







1、基础前提——贝叶斯准则
- 贝叶斯准则的本质:使平均代价最小化,即 m i n R 1 C ‾ \underset{R_1}{min}\overline{C} R1minC
- 在已知先验分布的情况下,贝叶斯准则给出的平均错误代价为 C ‾ = ξ [ c 00 ( 1 − P F ) + c 10 P F ] + ( 1 − ξ ) [ c 01 P M + c 11 ( 1 − P M ) ] \overline{C}=\xi[c_{00}(1-P_F)+c_{10}P_F]+(1-\xi)[c_{01}P_M+c_{11}(1-P_M)] C=ξ[c00(1−PF)+c10PF]+(1−ξ)[c01PM+c11(1−PM)]
注意:
1、 P F P_F PF:虚报概率,且 P F = ∫ R 1 p 0 ( x ) d x P_F=\int_{R1}p_0(x)dx PF=∫R1p0(x)dx;
2、 P M P_M PM:漏报概率,且 P M = ∫ R 0 p 1 ( x ) d x P_M=\int_{R0}p_1(x)dx PM=∫R0p1(x)dx;
3、 c i j c_{ij} cij:发生事件 H j H_j Hj,判决器判为 D i D_i Di的代价因子,在二元数字通信系统中, i , j ∈ { 0 , 1 } i,j \in \lbrace{0,1\rbrace} i,j∈{0,1}
- 判决门限: λ 0 = ξ ( c 10 − c 00 ) ( 1 − ξ ) ( c 01 − c 11 ) \lambda_0=\frac{\xi(c_{10}-c_{00})}{(1-\xi)(c_{01}-c_{11})} λ0=(1−ξ)(c01−c11)ξ(c10−c00)
- 判决准则:
- 依据:似然比函数
λ
(
x
)
=
p
1
(
x
)
p
0
(
x
)
\lambda(x)=\frac{p_1(x)}{p_0(x)}
λ(x)=p0(x)p1(x)
①当 λ ( x ) > λ 0 \lambda(x)>\lambda_0 λ(x)>λ0,接收端的判决器判为 D 1 D_1 D1,即判断发送端发送的是1(事件: H 1 H_1 H1);
②当 λ ( x ) < λ 0 \lambda(x)<\lambda_0 λ(x)<λ0,接收端的判决器判为 D 0 D_0 D0,即判断发送端发送的是0(事件: H 0 H_0 H0);
- 依据:似然比函数
λ
(
x
)
=
p
1
(
x
)
p
0
(
x
)
\lambda(x)=\frac{p_1(x)}{p_0(x)}
λ(x)=p0(x)p1(x)
2、极小极大值准则
2.1 分析
1、贝叶斯准则是在已知先验分布的概率下得到的最小代价,即已知
p
(
H
1
)
=
1
−
ξ
,
p
(
H
0
)
=
ξ
p(H_1)=1-\xi,p(H_0)=\xi
p(H1)=1−ξ,p(H0)=ξ
2、如果先验分布未知,即
ξ
\xi
ξ是未知量时,最小化代价是多少?(代价因子
c
c
c已知)
2.2 先验概率未知下,最小代价的处理方法
- 1、先验概率未知,无法采用贝叶斯准则处理
- 2、如果假定先验概率并采用贝叶斯准则处理,则实际风险存在偏差,会导致风险增大,即代价会增加
- 3、两种策略:
- 使最差情况下的风险极小化(极小极大风险)
- 使偏差最小化(极小极大风险偏差)
2.3 以二元数字通信系统为例说明
