







Python入门基础
- 声明:本文作为学习记录,如有侵权请联系本人进行删除
- 本文使用的IDE是PyCharm Community Edition 2022.1.3 下载地址
- 本文使用的Python版本python 3.10 下载地址
- 本文观看B站教学视频,跟着手打出来的。部分内容是复制其他链接上的。已给出参考链接。
- 本文中出现错误的内容,请指正。
- 持续在更新中…
- 群名称:小白Python交流群 群 号:912477250 (完全小白交流群没有任何商业。纯属交流群。)
文章目录
切片操作
- 语法:[start: end: step]
- 语法讲解:其中start是开始索引,end是结束索引,step是步长(切片时获取的元素的间隔,可以为正整数,也可以为负整数)。step就是去除等步长的元素
- 顾头不顾尾
- ==重点:==字符串、列表、元组可以进行切片。元组、集合不能进行切片操作。
list1 = [1, 2, 3, 4, 5, 6, 7] # 列表
list2 = {1, 2, 3, 4, 5, 6, 7} # 集合 因集合元素是无序的,所以不能用索引进行切片操作。
list3 = (1, 2, 3, 4, 5, 6, 7) # 元组
list4 = {"A": 1, "B": 2,"C": 3, "D": 4, "E": 5, "F": 6, "G": 7} # 字典
print(type(list1))
print(type(list2))
print(type(list3))
print(type(list4))
print(list1[1: 4: 2])
print(list1[1: 4])
# print(list2[1: 4: 2]) # 集合不能切片
# print(list2[1: 4])
print(list3[1: 4: 2])
print(list3[1: 4])
# print(list4[1: 4: 2]) # 字典不能切片
# print(list4[1: 4])
a = "hello"
print(a[1: 3: 2])
print(a[1: 3]) # 顾头不顾尾
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q7FQmNJ4-1657347673600)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220709140354674.png)]](https://i-blog.csdnimg.cn/blog_migrate/19feed4d49826c3be4ab2ec2aa1cb1e1.png)
创建列表及列表常用函数
| 分类 | 关键字/函数/方法 | 说明 |
|---|---|---|
| 增加 | 列表.insert(index, data) | 在指定位置idnex插入数据 |
| 增加 | 列表.appentd(data) | 在末尾追加数据 |
| 增加 | 列表1.extend(列表2) | 将列表2的数据追加到列表1 |
| 修改 | 列表[index] = data | 修改指定索引的数据 |
| 删除 | del 列表[index] | 删除指定索引的数据 |
| 删除 | 列表.remove[data] | 删除第一个出现的指定数据 |
| 删除 | 列表.pop | 删除末尾数据 |
| 删除 | 列表.pop(index) | 删除指定索引数据 |
| 统计 | len(列表) | 列表长度 |
| 统计 | 列表.count(data) | 数据在列表中出现的次数 |
| 排序 | 列表.sort() | 升序排序 |
| 排序 | 列表.sort(revers=True) | 降序排序 |
| 排序 | 列表.reverse() | 逆序、反转 |
# 创建方式
# 方式一:list(iterable)
a = list("HelloWord")
print(a)
# 方式二:[]
b = [] # 创建一个空列表
print(type(b))
c = [1, 2, 3, 4, 5, 6, 7]
print(c)
# 列表相关函数
print("列表相关函数:")
# 追加单个元素。append()
A = [4, 5, 6]
print(A)
A.append(7)
print(A)
# 追加多个元素。两个列表相加。 使用+ 或使用 extend()
B = [8, 9, 10]
C = [1, 2, 3]
A += B # 等价于:A = A + B
print(A)
C.extend(A)
print(C)
# 插入元素
# 方法:list.insert(i,x)
# 方法解释: i是索引的位置。在指定索引的前方插入。 x是具体的元素
print("")
print("列表C:" + str(C))
# 在列表C中的3,4之间插入"python"
C.insert(3, "python")
print(C)
