






目录
一、字符串的常用操作(续)
1、判断操作
常用的判断操作有:
(1)isidentifier函数
这个函数的作用是判断字符串是否合法。格式如下图:

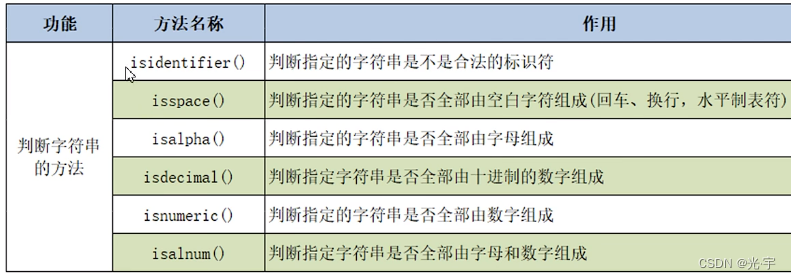
(2)isspace函数
判断一个字符串是否是全部由空白字符组成的,空白字符包括回车、换行和水平制表符。
(3)isalpha函数
判断字符是否全部由字母组成。

(4)isdecimal函数
判断字符是否全由数字组成,这里的数字只是1234567890这种数字,其他的表示数字的东西都不行。

(5)isnumeric函数
判断字符是否全由数字组成,这里的“数字”指的是所有表示数字的东西都可以。比如汉字的一二三四。。。。。还有罗马数字等等。

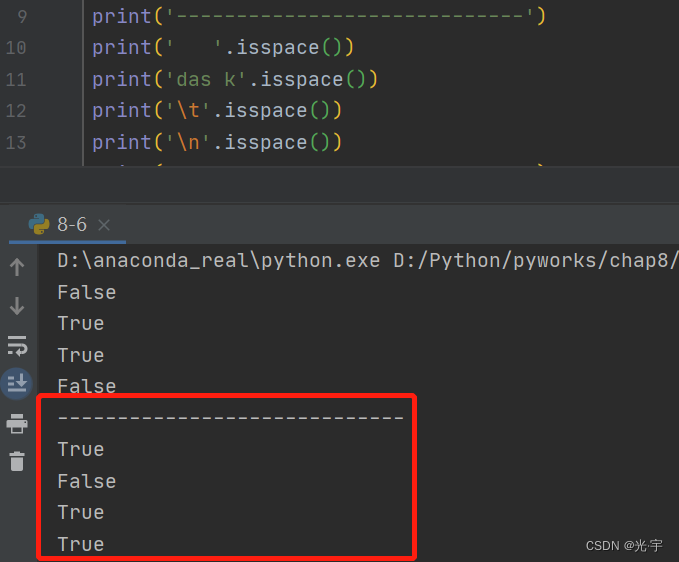
(6)isalnum函数
判断字符串是否全部由字母和数字组成。
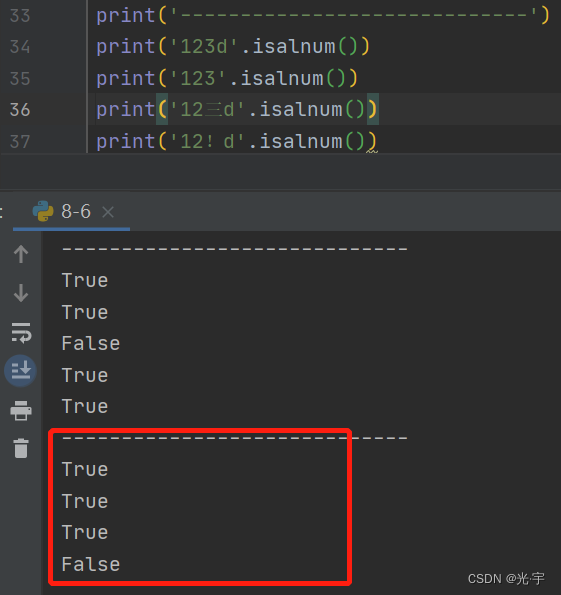
汉子也包括在字母里面,但是叹号、问号这种符号就不行了。
2、替换和合并操作