例1:(二元数字通信系统)在时间间隔 T s内,要么发送一个幅度为d的脉冲,即有 s ( t ) = d s(t)=d s(t)=d,代表“1”;要么在该时间间隔内不发送信号,即为 s ( t ) = 0 s(t)=0 s(t)=0,代表“0”。
在接收机处,接收信号由发送信号和信道噪声( n ( t ) n(t) n(t))组成,即有 r ( t ) = s ( t ) + n ( t ) r(t)=s(t)+n(t) r(t)=s(t)+n(t)。依据对接收信号 r ( t ) r(t) r(t)的一次抽样检测(单样本检测)来判断是否发送的信号是否为 s ( t ) = d s(t)=d s(t)=d。
我们仍然以二元数字通信系统的例子为例,发送端发0或者1的概率密度函数如下图所示:
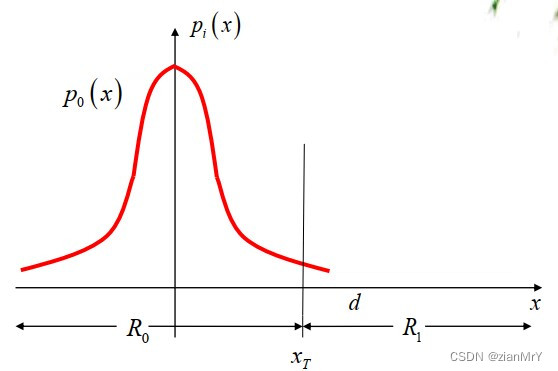
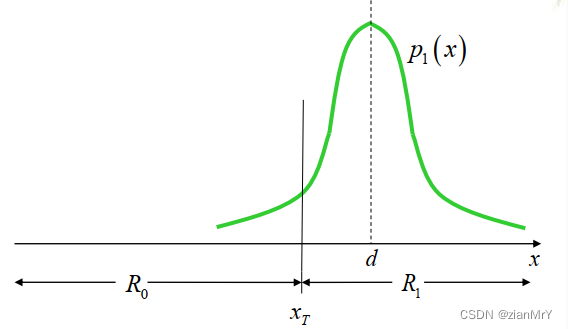
发送0 发送1
根据贝叶斯准则计算,最小代价为:
C
‾
m
i
n
=
ξ
[
c
00
∫
−
∞
x
T
p
0
(
x
)
d
x
+
c
10
∫
x
T
∞
p
0
(
x
)
d
x
]
+
(
1
−
ξ
)
[
c
01
∫
−
∞
x
T
p
1
(
x
)
d
x
+
c
11
∫
x
T
∞
p
1
(
x
)
d
x
]
\overline{C}_{min}=\xi[c_{00}\int_{-\infty}^{x_T}p_0(x)dx+c_{10}\int_{x_T}^{\infty}p_0(x)dx] \\ +(1-\xi)[c_{01}\int_{-\infty}^{x_T}p_1(x)dx+c_{11}\int_{x_T}^{\infty}p_1(x)dx]
Cmin=ξ[c00∫−∞xTp0(x)dx+c10∫xT∞p0(x)dx]+(1−ξ)[c01∫−∞xTp1(x)dx+c11∫xT∞p1(x)dx]
判决门限为:
λ
0
=
λ
(
x
T
)
=
p
1
(
x
)
p
0
(
x
)
=
ξ
(
c
10
−
c
00
)
(
1
−
ξ
)
(
c
01
−
c
11
)
\lambda_0=\lambda(x_T)=\frac{p_1(x)}{p_0(x)}=\frac{\xi(c_{10}-c_{00})}{(1-\xi)(c_{01}-c_{11})}
λ0=λ(xT)=p0(x)p1(x)=(1−ξ)(c01−c11)ξ(c10−c00)
当我们将判决域划分为: R 0 R_0 R0和 R 1 R_1 R1,且 R 0 R_0 R0和 R 1 R_1 R1为互备完斥集,则最小代价可以写成: C ‾ m i n = ξ [ c 00 ∫ R 0 p 0 ( x ) d x + c 10 ∫ R 1 p 0 ( x ) d x ] + ( 1 − ξ ) [ c 01 ∫ R 0 p 1 ( x ) d x + c 11 ∫ R 1 p 1 ( x ) d x ] \overline{C}_{min}=\xi[c_{00}\int_{R_0}p_0(x)dx+c_{10}\int_{R_1}p_0(x)dx] \\ +(1-\xi)[c_{01}\int_{R_0}p_1(x)dx+c_{11}\int_{R_1}p_1(x)dx] Cmin=ξ[c00∫R0p0(x)dx+c10∫R1p0(x)dx]+(1−ξ)[c01∫R0p1(x)dx+c11∫R1p1(x)dx]
其中,虚报概率: P F = ∫ R 1 p 0 ( x ) d x = 1 − ∫ R 0 p 0 ( x ) d x P_F=\int_{R_1}p_0(x)dx=1-\int_{R_0}p_0(x)dx PF=∫R1p0(x)dx=1−∫R0p0(x)dx;