# 替换元素
# 方法:list(i) = x
# 方法解释: i为索引,x为具体元素。
# 把集合C中的python替换成3.5
C[3] = 3.5
print(C)
# 删除元素
# 方法:list.remove(x)
# 方法解释: x为列表中的元素
# 把C列表中的3.5元素删除
C.remove(3.5)
print(C)
del c[0]
print(c)
# [2, 3, 4, 5, 6, 7]
c.pop()
print(c)
# [2, 3, 4, 5, 6]
c.pop(0)
print(c)
# [3, 4, 5, 6]
# 排序
c = [1, 3, 2, 4, 7, 6, 5]
c.sort() # 升序
print(c)
# [1, 2, 3, 4, 5, 6, 7]
c.reverse() # 反转、逆序
print(c)
# [7, 6, 5, 4, 3, 2, 1]
c.sort(reverse=True) # 降序
print(c)
# [7, 6, 5, 4, 3, 2, 1]
c.reverse() # 反转、逆序
print(c)
# [1, 2, 3, 4, 5, 6, 7]
# 统计
c = [1, 1, 1, 3, 2, 4, 7, 6, 5]
print(len(c))
# 9
print(c.count(1))
# 3
创建元组及元组拆包
# 创建元组方式
# 方式一:tuple(iterable) 函数
t1 = tuple([1, 2, 3, 4, 5]) # 列表作为参数
print(t1)
print(type(t1))
# 方式二:()
t2 = (6, 7, 8)
print(t2)
print(type(t2))
t3 = () # 创建一个空元组
print(t3)
print(type(t3))
t4 = 9, 10, 11 # 小括号可省略
print(t4)
print(type(t4))
# 元组拆包
s_id, s_name = (102, "张三")
s_id1, s_name1 = 103, "李四"
print(s_id)
print(s_name)
print(s_id1)
print(s_name1)
创建集合及常用函数
>>成员运算
- 可以通过in和not in 检查元素是否在集合中。
| 方法 | 说明 |
|---|---|
| ele in set | 如果元素ele 在 集合set中,则返回True。否则返回False。 |
| ele not in set | 如果元素ele 不在集合set中。则返回True,否则返回False。 |
set1 = {1,2,3,4,5,6,7,8,9,10}
print('3' in set1)
# False # '3' 为字符串。set1集合中没有所以返回False
print(3 in set1)
# True
print('3' not in set1)
# True
print(3 not in set1)
# False
>>>交集
- 使用 & 运算符
- 使用 intersection(set) 方法
set1 = {1, 2, 3, 4, 5, 6, 7}
set2 = {2, 4, 6, 8, 10}
set3 = set1 & set2
print(set3)
# {2, 4, 6}
set4 = set1.intersection(set2)
print(set4)
# {2, 4, 6}
>>>并集
- 使用 | 运算符
- 使用 union(set) 方法
set1 = {1, 2, 3, 4, 5, 6, 7}
set2 = {2, 4, 6, 8, 10}
set3 = set1 | set2
print(set3)
# {1, 2, 3, 4, 5, 6, 7, 8, 10}
set4 = set1.union(set2)
print(set4)
# {1, 2, 3, 4, 5, 6, 7, 8, 10}
>>>差集
- 使用 - 运算符
- 使用 difference(set)
set1 = {1, 2, 3, 4, 5, 6, 7}
set2 = {2, 4, 6, 8, 10}
set3 = set1 - set2
print(set3)
# {1, 3, 5, 7}
set4 = set1.difference(set2)
print(set4)
# {1, 3, 5, 7}
print(set2 - set1)
# {8, 10}
>>>对称差 : 相当于两个集合的并集减去交集
- 使用 ^ 运算符
- 使用 symmetric_difference(set)
- 相当于两个集合的并集减去交集
set1 = {1, 2, 3, 4, 5, 6, 7}
set2 = {2, 4, 6, 8, 10}
set3 = set1 ^ set2
print(set3)
# {1, 3, 5, 7, 8, 10}
set4 = set1.symmetric_difference(set2)
print(set4)
# {1, 3, 5, 7, 8, 10}
print(set1 | set2) # 并集
