









有LeetCode算法/华为OD考试扣扣交流群可加 948025485
可上全网独家的 欧弟OJ系统 练习华子OD、大厂真题
绿色聊天软件戳od1336了解算法冲刺训练
文章目录
题目链接
解题思路
DFS和BFS异同
二叉树深度遍历是一个非常经典的问题,也是二叉树和递归的基础,必须掌握。
所谓二叉树遍历(traversal)指的是按照一定次序系统地访问一棵二叉树,使每个节点恰好被访问一次。
二叉树遍历实质上是二叉树的线性化,将树状结构变为线性结构。
二叉树遍历有两大类:
- 深度优先(depth first traversal,DFS):先完成一棵子树的遍历再完成另一棵
- 广度优先(breath first traversal,BFS):先完成一层节点的遍历再完成下一层
DFS和BFS均为树/图的搜索方式,能够访问树/图中的所有节点。它们的特点可以从以下的比喻看出区别:
DFS:优先移动节点,当对给定节点尝试过每一种可能性之后,才退到前一节点来尝试下一个位置。就像一个搜索者尽可能地深入调查未知的地域,直到遇到死胡同才回头。(下图以前序遍历为例)
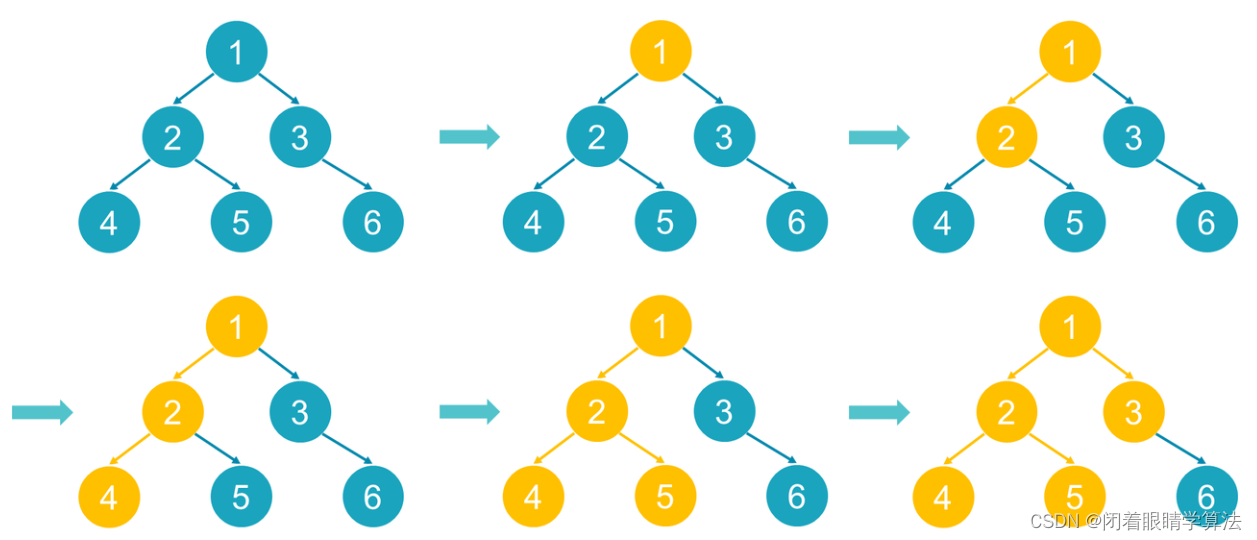
BFS:优先对给定节点的下一个位置进行进行尝试,当对给定节点尝试过每一种可能性之后,才移动到下一个节点。就像一只搜索军队铺展开来覆盖领土,直到覆盖了所有地域。
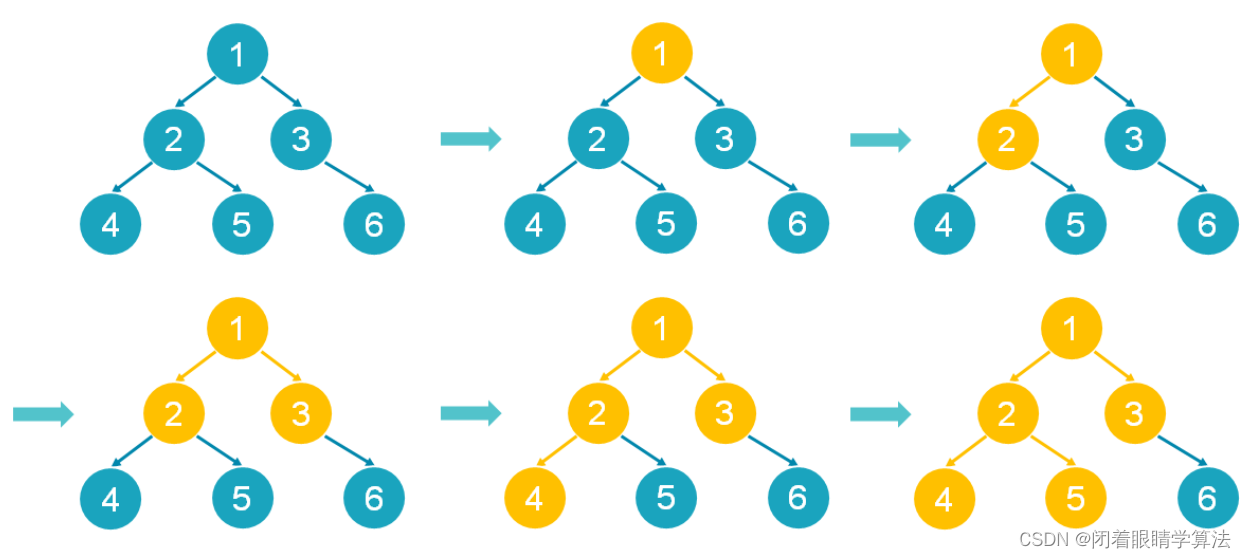
这三道题就是二叉树三种DFS的板子题,必须掌握。
递归写法
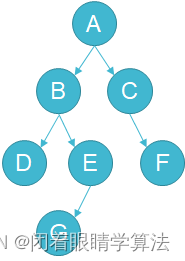
深度优先遍历又分为
- 前序遍历:访问根节点的值->前序遍历左子树->前序遍历右子树 ABDEGCF
- 中序遍历:中序遍历左子树->访问根节点的值->中序遍历右子树 DBGEACF
- 后序遍历:后序遍历左子树->后序遍历右子树->访问根节点的值 DGEBFCA
二叉树的深度优先遍历**天然地具有递归的性质。**对应的伪代码为
# 前序:访问根->遍历左->遍历右
def preorder(cur_node):
if cur_node is None:
return
visit(cur_node)
preorder(cur_node.left)
preorder(cur_node.right)
# 中序:遍历左->访问根->遍历右
def inorder(cur_node):
if cur_node is None:
return
inorder(cur_node.left)
visit(cur_node)
inorder(cur_node.right)
# 后序:遍历左->遍历右->访问根
def postorder(cur_node):
