









作用
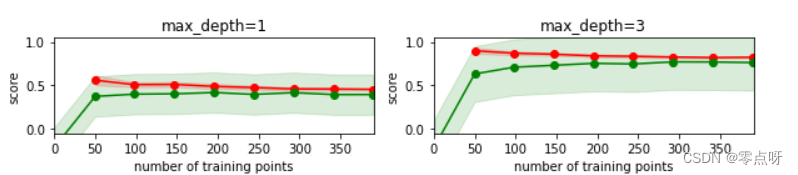
learning_curve() 是一个可视化工具,用于评估机器学习模型的性能和训练集大小之间的关系。它可以帮助我们理解模型在不同数据规模下的训练表现,进而判断模型是否出现了欠拟合或过拟合的情况。
该函数会生成一条曲线,横轴表示不同大小的训练集,纵轴表示训练集和交叉验证集上的评估指标(例如准确率、损失等)。通过观察曲线,我们可以得出以下结论:
- 训练集误差和交叉验证集误差之间的关系:当训练集规模较小时,模型可能过度拟合,训练集误差较低,交叉验证集误差较高;当训练集规模逐渐增大时,模型可能更好地泛化,两者的误差逐渐趋于稳定。
- 训练集误差和交叉验证集误差对训练集规模的响应:通过观察曲线的斜率,我们可以判断模型是否存在高方差(过拟合)或高偏差(欠拟合)的问题。如果训练集和交叉验证集的误差都很高,且二者之间的间隔较大,说明模型存在高偏差;如果训练集误差很低而交叉验证集误差较高,且二者的间隔也较大,说明模型存在高方差。
通过learning_curve() 可以直观地了解模型的性能和训练集规模之间的关系,可以帮助我们进行模型选择、调优、判断是否需要增加更多的数据来改善模型性能。
常见参数
-
X:特征矩阵,包含输入样本的特征。
-
y:目标变量,包含与输入样本对应的真实标签。
-
train_sizes:一个数组或可迭代对象,表示训练集的不同大小的比例。每个比例都将生成一个学习曲线点。
-
cv:用于交叉验证的折数或交叉验证迭代器。
-
scoring:用于评估模型性能的指标。常见的指标包括准确率(accuracy)、均方误差(mean_squared_error)、R平方(r2_score)等。
-
shuffle:是否在每次迭代前对数据进行洗牌,默认为False。
-
random_state:随机数种子,用于控制随机性。
-
estimator:用于拟合数据的机器学习模型,例如分类器或回归器。
-
X:特征矩阵,包含输入样本的特征。
-
y:目标变量,包含与输入样本对应的真实标签。
-
train_sizes:一个数组或可迭代对象,表示训练集的不同大小的比例。每个比例都将生成一个学习曲线点。
-
cv:用于交叉验证的折数或交叉验证迭代器。
-
scoring:用于评估模型性能的指标。常见的指标包括准确率(accuracy)、均方误差(mean_squared_error)、R平方(r2_score)等。
-
shuffle:是否在每次迭代前对数据进行洗牌,默认为False。
-
random_state:随机数种子,用于控制随机性。
返回值
-
train_sizes_abs:一个数组,表示每个训练集大小对应的实际样本数量。
-
train_scores:一个二维数组,表示每个训练集大小下的训练集评分。
-
test_scores:一个二维数组,表示每个训练集大小下的交叉验证集评分。
-
fit_times:一个一维数组,表示每个训练集大小下模型拟合的耗时。
-
score_times:一个一维数组,表示每个训练集大小下进行评估的耗时。
-
这些返回值可以用于绘制学习曲线图、分析模型的性能以及选择模型等。















 6981
6981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