漏报概率: P M = ∫ R 0 p 1 ( x ) d x = 1 − ∫ R 1 p 1 ( x ) d x P_M=\int_{R_0}p_1(x)dx=1-\int_{R_1}p_1(x)dx PM=∫R0p1(x)dx=1−∫R1p1(x)dx
检测概率: P D = ∫ R 1 p 1 ( x ) d x P_D=\int_{R_1}p_1(x)dx PD=∫R1p1(x)dx
- 由先验概率 ξ \xi ξ,可以确定判决域 R 1 R_1 R1,从而可以确定判决门限 λ 0 \lambda_0 λ0,也就是说,判决域和判决门限均由先验概率所确定;
- 在先验分布未知的情况下,将判决域视为关于先验概率 ξ \xi ξ的函数,从而虚报概率、漏报概率也为关于 ξ \xi ξ的函数,进而可以得到最小代价也是 ξ \xi ξ的函数,表示如下: C ‾ m i n ( ξ ) = ξ [ c 00 ( 1 − P F ( ξ ) ) + c 10 P F ( ξ ) ] + ( 1 − ξ ) [ c 01 P M ( ξ ) + c 11 ( 1 − P M ( ξ ) ) ] \overline{C}_{min}(\xi)=\xi[c_{00}(1-P_F(\xi))+c_{10}P_F(\xi)] \\ +(1-\xi)[c_{01}P_M(\xi)+c_{11}(1-P_M(\xi))] Cmin(ξ)=ξ[c00(1−PF(ξ))+c10PF(ξ)]+(1−ξ)[c01PM(ξ)+c11(1−PM(ξ))]
2.4 贝叶斯准则曲线
我们将最小代价描述为关于先验概率
ξ
\xi
ξ的函数,并用如下曲线表示函数:
C
‾
=
C
‾
m
i
n
(
ξ
)
\overline{C}=\overline{C}_{min}(\xi)
C=Cmin(ξ)

-
问题1:为什么 ξ = 0 \xi=0 ξ=0或 ξ = 1 \xi=1 ξ=1时,代价为0?
-
ξ = 0 \xi=0 ξ=0时,即发送端发送信号0的概率为0
判决门限 ξ = p 1 ( x ) p 0 ( x ) = ξ ( c 10 − c 00 ) ( 1 − ξ ) ( c 01 − c 11 ) = 0 \xi=\frac{p_1(x)}{p_0(x)}=\frac{\xi(c_{10}-c_{00})}{(1-\xi)(c_{01}-c_{11})}=0 ξ=p0(x)p1(x)=(1−ξ)(c01−c11)ξ(c10−c00)=0
接收端判决器全部判决为 D 1 D_1 D1,从而代价 C ‾ = 0 \overline{C}=0 C=0 -
ξ = 1 \xi=1 ξ=1时,即发送端发送信号0的概率为1
判决门限 ξ = p 1 ( x ) p 0 ( x ) = ξ ( c 10 − c 00 ) ( 1 − ξ ) ( c 01 − c 11 ) = ∞ \xi=\frac{p_1(x)}{p_0(x)}=\frac{\xi(c_{10}-c_{00})}{(1-\xi)(c_{01}-c_{11})}=\infty ξ=p0(x)p1(x)=(1−ξ)(c01−c11)ξ(c10−c00)=∞
接收端判决器全部判决为 D 0 D_0 D0,从而代价 C ‾ = 0 \overline{C}=0 C=0注意:判决正确视为没有代价,只有判决错误才会有代价
-
-
问题2:贝叶斯准则曲线为什么是凹函数(concave函数)?