# {1, 2, 3, 4, 5, 6, 7, 8, 10}
print(set1 & set2) # 差集
# {2, 4, 6}
print((set1 | set2) - (set1 & set2)) # 对称差
{1, 3, 5, 7, 8, 10}
>> 比较运算
- 两个集合可以用 == 和 != 进行相等性判断,如果两个集合的元素完全相同,那么 == 比较的结果就是True,否则False。
- 如果集合A的任意一个元素都是集合B的的元素,那么集合A称为集合B的子集,反过来可以称B是A的超集。如果A是B的子集且不等于B,那么A就是B的真子集。
- python为集合类型提供了子集和超集的运算符,就是我们非常属性的 < 和 > 运算符。
set1 = {1, 3, 5}
set2 = {1, 2, 3, 4, 5}
# <运算符表示真子集,<=运算符表示子集
print(set1 < set2, set1 <= set2) # True True
# 用过issubset方法也能进行子集判断
print(set1.issubset(set2)) # True
print(set2.issubset(set1)) # False
# 可以用issuperset 或 > 运算符进行超集判断。
print(set2.issuperset(set1)) # True
print(set2 > set1) # True
集合的方法
- python中的集合是可变类型,可以通过集合类型的方法为集合添加或删除元素
| 分类 | 方法 | 说明 |
|---|---|---|
| 添加 | set.add(elem) | 往集合set添加元素elem |
| 添加 | set.update(set1) | 往集合set添加集合set1中的元素。set1的元素存在就覆盖,不存在就添加set集合中。 |
| 删除 | set.discard(elem) | 删除指定元素elem。集合set不存在元素elem,不会报错。 |
| 删除 | set.remove(elem) | 删除指定元素elem。集合set不存在元素elem,会报错。 |
| 删除 | set.pop() | 从集合set中随机删除一个元素并返回该元素。 |
| 清空 | set.clear() | 清空整个集合 |
| 判断 | set1.isdisjoint(set2) | 判断两个集合有没有相同的元素,没有相同的元素,返回True,否则返回False。 |
# 创建集合
# 集合是无序的。不能使用切片操作。
# 方式一:set(iterable) 函数。
set1 = set("hello") # 字符串
print(set1)
print(type(set1))
# 方式二: {}
set2 = {3, 2, 6, 4, 5}
print(set2)
print(type(set2))
# 创建空集合
set3 = set()
print(set3)
print(type(set3))
set4 = {} # 不能直接用{}创建空集合,{}为空字典
print(set4)
print(type(set4))
# 常用函数
# add(elem) :添加元素,如果元素已经存在,则不能添加,不会抛出错误。
set5 = {4, 6, 8, 9, 1, 3, 5, 7, 2}
print(set5)
set5.add(10)
print(set5)
set5.add(10)
print(set5)
# update
set2 = {3, 2, 6, 4, 5}
set2.update({2, 3, 9, 1, 10})
print(set2)
# {1, 2, 3, 4, 5, 6, 9, 10}
# remove(elem) :删除元素,如果不存在,则抛出异常。
set5.remove(10)
print(set5)
# set5.remove(10)
print(set5) # KeyError: 10
# discard
set8 = {1, 2, 3, 4, 5, 6, 9, 10}
set8.discard(99)
print(set8)
# {1, 2, 3, 4, 5, 6, 9, 10}
# pop
print(set8.pop())
# 1
print(set8)
# {2, 3, 4, 5, 6, 9, 10}
# clear() : 清楚集合
set5.clear()
print(set5)
# 判断两个集合没有没相同的元素
set1 = {'杳杳明明', 'python', '小白'}
set2 = {'PYTHON', 'xiaobai', '杳杳明明'}
set3 = {1, 2, 3}
print(set1.isdisjoint(set2))
# False
print(set1.isdisjoint(set3))
# True
>>不可变集合
