.10 -y
安装完成后确认版本
[root@0001 ~]# yum list installed |grep kube
kubeadm.x86_64 1.14.10-0 @local
kubectl.x86_64 1.14.10-0 @local
kubelet.x86_64 1.14.10-0 @local
kubernetes-cni.x86_64 0.7.5-0 @local
修改docker-engine和kubelet使用的cgroup为cgroupfs(这里必须修改为一样,不然后面kubelet报错会找不到master主节点,导致集群初始化失败!)
指定kubelet的cgroup驱动:
echo ‘Environment=“KUBELET_CGROUP_ARGS=–cgroup-driver=cgroupfs”’ >> /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
echo “KUBELET_EXTRA_ARGS=–cgroup-driver=cgroupfs” >> /etc/sysconfig/kubelet
指定docker的cgroup驱动(注意json文件的缩进):
cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://tf72mndn.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=cgroupfs"],
"storage-driver": "overlay2",
"storage-opts": ["overlay2.override_kernel_check=true"]
}
重启docker服务,使配置生效
################################################################################################################
初始化k8s集群(主节点执行) kubeadm init --config=kubeadm-config.yaml
cat kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: v1.14.10
imageRepository: registry.aliyuncs.com/google_containers
apiServer:
advertiseaddress: 192.168.10.13
certSANs:
- 192.168.10.13
controlPlaneEndpoint: "192.168.10.13:6443"
networking:
podSubnet: "10.42.0.0/16"
etcd:
external:
endpoints:
- http://192.168.10.13:2379

根据报错,依次解决:

修改后重新初始化集群:
拉镜像会比较久,之前我提前导入了同版本的镜像,想节省拉镜像的时间,反而出错,不知道咋回事。。。
这是集群所需镜像的版本,可以看看下载后的是不是一致:
[root@0001 ~]# kubeadm config images list
I1106 10:17:47.915390 12636 version.go:96] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://storage.googleapis.com/kubernetes-release/release/stable-1.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
I1106 10:17:47.915528 12636 version.go:97] falling back to the local client version: v1.14.10
k8s.gcr.io/kube-apiserver:v1.14.10
k8s.gcr.io/kube-controller-manager:v1.14.10
k8s.gcr.io/kube-scheduler:v1.14.10
k8s.gcr.io/kube-proxy:v1.14.10
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.3.10
k8s.gcr.io/coredns:1.3.1
继续重复初始化集群的步骤,kubeadm init --config=kubeadm-config.yaml,可以看到集群已经初始化成功了:

记录下这条命令,用于后面加入worker节点
kubeadm join 192.168.10.13:6443 --token 8hysmj.cwfxjz803efmavfe
–discovery-token-ca-cert-hash sha256:e5dae628f093349258c04ba9348323cfc18899e16f426297efd5705081392be2
按提示依次执行以下三条命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown
(
i
d
−
u
)
:
(id -u):
(id−u):(id -g) $HOME/.kube/config
此时可以查看集群状态,由于是没安装网络插件,状态肯定是notready,而且也只有主节点一个

准备加入worker节点0002,0003,注意同步主节点的hosts解析文件
worker节点安装同版本kube软件:
yum install kubectl-1.14.10 kubelet-1.14.10 kubeadm-1.14.10 -y
设置kubelet开机自启
systemctl enable kubelet
加入worker节点:
kubeadm join 192.168.10.13:6443 --token 8hysmj.cwfxjz803efmavfe \
--discovery-token-ca-cert-hash sha256:e5dae628f093349258c04ba9348323cfc18899e16f426297efd5705081392be2
报错:

解决:
cat > /etc/sysctl.d/k8s.conf <<EOF
net.ipv4.ip_forward=1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
再执行sysctl --system刷新配置,使其生效
报错docker未启动,开启docker并设置开机自启
重新加入worker节点:

加入成功。
同样的方法加入剩余节点:
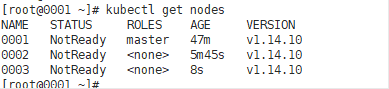
配置网络插件,flannel
主节点执行:
flannel的yaml文件可在网上找
kubectl apply -f http://xxxxxxx.xxxxxx.com/kube-flannel.yaml
配置完flannel之后,再次查看节点信息,这时候status已经全部是ready了

主要组件均为健康状态
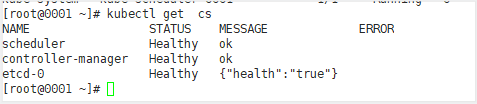
但是coredns都是notready的,说明现在k8s内网是无法解析的,集群处于不健康状态

查看该pod的情况:
[root@0001 ~]# kubectl describe pod coredns-544d76d978-rb2lj -n kube-system
可以看到是在0003这个节点上出问题了,另一个是在0002上,

查看0002 0003上并无coredns镜像 ,先拉取同版本镜像,修改其配置文件,再将主节点0001上的两个coredns的pod删除,让其重新生成新pod
kubectl edit cm coredns -n kube-system ###删除loop后 保存
kubectl delete coredns-544d76d978-88gg4 coredns-544d76d978-rb2lj -n kube-system
再次查看,已经正常了

部署ingress controller
kubectl apply -f http://xxxxxx.xxxxxxxxx.com/ingress-controller.yaml
部署Rancher服务
docker run -d --name rancher --restart=unless-stopped -p 80:80 -p 443:443 -v /opt/rancher:/var/lib/rancher rancher/rancher:v2.3.5
访问rancher,输入ip:端口 访问首页:


====================================================================
注意:在部署flannel的时候,因为是从别的地方取的flannel文件,需要将flannel.yml内的所需镜像修改成本地部署的镜像名称,镜像源看情况修改,不修改会拉不到镜像。
















 102
102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