- 数学中,判断函数凹凸性的办法主要有以下两个:
①根据二阶导函数判断,二阶导数小于0,则为凹函数;
②几何法:在函数曲线上任取两点,两点之间连成的线段总在曲线的下方 - 任取
ξ
1
∈
(
0
,
1
)
\xi_1\in(0,1)
ξ1∈(0,1),由
ξ
1
\xi_1
ξ1可以确定判决域和判决门限,从而可以得到确定的虚报概率
P
F
P_F
PF和漏报概率
P
M
P_M
PM。
实际情况下, ξ \xi ξ是系统真实的发送概率,且未知,而 ξ 1 \xi_1 ξ1只是我们猜测或者说假定的一个先验概率值
在这种猜测下,代价函数可以表示为:
C ‾ g u e s s ( ξ , ξ 1 ) = ξ [ c 00 ( 1 − P F ( ξ 1 ) ) + c 10 P F ( ξ 1 ) ] + ( 1 − ξ ) [ c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) ] \overline{C}_{guess}(\xi,\xi_1)=\xi[c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1)] \\ +(1-\xi)[c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1))] Cguess(ξ,ξ1)=ξ[c00(1−PF(ξ1))+c10PF(ξ1)]+(1−ξ)[c01PM(ξ1)+c11(1−PM(ξ1))]
令 C H 0 = c 00 ( 1 − P F ( ξ 1 ) ) + c 10 P F ( ξ 1 ) C_{H_0}=c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1) CH0=c00(1−PF(ξ1))+c10PF(ξ1),
C H 1 = c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) C_{H_1}=c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1)) CH1=c01PM(ξ1)+c11(1−PM(ξ1))
则代价函数可以表示成:
C ‾ g u e s s ( ξ , ξ 1 ) = ξ C H 0 + ( 1 − ξ ) C H 1 = C H 1 + ξ ( C H 0 − C H 1 ) \overline{C}_{guess}(\xi,\xi_1)=\xi C_{H_0} +(1-\xi)C_{H_1}=C_{H_1}+\xi(C_{H_0}-C_{H_1}) Cguess(ξ,ξ1)=ξCH0+(1−ξ)CH1=CH1+ξ(CH0−CH1)
上述函数为过点 ( ξ 1 , C ‾ ( ξ 1 ) ) (\xi_1,\overline{C}(\xi_1)) (ξ1,C(ξ1)) 所做出的一条直线,当 ξ ≠ ξ 1 \xi\neq\xi_1 ξ=ξ1时,采用的为非贝叶斯准则的判决方式,所造成的代价会增大,所以直线 C ‾ g u e s s ( ξ , ξ 1 ) \overline{C}_{guess}(\xi,\xi_1) Cguess(ξ,ξ1)会始终在贝叶斯准则曲线的上方,即曲线始终在直线的一侧。

注意:
如果我们采用的不是似然比检测器 λ ( x ) = p 1 ( x ) p 0 ( x ) \lambda(x)=\frac{p_1(x)}{p_0(x)} λ(x)=p0(x)p1(x),采用的是其它类型的检测器,猜测的先验概率下的代价函数 C ‾ g u e s s ( ξ , ξ 1 ) = ξ C H 0 + ( 1 − ξ ) C H 1 = C H 1 + ξ ( C H 0 − C H 1 ) \overline{C}_{guess}(\xi,\xi_1)=\xi C_{H_0} +(1-\xi)C_{H_1}=C_{H_1}+\xi(C_{H_0}-C_{H_1}) Cguess(ξ,ξ1)=ξCH0+(1−ξ)CH1=CH1+ξ(CH0−CH1)在 ξ − C ‾ \xi-\overline{C} ξ−C坐标轴上该如何画?