字符串的替换操作用的是replace函数,它一共包含3个参数,第一个参数是指定被替换的子串,第二个参数指定替换子串的字符串,第三个参数可以指定最大替换次数。

字符串的合并操作用的是join函数,它是将列表或元组中的字符串合并成一个新的字符串。

二、字符串的比较

上图中的运算符主要比较的是字符串的值,而is主要比较的是字符串的id。比较原理中的ord可以计算出字符的ordinal value它有点像C语音中的阿斯科码,然后chr函数可以对ordinal value进行反向求解,以求解出ordinal value对应的字符。这里使用=,>。。。这些符号比较得就是字符的ordinal value。

三、字符串的切片操作
进行切片操作时,我们要注意,字符串是不可变类型,因此不具备增删改操作,因此切片操作后将产生新的对象。
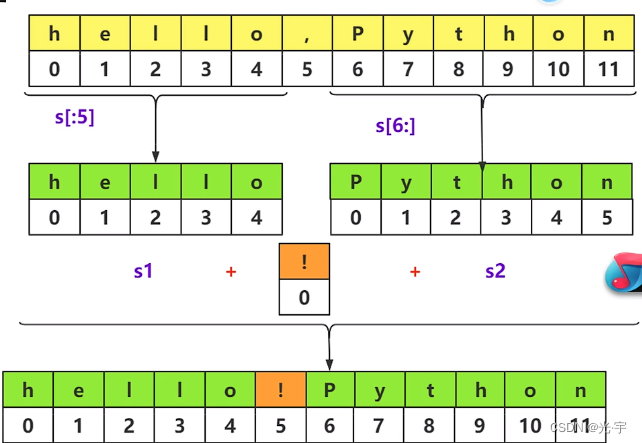
字符串切片示意图如下:
示例:
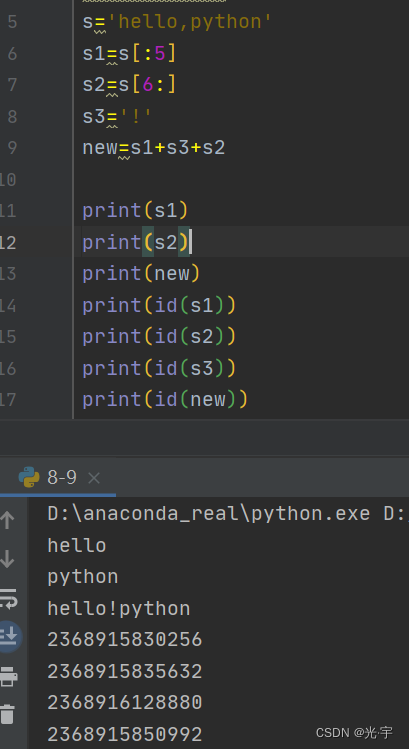
这里的切片操作和之前在列表那离学的切片操作是一样的,仍然是用中括号和冒号来切片,格式是“[start:stop:step]”从start开始到stop-1结束,步长是step,这里面的值也可以是负的,那也就是从后往前进行操作了。
四、格式化字符串
1、为何要格式化字符串
我们可以将这个问题在实际问题中考虑它,比如现在疫情阶段的话,上班上学的时候优有可能需要开具什么证明,如图所示:

这个其实就是个格式文件,里面有的东西是可变的,有的东西是不变的,其实呢这就是字符串的拼接操作,大致的思路就是不变部分的字符串与可变部分进行交互拼接就可以生成这样的一个文件。
2、格式化字符串的两种方式
(1)%作占位符


%s表示的是字符串,%d表示数字,%f表示浮点数的占位符,跟C语言比较相似。
在Python中使用%定义输出字符的长度和精度也与C语言类似:

