







一、反向传播(Backpropagation,BP)
BP算法是训练神经网络中非常核心的一步,它的作用是通过链式求导法则来计算每个参数对最终损失的影响(梯度),然后配合梯度下降算法来进行更新。
简单来说,整个神经网络参数更新流程包括四步:
- 正向输入:输入数据——>计算输出——>得到预测值
- 计算损失:(预测值 vs 真实值) ——>损失函数
- 反向传播:从输出层向输入层,逐层反向计算梯度
- 参数更新:使用梯度下降算法(即优化器)更新权重
反向传播的本质是梯度计算,配合梯度下降优化算法学习到更好的参数,从而进行模型的学习和推导
二、为什么BP这么重要?
在深度学习中,一个模型的参数可能有数十万、上百万参数甚至上亿参数,如果我们手动去计算这些参数的梯度,几乎是不可能完成的,因此,必须借助自动化的梯度计算机制来完成庞大的计算量。
BP正是完成这件事的核心算法,它能够帮助我们:
- 自动求导每个参数的梯度
- 高效地训练深度神经网络
- 快速收敛损失,使模型学到有效特征
随着深度学习的发展,模型的层数越来越深,如果没有BP算法,我们无法训练多层神经网络
三、举个例子来理解BP
我们以一个最简单的神经网络为例
输入
—> 权重
—> 线性计算
—> 激活函数 —>
—> 损失
假设:
- 输入
- 权重
(待学习)
- 真实值
1. 正向传播
x , w, t = 2.0, 1.0, 4.0
y = x * w
z = y ** 2
L = (z -t) ** 2
2. 反向传播(链式法则)
我们的目标是求:,也就是损失对权重的导数。
通过链式法则:
分别计算
所以
这个例子中损失为0,所以梯度也为0,当然现实中模型的预测值和真实值肯定会有细微差别,损失很难为0,但通过该例子清晰展示了反向传播的链式求导过程
四、计算图与BP:自动求导的核心机制
1. 什么是计算图?
在深度学习中,我们会把模型的前向过程表示为一个有向图,这个图计叫做计算图(Computation Graph):
- 节点(node):表示变量或操作(加法、乘法、ReLU等)
- 边(edge):表示依赖关系(函数关系),数据在节点之间流动
举个例子,假设函数为:
则其计算图张这样:
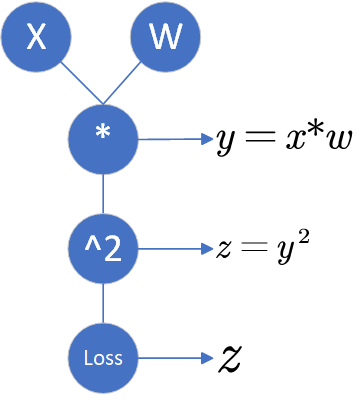
2.计算图与反向传播的关系?
当我们做正向传播时,实际上是在构建计算图并记录每一步操作的输出与依赖。
而反向传播就是:从计算图的输出节点开始,沿着图反向一次应用链式法则,计算每个节点对最终损失的导数(梯度)
计算图有以下优点:
- 自动化:可以自动生成导数公式
- 高效:只计算需要的梯度(不产生冗余)
- 灵活:支持动态图结构(Pytorch的核心特性)
3.Pytroch是怎么用计算图呢?
Pytorch使用的是动态计算图
- 在每次前向传播时即时构建计算图
- 每个Tensor会记录它是由哪些操作生成的
- 调用.backward()时会自动沿图回溯求梯度
下面我将使用Pytorch来展示具体示例:
import torch
x = torch.tensor(2.0, requires_grad=True)
w = torch.tensor(3.0, requires_grad=True)
y = x * w
z = y ** 2
loss = z
loss.backward() #自动构建计算图并反向传播
print(x.grad) #输出x的梯度值
print(w.grad) #输出w的梯度值五、手动实现一个简单的神经网络的反向传播
下面我将用Python手写一个两层的神经网络的反向传播:
import numpy as np
#初始化输入、权重w、偏置b
x = np.array([1.0, 2.0])
#第一层权重和偏置
w1 = np.random.randn(2, 3)
b1 = np.zeros(1, 3)
#第二层权重和偏置
w2 = np.random.randn(3, 1)
b2 = np.zeros(1, 1)
#真实标签
y_true = np.array([[1,0]])
#正向传播
z1 = x.dot(w1) + b1
#relu激活函数
a1 = np.maximum(0,z1)
z2 = z1.dot(w2) + b2
y_pred = z2
#计算损失
loss = 0.5 * (y_pred - y_true) ** 2
#反向传播
#损失对输出梯度
dL_dy = y_pred - y_true
dy_dz2 = 1
#第二层输出梯度、权重梯度
dL_dz2 = dL_dy * dy_dz2
dL_dw2 = a1.T.dot(dL_dz2)
dL_db2 = dL_dz2
dL_da1 = dL_dz2.dot(w2.T)
da1_dz1 = (z1 > 0).astype(float) #relu激活函数导数
dL_dz1 = dL_da1 * da1_dz1
dL_dw1 = x.T(dL_dz1)
dL_db1 = dL_dz1
#手动更新参数(学习率 0.01)
lr = 0.01
w1 -= lr * dL_dw1
b1 -= lr * dL_db1
w2 -= lr * dL_dw2
b2 -= lr * dL_db2
六、用 PyTorch 实现并自动求梯度
第五章我们使用Python实现了两层神经网络的反向传播过程,虽然仅有两层,但是代码量还是很大的。接下来,我们来看看Pytroch内置的动态计算图来自动求导进行反向传播的代码,Pytorch 的 autograd会自动完成反向传播:
import torch
import torch.nn as nn
# 输入和标签
x = torch.tensor([[1.0, 2.0]], requires_grad=True)
y_true = torch.tensor([[1.0]])
# 定义模型
model = nn.Sequential(
nn.Linear(2, 3),
nn.ReLU(),
nn.Linear(3, 1)
)
# 损失函数
criterion = nn.MSELoss()
# 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 前向传播
y_pred = model(x)
loss = criterion(y_pred, y_true)
# 反向传播 + 更新
optimizer.zero_grad()
loss.backward()
optimizer.step()七、写在最后
以上就是BP的全部原理和具体实现。读到这里,相信小伙伴们都已经对BP有了很深的理解:BP就是利用链式规则自动计算梯度,来训练神经网络,进行参数更新,这是当前所有深度神经网络模型的参数优化规则,pytorch的计算图能够自动计算各参数梯度,更具模块化并且高效。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