解答:
若采用的贝叶斯准则,则直线与贝叶斯准则曲线有交点;若采用的不是贝叶斯准则,则直线一定在贝叶斯准则曲线的上方。
原因:
一方面,似然比检测器是将接收到的实际变量一对一的映射为似然比;另一方面,贝叶斯准则是最小代价准则,其他准则所产生的代价不可能比贝叶斯准则下检测器所产生的代价小
- 数学中,判断函数凹凸性的办法主要有以下两个:
2.5 猜测先验分布下,代价随 ξ \xi ξ的变化趋势。
- 当猜测代价函数的斜率不为0时,具体如下图:
当 ξ = ξ 1 \xi=\xi_1 ξ=ξ1时,该点的代价刚好对应贝叶斯准则曲线上的一点,在所有准则中代价最小;
当 ξ : ξ 1 → 0 \xi:\xi_1\rightarrow0 ξ:ξ1→0, C ‾ = C ‾ g u e s s ( ξ , ξ 1 ) \overline{C}=\overline{C}_{guess}(\xi,\xi_1) C=Cguess(ξ,ξ1)曲线与 C ‾ = C ‾ m i n ( ξ ) \overline{C}=\overline{C}_{min}(\xi) C=Cmin(ξ)曲线代价偏差逐渐增大,当 ξ = 0 \xi=0 ξ=0时,达到极大偏差;
当 ξ : ξ 1 → 1 \xi:\xi_1\rightarrow1 ξ:ξ1→1, C ‾ = C ‾ g u e s s ( ξ , ξ 1 ) \overline{C}=\overline{C}_{guess}(\xi,\xi_1) C=Cguess(ξ,ξ1)曲线与 C ‾ = C ‾ m i n ( ξ ) \overline{C}=\overline{C}_{min}(\xi) C=Cmin(ξ)曲线代价偏差逐渐增大,当 ξ = 1 \xi=1 ξ=1时,达到最大偏差; - 当猜测函数斜率为0时,即无论
ξ
\xi
ξ如何变换,猜测的先验分布下代价均不变,如下图所示:

猜测先验分布下的代价函数:
C ‾ g u e s s ( ξ , ξ 1 ) = ξ C H 0 + ( 1 − ξ ) C H 1 = C H 1 + ξ ( C H 0 − C H 1 ) \overline{C}_{guess}(\xi,\xi_1)=\xi C_{H_0} +(1-\xi)C_{H_1}=C_{H_1}+\xi(C_{H_0}-C_{H_1}) Cguess(ξ,ξ1)=ξCH0+(1−ξ)CH1=CH1+ξ(CH0−CH1)
其中, C H 0 = c 00 ( 1 − P F ( ξ 1 ) ) + c 10 P F ( ξ 1 ) C_{H_0}=c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1) CH0=c00(1−PF(ξ1))+c10PF(ξ1),
C H 1 = c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) C_{H_1}=c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1)) CH1=c01PM(ξ1)+c11(1−PM(ξ1))
此时, ξ = 0 \xi=0 ξ=0或 ξ = 1 \xi=1 ξ=1时所产生的代价相等,即:
C H 0 = C H 1 C_{H_0}=C_{H_1} CH0=CH1
根据上述式子,可以解出对应的 ξ 1 \xi_1 ξ1,且满足 ξ 1 = ξ 0 \xi_1=\xi_0 ξ1=ξ0,此时代价函数简化为 C ‾ g u e s s ( ξ , ξ 1 ) = C H 1 \overline{C}_{guess}(\xi,\xi_1)=C_{H_1} Cguess(ξ,ξ1)=CH1
该情况对应的准则又叫等风险准则
注意:极小极大准则不是概率意义上的偏差最小,因此不是概率意义上的最优
Δ C ( ξ , ξ 1 ) = C m i n ( ξ ) − C m i n ( ξ , ξ 1 ) \Delta{C}(\xi,\xi_1)=C_{min}(\xi)-C_{min}(\xi,\xi_1) ΔC(ξ,ξ1)=Cmin(ξ)−Cmin(ξ,ξ1)
∫ p ( ξ ) Δ C ( ξ , ξ 1 ) d ξ → m i n \int p(\xi)\Delta C(\xi,\xi_1)d\xi \rightarrow min ∫p(ξ)ΔC(ξ,ξ1)dξ→min
3、极小极大风险准则面对的几种情况
注意:贝叶斯准则下的最小代价为: C ‾ m i n ( ξ ) = ξ [ c 00 ( 1 − P F ( ξ ) ) + c 10 P F ( ξ ) ] + ( 1 − ξ ) [ c 01 P M ( ξ ) + c 11 ( 1 − P M ( ξ ) ) ] \overline{C}_{min}(\xi)=\xi[c_{00}(1-P_F(\xi))+c_{10}P_F(\xi)] \\ +(1-\xi)[c_{01}P_M(\xi)+c_{11}(1-P_M(\xi))] Cmin(ξ)=ξ[c00(1−PF(ξ))+c10PF(ξ)]+(1−ξ)[c01PM(ξ)+c11(1−PM(ξ))]
