







问题:
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那两个整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/two-sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解答:
这道题有两种解决方法,一种是利用for循环暴力解决,另一种是利用哈希表的方法解决。显然,利用哈希表这种方法更好。
哈希表法解决思路:

简而言之,按照自己的思路:




哈希表方法比两层for循环快的多。两层for循环查找,时间复杂度是O(n^2),用哈希表的话, 只需要O(1)。当有大量数组时,时间复杂度体现的将更加明显。但是,哈希表法是以空间换时间的方法,因此内存占用也较多。
对应的编译器代码:
import java.util.Arrays;
public class Test{
public static void main(String[] args){
int[] arr = {2, 7, 11, 15};
int ret[] = twoSum(arr, 9);
System.out.println(Arrays.toString(ret));
}
public static int[] twoSum(int[] nums, int target){
int flag[] = new int[2];
for(int i = 0; i < nums.length; i++){
for(int j = i + 1; j < nums.length; j++){
if(nums[i] + nums[j] == target){
flag[0] = i;
flag[1] = j;
return flag;
}
}
}
return null;
}
}import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
public class TwoNumSum {
public static void main(String[] args) {
int[] arr = {2, 7, 11, 15};
int ret[] = twoSum(arr, 9);
System.out.println(Arrays.toString(ret));
}
public static int[] twoSum(int[] nums, int target) {
int[] flag = new int[2];
if(nums == null || nums.length == 0){
return flag;
}
Map<Integer, Integer> map = new HashMap<>();
for(int i = 0; i < nums.length; i++){
int temp = target - nums[i];
if(map.containsKey(temp)){
flag[1] = i;
flag[0] = map.get(temp);
}
map.put(nums[i], i);
}
return flag;
}
}
对于哈希表可能理解的还不够透彻,这里详细说明:
哈希表:
哈希表又名散列表,它的方法主要是通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
直接上一个简单易懂的图解:
例如要查询一个名字是否在这所学校里。
要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1) 就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
将学生姓名映射到哈希表上就涉及到了「hash function ,也就是哈希函数」。
哈希函数:
哈希函数,把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下表快速知道这位同学是否在这所学校里了。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。

如果hashCode得到的数值大于哈希表的大小了,也就是大于tableSize了,怎么办呢?
此时为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,就要我们就保证了学生姓名一定可以映射到哈希表上了。
此时问题又来了,哈希表我们刚刚说过,就是一个数组。
如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表同一个索引下表的位置。接下来就需要知道「哈希碰撞」
哈希碰撞:
如图所示,小李和小王都映射到了索引下表 1的位置,「这一现象叫做哈希碰撞」。
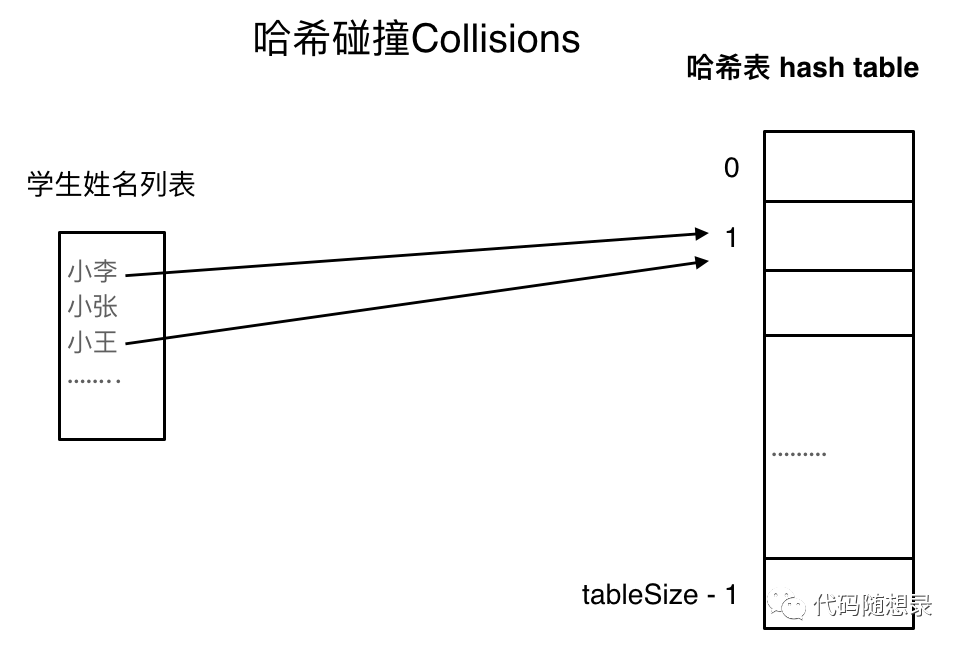
一般哈希碰撞有两种解决方法, 拉链法和线性探测法。
拉链法:
刚刚小李和小王在索引1的位置发生了冲突,发生冲突的元素都被存储在链表中。这样我们就可以通过索引找到小李和小王了。

(数据规模是dataSize, 哈希表的大小为tableSize)
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
线性探测法:
使用线性探测法,一定要保证tableSize大于dataSize。我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求tableSize一定要大于dataSize ,要不然哈希表上就没有空置的位置来存放 冲突的数据了。如图所示:

常见的三种哈希结构:
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
-
数组
-
set (集合)
-
map(映射)
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。















 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









