







梯度下降法
(一)目的和原因
目的: 是一个通用的优化算法来帮助一些机器学习算法求解出最优解的,用于以最快的速度把模型参数θ求解出来。
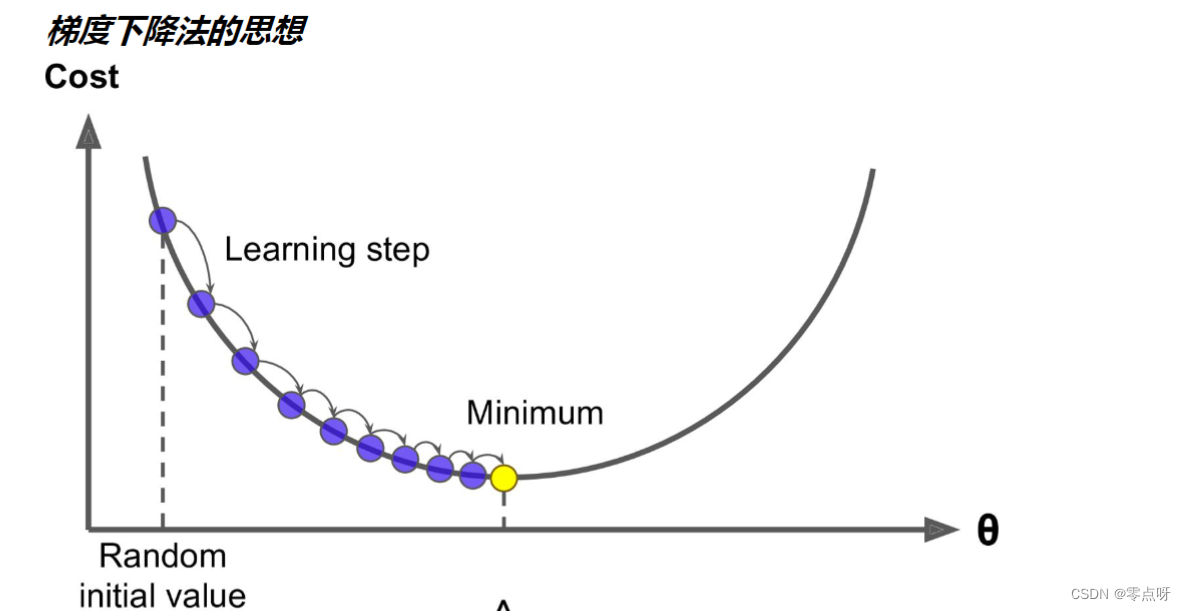
原因:
1.之前利用θ的解析解公式求解出来的解我们就直接说是最优解的一个原因是因为 MSE这个损失函数是凸函数,但是如果我们机器学习的损失函数是非凸函数的话,设置梯度为 0会得到很多个极值,甚至是极大值都有可能。
2. 之前利用θ的解析解公式求解的另一个原因是特征维度并不多,当维度多时计算复杂
(二)公式与理解

求解步骤:

全量梯度下降
(一)公式与理解

随机梯度下降

梯度下降法的困难与挑战
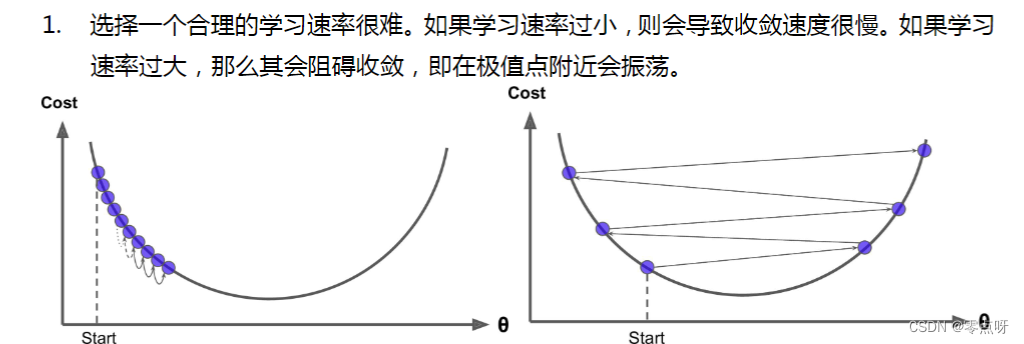

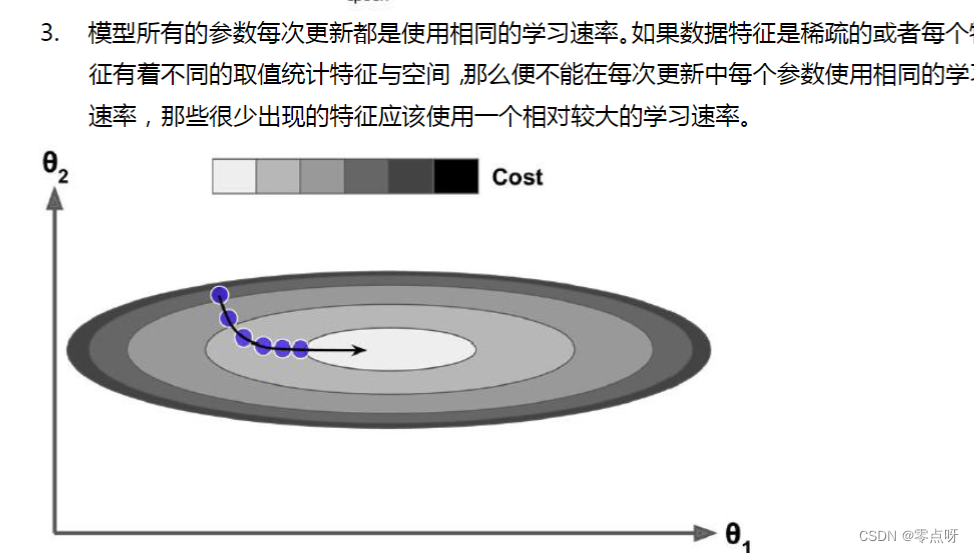
代码实战梯度下降法与优化
(一)全量梯度下降法
import numpy as np
import matplotlib.pyplot as plt
"""
全梯度下降法
"""
np.random.seed(1)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
learning_rate = 0.001 #创建一个学习率
n_iterations = 10000
# 1,初始化 theta,w0...wn,正太分布创建 W
theta = np.random.randn(2, 1)
# 4,不会设置阈值,直接设置超参数,迭代次数,迭代次数到了,我们就认为收敛了
for _ in range(n_iterations):
# 2,接着求梯度 gradient
gradients = X_b.T.dot(X_b.dot(theta)-y)
# 3,应用公式调整 theta 值,theta_t + 1 = theta_t - grad * learning_rate
theta = theta - learning_rate * gradients
(二)随机梯度下降法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