python中还有一个不可变类型的集合。名字叫 frozenset 。set 和 frozenset 的区别就如同 list 跟 tuple 的区别。frozenset 由于是不可变类型,能够计算出哈希码,因此它可以作为set中的元素。除了不能添加和删除元素,**frozenset****在其他方面跟 set 基本是一样的。
set1 = frozenset({1,2,4,5})
set2 = frozenset(range(1,6))
print(set1 | set2)
# frozenset({1, 2, 3, 4, 5})
print(set1 & set2)
# frozenset({1, 2, 4, 5})
print(set1 - set2)
# frozenset()
print(set1 < set2)
# True
创建字典及常用函数
| 分类 | 关键字/函数/方法 | 说明 |
|---|---|---|
| 取值 | 字典[key] | 从字典中取值,key不存在会报错 |
| 取值 | 字典.get(key) | 从字典中取值,key不存在不会报错 |
| 新增编辑 | 字典[key]=value | 如果key不存在,新建键值对。 如果key存在,修改value数据。 |
| 新增 | 字典.setdefault(key,value) | 如果key不存在,新建键值对。 如果key存在,不会修改value数据。 |
| 新增编辑 | 字典1.update(字典2) | 将字典2的键值对合并到中。 如果字典2己包含字典1对应的 key-value ,那么字典1中key对应的value 会被覆盖。 如果字典2中不包含字典1对应的 key-value ,则该 key-value 被添加到字典1中。 |
| 删除 | del 字典[key] | 删除指定键值对,key不存在会报错。 |
| 删除 | 字典.pop(key) | 获取指定 key 对应的 value,并删除这个 key-value 对,key不存在会报错。 |
| 删除 | 字典.popitem() | 随机删除一个键值对。 |
| 删除 | 字典.clear() | 清空字典 |
| key列表 | 字典.key() | 获取所有key列表 |
| value列表 | 字典.value() | 获取所有value列表 |
| 元组列表 | 字典.items() | 获取所有(key, value)元组列表 |
| 统计 | len(字典) | 获取字典的键值对数量 |
| 复制 | 字典.copy() 字典.deepcopy() | [python 字典的浅拷贝和深拷贝]((56条消息) python中dict的fromkeys用法_Python 学习者的博客-CSDN博客) |
| 创建新字典 | dict.fromkeys() | [python 字典的fromkeys]((56条消息) python中dict的fromkeys用法_Python 学习者的博客-CSDN博客) |
# 创建字典 dict
# 字典以键值对的形式存在。key : value 其中一个字典中key唯一不能重复,value可以重复。
# 方式一:dict()
# 方式二:{key1:value, key2: value2, ..., key_n: value_n}
# 参数是另一个字典{102 : "张三", 103 : "李四", 104: "王二麻子"}
dict1 = dict({102: "张三", 103: "李四", 104: "王二麻子"})
print(dict1)
print(type(dict1))
# 参数是元组((666, "66大顺"), (888, "88大发"), (999, "长长99")) :元组中套元组
dict2 = dict(((666, "66大顺"), (888, "88大发"), (999, "长长99")))
print(dict2)
print(type(dict2))
# 参数是列表[(102, "王五"), (103, "小李"), (104, "小明")] :列表中套元组
dict3 = dict([(102, "王五"), (103, "小李"), (104, "小明")])
print(dict3)
print(type(dict3))
# 用zip() 函数打包。 zip([666, 777, 888], ["六六大顺", "齐全齐美", "八仙过海"])
dict4 = dict(zip([666, 777, 888], ["六六大顺", "齐全齐美", "八仙过海"]))
print(dict4)
print(type(dict4))
# 创建空字典
dict5 = {}
dict6 = dict()
print(dict5)
print(dict6)
print(type(dict5))
print(type(dict6))
# 修改字典
# 方法:dict[key] = values_new
# 现有字典dict4 = {666: '六六大顺', 777: '齐全齐美', 888: '八仙过海'} 修改key=888的value为"七上八下"
print("现有字典dict4 = {666: '六六大顺', 777: '齐全齐美', 888: '八仙过海'} 修改key=888的value为”七上八下”")
