







一、引言
1.1. 日常生活中的机器学习
应用场景:
以智能语音助手(如Siri、Alexa)的唤醒词识别为例,麦克风采集的音频数据(每秒约4.4万次采样)无法通过传统编程直接关联到特定指令。机器学习通过分析大量标记数据(含/不含唤醒词的音频),自动构建输入(音频)到输出(是否触发)的映射关系。
图1.1.1 识别唤醒词

模型与参数:
模型是由参数控制的灵活算法,参数如同“旋钮”,调整模型行为。例如,同一模型族可适配不同唤醒词(“Alexa”或“Hey Siri”)。
数据集(dataset):批量数据样本;
模型(model):任一调整参数后的程序;
模型族:所有不同程序(输入-输出映射)的集合;
学习算法(learning algorithm):使用数据集来选择参数的元程序;
学习(learning):是一个训练(train)模型的过程;指自主提高模型完成某些任务的效能。
机器学习本质:
通过数据编程(Programming with Data),用数据集而非硬编码规则定义程序行为。例如,用大量猫狗图片训练分类器,使其输出区分两者的数值。
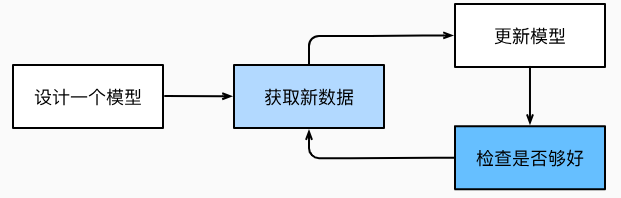
训练过程:
-
从一个随机初始化参数的“无智能”模型开始;
-
获取一些数据样本;
-
调整参数,使模型在这些样本中表现得更好;
-
重复第(2)步和第(3)步,直到模型在表现良好。
图1.1.2 一个典型的训练过程
.
1.2. 机器学习中的关键组件
机器学习的关键组件:
-
可以用来学习的数据(data);
-
如何转换数据的模型(model);
-
一个目标函数(objective function),用来量化模型的有效性;
-
调整模型参数以优化目标函数的算法(algorithm)。
.
1)数据
可以用来学习的数据(data);
每个数据集由一个个样本(example, sample) 组成,大多时候,它们遵循独立同分布(independently and identically distributed, i.i.d.)。
样本有时也叫做数据点(data point) 或 数据实例(data instance); 通常每个样本由一组称为特征(features,或协变量(covariates))的属性组成。 机器学习模型会根据这些属性进行预测。在上面的监督学习问题中,要预测的是一个特殊的属性,它被称为标签(label,或目标(target))。
当每个样本的特征类别数量都是相同时,其特征向量是定长的,这个长度被称为数据的维数 (dimensionality)。 固定长度的特征向量是一个方便的属性,它可以用来量化学习大量样本。
.
2)模型
转换数据的模型(model);
大多数机器学习会涉及到数据的转换。比如通过摄取到的一组传感器读数预测读数的正常与异常程度。
深度学习与经典方法的区别主要在于:前者关注的功能强大的模型,这些模型由神经网络错综复杂的交织在一起,包含层层数据转换,因此被称为深度学习(deep learning)。
.
3)目标函数
目标函数(objective function),用来量化模型的有效性;
“学习”是指自主提高模型完成某些任务的效能。
在机器学习中,我们需要定义模型的优劣程度的度量,这个度量在大多数情况是“可优化”的,这被称之为目标函数(objective function)。
我们通常定义一个目标函数,并希望优化它到最低点。 因为越低越好,所以这些函数有时被称为损失函数(loss function,或cost function)。 但这只是一个惯例,我们也可以取一个新的函数,优化到它的最高点。 这两个函数本质上是相同的,只是翻转一下符号。
当任务在试图预测数值时,最常见的损失函数是平方误差(squared error),即预测值与实际值之差的平方。 当试图解决分类问题时,最常见的目标函数是最小化错误率,即预测与实际情况不符的样本比例。
通常,损失函数是根据模型参数定义的,并取决于数据集。 在数据集上,通过最小化总损失来学习模型参数的最佳值。为训练而收集数据集,称为训练数据集(training dataset,或训练集(training set))。 然而,在训练数据上表现良好的模型,并不一定在“新数据集”上有同样的性能,这里的“新数据集”通常称为测试数据集(test dataset,或测试集(test set))。
当一个模型在训练集上表现良好,测试集上表现不好时,这个模型被称为**过拟合(overfitting)**的。
.
4)优化算法
当获得了一些数据源及其表示、一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。
深度学习中,大多流行的优化算法常基于的基本方法–-梯度下降(gradient descent)。 简而言之,在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。
.
声明:资源可能存在第三方来源,若有侵权请联系删除!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









