






一 前言
大数据(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。
随着云时代的来临,大数据(Big data)也吸引了越来越多的关注。分析师团队认为,大数据(Big data)通常用来形容一个公司创造的大量非结构化数据和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像MapReduce一样的框架来向数十、数百或甚至数千的电脑分配工作。
大数据需要特殊的技术,以有效地处理大量的容忍经过时间内的数据。适用于大数据的技术,包括大规模并行处理(MPP)数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统。而帆软finebi的大数据引擎Spider具备着这些功能
二 制作大数据展示软件
1 大数据分析架构图
基于Spider大数据引擎的直连模式和本地模式,可支撑BI数据分析的各种应用场景。
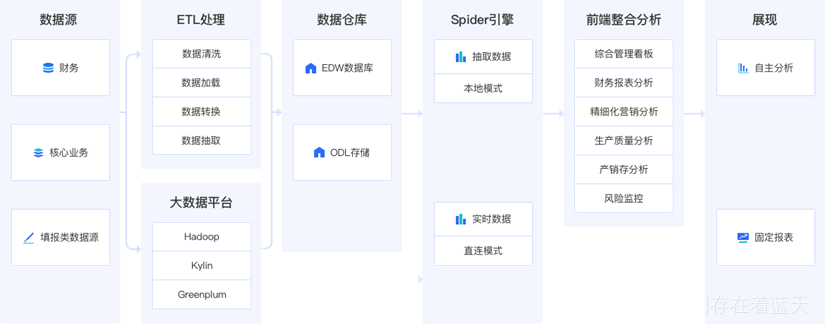
2 底层大数据技术
-
列式数据存储
抽取数据的存储是以列为单位的, 同一列数据连续存储,在查询时可以大幅降低I/O,提高查询效率,并且连续存储的列数据,具有更大的压缩单元和数据相似性,可以大幅提高压缩效率。 -
智能位图索引
位图索引即Bitmap索引,是处理大数据时加快过滤速度的一种常见技术,并且可以利用位图索引实现大数据量并发计算,并指数级的提升查询效率,同时我们做了压缩处理,使得数据占用空间大大降低。 -
数据本地化计算
为了减少网络传输的消耗,避免不必要的shuffle,利用Spark的调度机制实现数据本地化计算。在知道数据位置的前提下,将任务分配到拥有计算数据的节点上,节省了数据传输的消耗,完成巨量数据计算的秒级呈现。 -
智能缓存
直连模式下会直接和数据库对话,性能会受到数据库的限制,因此引入encache框架做智能缓存,以及针对返回数据之后的操作有多级缓存和智能命中策略,避免重复缓存,从而大幅提升查询性能。
3 典型应用场景
通过FineBI Spider引擎进行前期的数据导入,数据清洗和数据加工,然后通过仪表板组件可视化分析功能,快速完成各类维度和指标的数据管理驾驶舱的布局组合分析。从而实现无线网络大数据展示平台。
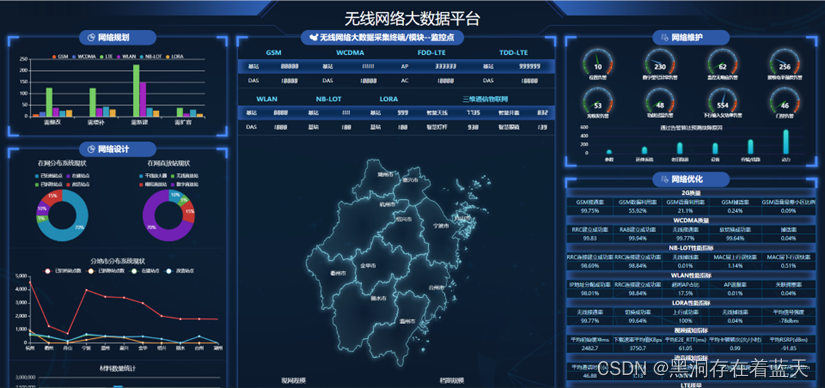
三 总结
帆软大数据展示平台可以提取、分析和显示数据,并以多种丰富形式、更加直观的方式,展示数据探索结果。帆软Finebi还设计了方便、灵活的交互方式,使非专业用户更方便、快捷地查看和分析多维模型数据。 目前的趋势,是基于web的轻量级系统,实现大数据显示平台,在很大程度上解决了大数据展示的复杂性。基于B/ S的模式实现整个平台,避免了下载体积大的客户端的麻烦,降低了用户使用的技术难度,增加了数据展示的直观性,有效解决了大数据查看和分析的困难。















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