dict4[888] = "七上八下"
print("dict4[888] = '七上八下'修改后的字典" + str(dict4))
# 删除键值对,返回删除的值
# 方法 : dict.pop(key)
print("现有字典dict4 = {666: '六六大顺', 777: '齐全齐美', 888: '七上八下'} 删除key=888,并返回七上八下")
print(dict4.pop(888))
# 常用函数
# 参考链接http://c.biancheng.net/view/2212.html
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 获取字典所有的key-value对,返回一个dict_items对象
ims = cars.items()
print(type(ims)) # <class 'dict_items'>
# 将dict_items转换成列表
print(list(ims)) # [('BMW', 8.5), ('BENS', 8.3), ('AUDI', 7.9)]
# 访问第2个key-value对
print(list(ims)[1]) # ('BENS', 8.3)
# 获取字典所有的key,返回一个dict_keys对象
kys = cars.keys()
print(type(kys)) # <class 'dict_keys'>
# 将dict_keys转换成列表
print(list(kys)) # ['BMW', 'BENS', 'AUDI']
# 访问第2个key
print(list(kys)[1]) # 'BENS'
# 获取字典所有的value,返回一个dict_values对象
vals = cars.values()
# 将dict_values转换成列表
print(type(vals)) # [8.5, 8.3, 7.9]
# 访问第2个value
print(list(vals)[1]) # 8.3
字符串
- 表示方式:普通字符串、原始字符串、长字符穿
常用的转义符
| 字符表示 | Unicode编码 | 说明 |
|---|---|---|
| \t | \u0009 | 水平制表符 |
| \n | \u000a | 换行 |
| \r | \u000b | 回车 |
| \" | \u0022 | 双引号 |
| \’ | \u0027 | 单引号 |
| \\ | \u005c | 反斜杠 |
普通字符串
- 用单引号(') 或 双引号(") 括起来的字符串
# 普通字符串:用单引号(') 或 双引号(") 括起来的字符串
a = 'Hello'
b = "Hello"
print(a + b)
原始字符换
- r :在字符串前面加r。表示原始字符串。
# 原始字符串
a = "Hellow \n word" # \n在普通字符串中表示换行
print(a)
b = r"Hellow \n word" # \n在原始字符中表示 \ 和 n 连个字符
print(b)
长字符串
两种表是方式:
- 3个单引号表示 : ‘’‘XXXXXXXXX’‘’
- 3个双引号表示 : “”“XXXXXXXX”“”
保留原有的格式
# 长字符串 : 保留原有的格式
c = """
春晓
春眠不觉晓,处处闻啼鸟。
夜来风雨声,花落知多少。
—————— 作者:孟浩然
"""
d = '''
登鹳雀楼
王之涣 〔唐代〕
白日依山尽,黄河入海流。
欲穷千里目,更上一层楼。
'''
print(c)
print(d)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D4eV8tAB-1657347673602)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220706193821631.png)]](https://i-blog.csdnimg.cn/blog_migrate/72a17e72c9e4ed7f419ad7e82ad41e5b.png)
将字符串转换为数字
- int() 转换成功则返回数字(整数),否则引发异常
- float() 转换成功则返回数字(浮点数),否则引发异常
s = "90"
print(int(s))
d = "90.0"
# print(int(d)) 异常。int()不能转换浮点数
print(float(d))
print(int("AB", 16)) # 16进制也可以转换,不是16进制不能转换
# print(int("AB", 8)) 异常
# print(int("AB")) 异常
将数字转换为字符串
- str()函数可以将很多类型的数据都转换为字符串
# 将数字转换为字符串
print(str(123)) # 整数转换为字符串
print(str(666.666)) # 浮点数转换为字符串