if cur_node is None:
return
postorder(cur_node.left)
postorder(cur_node.right)
visit(cur_node)
其中函数visit(node)表示访问node这个节点的值。更具体来说,可以是print(node.val)或者是将node.val的值存入全局数组等操作,这个根据具体问题决定。
注意到,不管是哪一种DFS,递归函数都包含:
- 同样的递归终止条件:当遇到当前节点
cur_node为空节点,终止递归 - 两次递归函数调用:一次对左孩子
cur_node.left进行递归,一次对右孩子cur_node.right进行递归 - 一次访问当前节点:即
visit(cur_node)的调用
而三种DFS的最大区别仅仅在于,访问根节点、遍历左孩子、遍历右孩子这三个函数的前后顺序不同。
因此只需要一套模板,就可以很方便地记住前序/中序/后序这三种不同的DFS的代码了。
非递归写法(迭代写法)
递归带来大量函数调用和额外的时间。理论上,所有递归算法都可以用非递归的迭代写法来实现。
递归执行的过程中,会使用编译栈来储存每一个递归函数的地址。
因此我们可以仿照编译栈的工作原理,显式地将节点储存在栈中。
这跟二叉树的层序遍历是非常雷同的。我们可以非常容易地写出如下所示的前序遍历的代码
# LeetCode144题二叉树的前序遍历,迭代写法(非模板)
class Solution:
def preorderTraversal(self, root):
if root is None:
return []
ans = list()
# 初始化栈为包含root节点
stack = [root]
# 进行DFS
while stack:
# 弹出栈顶元素
node = stack.pop()
# 注意这里的压栈顺序是,右入栈->左入栈
# 这样的出栈顺序才会是,先node.left再node.right
if node.right:
stack.append(node.right)
if node.left:
stack.append(node.left)
# 这访问node节点的值,写在哪里都可以
ans.append(node.val)
return ans
但是,想写出类似的中序和后序遍历的代码,就会发现有点困难了。因为visit(node)这一步无论放在哪个位置,都不会影响这是一个前序遍历的结果。
注意到,在前面的递归写法中,我们是将**遍历(traverse)和访问(visit)**这两个概念区分开的。以中序遍历的伪代码为例
# 中序:遍历左->访问根->遍历右
# 当前节点cur_node的遍历(递归入口)
def inorder(cur_node):
...