当 ξ = 0 \xi=0 ξ=0, P M ( ξ ) = 0 ⇒ C ‾ m i n ( ξ ) = c 11 P_M(\xi)=0\Rightarrow\overline{C}_{min}(\xi)=c_{11} PM(ξ)=0⇒Cmin(ξ)=c11;
当 ξ = 1 \xi=1 ξ=1, P F ( ξ ) ) = 0 ⇒ C ‾ m i n ( ξ ) = c 00 P_F(\xi))=0\Rightarrow\overline{C}_{min}(\xi)=c_{00} PF(ξ))=0⇒Cmin(ξ)=c00
3.1 代价: c 00 = c 11 = 0 c_{00}=c_{11}=0 c00=c11=0
C
H
0
=
c
00
(
1
−
P
F
(
ξ
1
)
)
+
c
10
P
F
(
ξ
1
)
=
c
10
P
F
(
ξ
1
)
C_{H_0}=c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1)=c_{10}P_F(\xi_1)
CH0=c00(1−PF(ξ1))+c10PF(ξ1)=c10PF(ξ1)
C
H
1
=
c
01
P
M
(
ξ
1
)
+
c
11
(
1
−
P
M
(
ξ
1
)
)
=
c
01
P
M
(
ξ
1
)
C_{H_1}=c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1))=c_{01}P_M(\xi_1)
CH1=c01PM(ξ1)+c11(1−PM(ξ1))=c01PM(ξ1)

3.2 代价: c 00 = c 11 ≠ 0 c_{00}=c_{11}\neq0 c00=c11=0

3.3 代价: c 00 ≠ c 11 c_{00}\neq c_{11} c00=c11

此时,当
ξ
=
0
\xi=0
ξ=0与
ξ
=
1
\xi=1
ξ=1时,偏差不相同。我们转动猜测代价函数所表示的直线,改变其斜率,使其斜率为:
k
=
c
00
−
c
11
1
−
0
k=\frac{c_{00}-c_{11}}{1-0}
k=1−0c00−c11
改变后的猜测代价函数直线与贝叶斯准则曲线的交点在
ξ
1
≠
ξ
0
\xi_1\neq\xi_0
ξ1=ξ0处,且最大偏差比原来小,具体如下图所示:

- 如何确定该直线的斜率?
猜测代价函数:
C ‾ g u e s s ( ξ , ξ 1 ) = ξ [ c 00 ( 1 − P F ( ξ 1 ) ) + c 10 P F ( ξ 1 ) ] + ( 1 − ξ ) [ c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) ] = c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) + ξ [ c 00 ( 1 − P F ( ξ 1 ) ) + c 10 P F ( ξ 1 ) − [ c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) ] ] \overline{C}_{guess}(\xi,\xi_1)=\xi[c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1)] \\ +(1-\xi)[c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1))] \\=c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1)) \\ +\xi [c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1)-[c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1))]] Cguess(ξ,ξ1)=ξ[c00(1−PF(ξ1))+c10PF(ξ1)]+(1−ξ)[c01PM(ξ1)+c11(1−PM(ξ1))]=c01PM(ξ1)+c11(1−PM(ξ1))+ξ[c00(1−PF(ξ1))+c10PF(ξ1)−[c01PM(ξ1)+c11(1−PM(ξ1))]]
从函数中可以得到,直线的斜率:
k = c 00 ( 1 − P F ( ξ 1 ) ) + c 10 P F ( ξ 1 ) − [ c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) ] = 虚线斜率 = c 00 − c 11 1 − 0 k=c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1)-[c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1))] \\ =虚线斜率 \\=\frac{c_{00}-c_{11}}{1-0} k=c00(1−PF(ξ1))+c10PF(ξ1)−[c01PM(ξ1)+c11(1−PM(ξ1))]=虚线斜率=1−0c00−c11 - 由上述有关斜率的关系式可以得到:
等风险偏差策略:
c 00 ( 1 − P F ( ξ 1 ) ) + c 10 P F ( ξ 1 ) − c 00 = c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) − c 11 c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1)-c_{00}=c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1))-c_{11} c00(1−PF(ξ1))+c10PF(ξ1)−c00=c01PM(ξ1)+c11(1−PM(ξ1))−c11
4、极小极大准则总结
| 准则 | 对应的策略 |
|---|---|
| 极小极大偏差 | 等风险偏差策略 |
| 极小极大代价 | 等风险策略 |
注意:当 c 00 = c 11 c_{00}=c_{11} c00=c11时,极小极大代价 ⟺ \Longleftrightarrow ⟺极小极大偏差,即二者等价
例1:二元数字通信系统(一次观测)
根据一次观测,用极小极大准则对下面两个假设做出判断:
H
1
:
r
(
t
)
=
1
+
n
(
t
)
H
0
:
r
(
t
)
=
n
(
t
)
H_1:r(t)=1+n(t) \\ H_0:r(t)=n(t)
H1:r(t)=1+n(t)H0:r(t)=n(t)
其中,
n
(
t
)
n(t)
n(t)为零均值,方差为
σ
2
\sigma^2
σ2的高斯过程,且
c
00
=
c
11
c_{00}=c_{11}
c00=c11,
c
10
=
c
01
=
1
c_{10}=c_{01}=1
c10=c01=1。根据观测结果定出的判决门限是多少?给出的判决门限猜测的先验概率
ξ
1
\xi_1
ξ1是多少?
-
答:根据极小极大准则,可以得出: c 00 ( 1 − P F ( ξ 1 ) ) + c 10 P F ( ξ 1 ) − c 00 = c 01 P M ( ξ 1 ) + c 11 ( 1 − P M ( ξ 1 ) ) − c 11 c_{00}(1-P_F(\xi_1))+c_{10}P_F(\xi_1)-c_{00}=c_{01}P_M(\xi_1)+c_{11}(1-P_M(\xi_1))-c_{11} c00(1−PF(ξ1))+c10PF(ξ1)−c00=c01PM(ξ1)+c11(1−PM(ξ1))−c11
由于 c 00 = c 11 c_{00}=c_{11} c00=c11, c 10 = c 01 = 1 c_{10}=c_{01}=1 c10=c01=1,可以得到: P F ( ξ 1 ) = P M ( ξ 1 ) P_F(\xi_1)=P_M(\xi_1) PF(ξ1)=PM(ξ1)
其中, P F = P ( D 1 ∣ H 0 ) = ∫ R 1 p 0 ( x ) d x = ∫ x T ∞ p 0 ( x ) d x P_F=P(D_1|H_0)=\int_{R_1}p_0(x)dx=\int_{x_T}^{\infty}p_0(x)dx PF=P(D1∣H0)=∫R1p0(x)dx=∫xT∞p0(x)dx
P M = P ( D 0 ∣ H 1 ) = ∫ R 0 p 1 ( x ) d x = ∫ − ∞ x T p 1 ( x ) d x P_M=P(D_0|H_1)=\int_{R_0}p_1(x)dx=\int_{-\infty}^{x_T}p_1(x)dx PM=P(D0∣H1)=∫R0p1(x)dx=∫−∞xTp1(x)dx
将 p 0 ( x ) = 1 ( 2 π ) 1 / 2 σ e − x 2 2 σ 2 p_0(x)=\frac{1}{(2\pi)^{1/2}\sigma}e^{-\frac{x^2}{2 \sigma^2}} p0(x)=(2π)1/2σ1e−2σ2x2, p 1 ( x ) = 1 ( 2 π ) 1 / 2 σ e − ( x − 1 ) 2 2 σ 2 p_1(x)=\frac{1}{(2\pi)^{1/2}\sigma}e^{-\frac{(x-1)^2}{2 \sigma^2}} p1(x)=(2π)1/2σ1e−2σ2(x−1)2代入,根据正态分布的对称性,可以解得判决门限: x T = 1 2 x_T=\frac12 xT=21
进一步,可以得到: λ ( x T ) = p 1 ( x T ) p 0 ( x T ) = ξ ( c 10 − c 00 ) ( 1 − ξ ) ( c 01 − c 11 ) = ξ 1 − ξ = 1 \lambda(x_T)=\frac{p_1(x_T)}{p_0(x_T)}=\frac{\xi(c_{10}-c_{00})}{(1-\xi)(c_{01}-c_{11})}=\frac{\xi}{1-\xi}=1 λ(xT)=p0(xT)p1(xT)=(1−ξ)(c01−c11)ξ(c10−c00)=1−ξξ=1
解得,对应的先验概率为: ξ = 1 2 \xi=\frac12 ξ=21
例2:在例1基础上,假定 c 10 = 3 , c 01 = 6 c_{10}=3,c_{01}=6 c10=3,c01=6
问题1:每个假设的先验概率为何值时达到最大的可能代价?
