







工作流程图
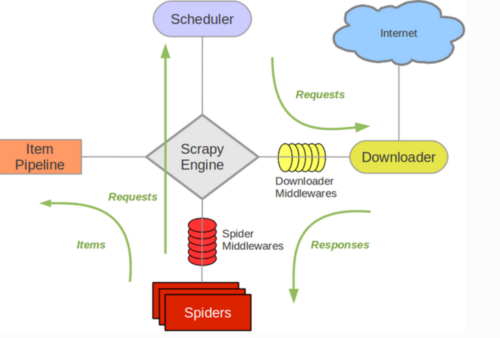
工作流程概述
- 首先通过起始的url构造一个request对象,然后通过scrapy引擎发送至调度器(sscgeduler)
- 调度器将request对象通过引擎经过下载中间件发送至下载器当中
- 下载中间件发送请求,获取response响应,经过下载中间件到scrapy引擎当中,在经过爬虫中间件发送至爬虫(spiders)里面
- 爬虫提取新的url,并将url封装成一个request对象,然后经过爬虫中间件到scrapy引擎,再到调度器,后面从步骤2开始重复
- 爬虫提取数据,通过引擎到管道组件进行修改和保存















 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