inorder(cur_node.left) # 左孩子cur_node.left的遍历
visit(cur_node) # 当前节点cur_node的访问
inorder(cur_node.right) # 右孩子cur_node.right的遍历
遍历表示要根据该节点去考虑其子节点的情况,而访问表示要访问这个节点的val。
显然这两者的行为是不完全一致的,对于当前节点cur_node而言,cur_node的遍历包含了以下三部分:
- 左孩子
cur_node.left的遍历 - 当前节点
cur_node的访问 - 右孩子
cur_node.right的遍历
换句话说,我们在遍历cur_node的时候,不能立刻对cur_node进行访问,而应该先对cur_node.left进行遍历之后(如果是后序遍历,还得是在对cur_node.right进行访问之后),才能对cur_node进行访问。
但这里就出现了一个问题:在cur_node.left遍历结束后,我们如何才能够回到cur_node来访问cur_node的值?
在递归写法中,由于cur_node.left的遍历是通过递归调用来执行的,在关于cur_node.left的递归调用结束后,会自然地回到当前关于cur_node的遍历中,其下一行要执行的内容自然就是visit(cur_node)。
但这并不会在迭代写法中自然出现。我们必须把遍历和访问的区别,用一个标识符f显式地标记出来。譬如
f = 0表示这个节点有待遍历f = 1表示这个节点有待访问
在每一个节点入栈时,不仅要储存这个节点本身,还需要储存这个节点下一步的行为对应的标识符f。
而每一个节点出栈时,我们也会会根据标识符f来区分此时节点对应的行为是遍历还是访问。
# LeetCode94题二叉树的中序遍历,迭代写法(模板)
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
ans = list()
stack = list()
# 入栈除了节点之外,还储存了一个标记f
# 标记f指的是,我们对节点要做不同的事情:遍历还是访问
# f = 0表示这个节点有待遍历
# f = 1表示这个节点有待访问
# 注意辨析这里的遍历和访问的区别
# 遍历traverse 表示要根据该节点去考虑其子节点的情况
# 访问visit 表示要访问这个节点的val
if root:
stack.append([root, 0])
while(stack):
node, f = stack.pop()
# 如果当前f为0.对应遍历node的操作
if f == 0:
# 注意压栈顺序和中序遍历的顺序必须相反
# 即:右有待遍历->根有待访问->左有待遍历
# 到时出栈的顺序就会是:
# 遍历左->访问根->遍历右
# 如果是前序或后序遍历,仅需修改以下三行的顺序即可0
if node.right: stack.append([node.right, 0])
stack.append([node, 1])
if node.left: stack.append([node.left, 0])
# 如果当前f为1,对应访问node的操作,将node.val加入全局答案变量中
if f == 1:
ans.append(node.val)
return ans
如果需要完成前序遍历或后序遍历,则仅需要调整压栈顺序即可。即
# 前序:
# 压栈顺序:遍历右->遍历左->访问根
# 出栈顺序:访问根->遍历左->遍历右
def preorder(cur_node):
...
if node.right: stack.append([node.right, 0])
if node.left: stack.append([node.left, 0])
stack.append([node, 1])
...
# 中序:
# 压栈顺序:遍历右->访问根->遍历左
# 出栈顺序:遍历左->访问根->遍历右
def inorder(cur_node):
...
if node.right: stack.append([node.right, 0])
stack.append([node, 1])
if node.left: stack.append([node.left, 0])
...
# 后序:
# 压栈顺序:访问根->遍历右->遍历左
# 出栈顺序:遍历左->遍历右->访问根
def postorder(cur_node):
...
stack.append([node, 1])
if node.right: stack.append([node.right, 0])
if node.left: stack.append([node.left, 0])
...