“%10d”表示的是长度为10的整数占位符,他输出出来的整数必定是占10位的。
“%.3f:”表示的是保留三位小数的小数占位符,他输出出来的小数无论原本是有几位小数,他输出出来必定是只保留三位小数的。
“%10.3f:”表示的是长度为10,保留3为小数的小数占位符。
(2){}作占位符

示例里面有两种使用花括号格式化的方法,前面使用花括号需要与format函数进行配合;后者别忘了加f。

在Pyhon中使用{}也可以定义输出字符的长度和精度:

如图所示,第五行的写法意思是format里面的第一个数据保留3位小数进行输出。第六行的话是将0省略了,因为format里面就一个数据,因此肯定默认从第0个开始了。第七行写法意思是format里面的第一个数据保留3位小数且长度为10进行输出。第九行是分别将format里面的第一个和第二个数据保留3位小数进行输出,想更改操作数据的话,更改花括号里面冒号前面的数字就行了,因为那个表示的就是索引。
五、字符串的编码转换
1、为什么要编码转换?

AB两个机子之间进行数据传输时是以二进制进行传输的,因此要先进行编码,到了B机子后需要对其进行解码。

2、编码解码
(1)常用的编码格式
作为计算机交流的语言,字体编码在文字的显示方面发挥着重大的作用。下面介绍一下不同的字体格式以及之间的转换方法。
ANSII编码
作为最早的编码方法,ASCII是最基础的编码方法。ASCII码最早只有后7位可以使用,被编码成指令、标点、数字与英文字母,因此这种编码方法叫做"American Standard Code for Infomation Intechange"。由于其它国家使用ASCII码时不存在本国家的字母符号,因此ASCII码发生了扩展,最高一位也用来编码。于是将128到255的编码称为“扩展字符集”。
GB2312
GB2312是对ASCII编码的中文扩展。为了表示汉字,决定不使用ASCII码的扩展字符集,而将128到255的内容进行重新编码,并用两个字节来表示汉字。因此0~127的意义不变,当两个大于128的字节放在一起时就表示一个中文,其中高字节用0xA1~0xF7编码,低字节用0xA1~0xFE。在这些编码中,还包括数字符号、罗马字母、希腊字母以及日语的假名。对于标点符号也用了两个字节编码,形成了全角符号。后来为了增大容量,同样要求高字节用大于127的字符,但后一个字节没有了限制,这种编码方法称为GBK编码,其保留了GB2312的所有码字匹配。
Unicode
由于不同字体符号各有各的编码方法,因此难于交流。ISO(国际标准化组织)决定解决这个问题,提出一种统一的编码方式。这种编码方法使用两个字节,也就是一个unicode字符占用两个字节。对于ASCII编码,Uincode保留了下来,并用两个字节来表示,因此高位字节为0。由于是重新编码,因此GBK与Unicode编码是不兼容的,必须通过查表进行转换。
UTF-8
由于计算机的兴起,需要一种编码方法能够对Unicode码进行高效的传输,因此就提出了UTF-8的编码方法,一次传输8位,其实Unicode编码的一种对应编码,编码方法如下:如果一个Unicode在0x0000-007F之间,则编码成0xxxxxxxx,其中x为原来的Unicode码,其它的编码方法为0x0080~0x07FF(Unicode)->110xxxxx 10xxxxxx(UTF-8),0x0800~0xFFFF(Unicode)->(1110xxxx 10xxxxxx 10xxxxxx)(UTF-8)。因此对于不同的Unicode编码,UTF-8用1个,2个或3个字节表示。
(2)编码示例

这里用的GBK编码是一个中文占两个字节,因此我们能看到控制台第二行的b’意思是二进制,后面的\.......一共有10组,这就说明“天涯共此时”被编码成了10个字节;同理控制台的最后一行也是,使用UTF-8编码的话是将每个中文转为3个字节,因此我们能看到控制台第三行的b’意思是二进制,后面的\.......一共有15组,这就说明“天涯共此时”被编码成了15个字节。
(3)解码示例

这里的话进行解码时,当时用得什么编码格式编码后来就得用什么格式来解码,不然就会报错。
本章总结
















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