问题2:根据一次观测的判决域如何?
-
答:平均代价: C ‾ = c 10 P F + c 01 P M \overline{C}=c_{10}P_F+c_{01}P_M C=c10PF+c01PM
根据等风险准则,得到: c 10 P F = c 01 P M c_{10}P_F=c_{01}P_M c10PF=c01PM,即: P F = 2 P M P_F=2P_M PF=2PM,可以得到关系式:∫ x T ∞ p 0 ( x ) d x = 2 ∗ ∫ − ∞ x T p 1 ( x ) d x \int_{x_T}^{\infty}p_0(x)dx=2*\int_{-\infty}^{x_T}p_1(x)dx ∫xT∞p0(x)dx=2∗∫−∞xTp1(x)dx
⇒ \Rightarrow ⇒ ∫ x T ∞ 1 2 π σ e − x 2 2 σ 2 d x = 2 ∗ ∫ − ∞ x T 1 2 π σ e − ( x − 1 ) 2 2 σ 2 d x \int_{x_T}^{\infty}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{x^2}{2 \sigma^2}}dx=2*\int_{-\infty}^{x_T}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-1)^2}{2 \sigma^2}}dx ∫xT∞2πσ1e−2σ2x2dx=2∗∫−∞xT2πσ1e−2σ2(x−1)2dx
⇒ \Rightarrow ⇒ ∫ x T σ ∞ 1 2 π e − x 2 2 d x = 2 ∗ ∫ − ∞ x T − 1 σ 1 2 π e − x 2 2 d x \int_{\frac{x_T}{\sigma}}^{\infty}\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2 }}dx=2*\int_{-\infty}^{\frac{x_T-1}{\sigma}}\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2 }}dx ∫σxT∞2π1e−2x2dx=2∗∫−∞σxT−12π1e−2x2dx
当 σ 2 = 1 \sigma^2=1 σ2=1,可以解得: x T = 0.196937 ≈ 0.2 x_T=0.196937\approx0.2 xT=0.196937≈0.2
进一步可得到: λ ( x T ) = p 1 ( x T ) p 0 ( x T ) = 0.738553 = ξ ( c 10 − c 00 ) ( 1 − ξ ) ( c 01 − c 11 ) = ξ 2 ( 1 − ξ ) \lambda(x_T)=\frac{p_1(x_T)}{p_0(x_T)}=0.738553=\frac{\xi(c_{10}-c_{00})}{(1-\xi)(c_{01}-c_{11})}=\frac{\xi}{2(1-\xi)} λ(xT)=p0(xT)p1(xT)=0.738553=(1−ξ)(c01−c11)ξ(c10−c00)=2(1−ξ)ξ
解得: ξ ≈ 0.5963 \xi \approx 0.5963 ξ≈0.5963,即 p ( H 0 ) = 0.5963 p(H_0)=0.5963 p(H0)=0.5963


















 3475
3475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