这样就完成了类似于递归写法的迭代写法的模板。
代码
方法一:递归写法(只给出中序遍历)
python
class Solution:
def dfs(self, ans, node):
if node is None:
return
# 中序遍历:递归遍历左 -> 访问根 -> 递归遍历递归右
# 如果是前序或后序遍历,仅需修改以下三行的顺序
self.dfs(ans, node.left)
ans.append(node.val)
self.dfs(ans, node.right)
def inorderTraversal(self, root):
ans = list()
self.dfs(ans, root)
return ans
java
public class Solution {
private void dfs(List<Integer> ans, TreeNode node) {
if (node == null) {
return;
}
// 中序遍历:递归遍历左 -> 访问根 -> 递归遍历右
// 如果是前序或后序遍历,仅需修改以下三行的顺序
dfs(ans, node.left);
ans.add(node.val);
dfs(ans, node.right);
}
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
dfs(ans, root);
return ans;
}
}
cpp
class Solution {
private:
void dfs(vector<int> &ans, TreeNode *node) {
if (node == nullptr) {
return;
}
// 中序遍历:递归遍历左 -> 访问根 -> 递归遍历右
// 如果是前序或后序遍历,仅需修改以下三行的顺序
dfs(ans, node->left);
ans.push_back(node->val);
dfs(ans, node->right);
}
public:
vector<int> inorderTraversal(TreeNode *root) {
vector<int> ans;
dfs(ans, root);
return ans;
}
};
时空复杂度
时间复杂度:O(N)。仅需一次遍历整棵树。
空间复杂度:O(N)。编译栈所占空间。
方法二:迭代写法(只给出中序遍历)
python
# LeetCode94题二叉树的中序遍历,迭代写法(模板)
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
ans = list()
stack = list()
# 入栈除了节点之外,还储存了一个标记f
# 标记f指的是,我们对节点要做不同的事情:遍历还是访问
# f = 0表示这个节点有待遍历
# f = 1表示这个节点有待访问
# 注意辨析这里的遍历和访问的区别
# 遍历traverse 表示要根据该节点去考虑其子节点的情况
# 访问visit 表示要访问这个节点的val
if root:
stack.append([root, 0])
while(stack):
node, f = stack.pop()
# 如果当前f为0.对应遍历node的操作
if f == 0:
# 注意压栈顺序和中序遍历的顺序必须相反
# 即:右有待遍历->根有待访问->左有待遍历
# 到时出栈的顺序就会是:
# 遍历左->访问根->遍历右
# 如果是前序或后序遍历,仅需修改以下三行的顺序即可0
if node.right: stack.append([node.right, 0])
stack.append([node, 1])
if node.left: stack.append([node.left, 0])
# 如果当前f为1,对应访问node的操作,将node.val加入全局答案变量中
if f == 1:
ans.append(node.val)
return ans
java
public class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
Stack<Object[]> stack = new Stack<>();
if (root != null) {
stack.push(new Object[]{root, 0});
}
while (!stack.isEmpty()) {
Object[] pair = stack.pop();
TreeNode node = (TreeNode) pair[0];
int f = (int) pair[1];
if (f == 0) {
if (node.right != null) stack.push(new Object[]{node.right, 0});
stack.push(new Object[]{node, 1});
if (node.left != null) stack.push(new Object[]{node.left, 0});
} else {
ans.add(node.val);
}
}
return ans;
}
}
cpp
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> ans;
stack<pair<TreeNode*, int>> st;
if (root) st.push({root, 0});
while (!st.empty()) {
auto [node, f] = st.top(); st.pop();
if (f == 0) {
if (node->right) st.push({node->right, 0});
st.push({node, 1});
if (node->left) st.push({node->left, 0});
} else {
ans.push_back(node->val);
}
}
return ans;
}
};
时空复杂度
时间复杂度:O(N)。仅需一次遍历整棵树。
空间复杂度:O(N)。栈所占空间
华为OD算法/大厂面试高频题算法练习冲刺训练
-
华为OD算法/大厂面试高频题算法冲刺训练目前开始常态化报名!目前已服务300+同学成功上岸!
-
课程讲师为全网50w+粉丝编程博主@吴师兄学算法 以及小红书头部编程博主@闭着眼睛学数理化
-
每期人数维持在20人内,保证能够最大限度地满足到每一个同学的需求,达到和1v1同样的学习效果!
-
60+天陪伴式学习,40+直播课时,300+动画图解视频,300+LeetCode经典题,200+华为OD真题/大厂真题,还有简历修改、模拟面试、专属HR对接将为你解锁
-
可上全网独家的欧弟OJ系统练习华子OD、大厂真题
-
可查看链接 大厂真题汇总 & OD真题汇总(持续更新)
-
绿色聊天软件戳
od1336了解更多
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