print(str(True)) # 布尔型转换为字符串
print(str([1, 2, 3])) # 列表转换为字符串
print(str((1, 2, 3))) # 元组转换为字符串
print(str({2, 4, 1})) # 集合转换为字符串
print(str({1: "A", 2: "B"})) # 字典转换为字符串
格式化字符串
-
format() 不仅可以实现字符串的拼接,还可以格式化字符串。
-
center(num,sub)方法,以宽度num将字符串剧中并在两侧填充sub
str = '小白python' print(str.center(20,'*')) # ******小白python****** -
rjust(num,sub)方法。以宽度num将字符串右对齐并在左侧填充sub。sub不写默认填充空格
str = '小白python' print(str.rjust(20,'*')) # ************小白python print(str.rjust(20)) # 小白python -
ljust(num,sub)方法。以宽度num将字符串左对齐并在左侧填充sub。sub不写默认填充空格
str = '小白python' print(str.ljust(20,'*')) # 小白python************ print(str.ljust(20)) # 小白python -
zfill(num)方法。在字符串的左侧补零。
str = '6' print(str.zfill(5)) # 00006 print(str.zfill(2)) # 06
>> 占位符举例
| 变量值 | 占位符 | 格式化结果 | 说明 |
|---|---|---|---|
| 3.1415926 | {:.2f} | ‘3.14’ | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | ‘+3.14’ | 带符号保留小数点后两位 |
| -1 | {:+.2f} | ‘-1.00’ | 带符号保留小数点后两位 |
| 3.1415926 | {:.0f} | ‘3’ | 不带小数 |
| 123 | {:0>10d} | ‘0000000123’ | 左边补0,补够10位 |
| 123 | {:x<10d} | ‘123xxxxxxx’ | 右边补x,补够10位 |
| 123 | {:>10d} | ’ 123’ | 左边补空格,补够10位 |
| 123 | {:<10d} | '123 ’ | 右边补空格,补够10位 |
| 123456789 | {:,} | ‘123,456,789’ | 逗号分隔格式 |
| 0.123 | {:.2%} | ‘12.30%’ | 百分比格式 |
| 123456789 | {:.2e} | ‘1.23e+08’ | 科学计数格式 |
a = 3.1415926
print('保留小数点后两位:{:.2f}'.format(a))
# 保留小数点后两位:3.14
print('带符号保留小数点后两位:{:+.2f}'.format(a))
# 带符号保留小数点后两位:+3.14
a = -1
print('带字符保留两位小数:{:+.2f}'.format(a))
# 带字符保留两位小数:-1.00
a = 3.1415926
print('不带小数:{:.0f}'.format(a))
# 不带小数:3
b = 123
print('左边补0,补够10位。 {:0>10d}'.format(b))
# 左边补0,补够10位。 0000000123
print('右边补0,补够10位。 {:x<10d}'.format(b))
# 右边补x,补够10位。 123xxxxxxx
print('左边补空格,补够10位。 {:>10d}'.format(b))
# 左边补空格,补够10位。 123
print('右边补空格,补够10位。 {:<10d}'.format(b))
# 右边补空格,补够10位。 123
# 可以按照格式进行更改自己想要的形式。如右边补充+,补充11位
print('右边补充+,补够11位:{:+<11d}'.format(b))
# 右边补充+,补够11位:123++++++++
c = 123456789
print('逗号分隔格式:{:,}'.format(c))
# 逗号分隔格式:123,456,789
d = 0.123
print('百分比格式:{:.2%}'.format(d))
# 百分比格式:12.30%
d = 0.123454789
print('百分比格式:{:.3%}'.format(d)) # 四舍五入
# 百分比格式:12.345%
print('百分比格式:{:.5%}'.format(d)) # 四舍五入
# 百分比格式:12.34548%
e = 123456789
print('科学技术法格式:{:.2e}'.format(e))
# 科学技术法格式:1.23e+08
使用占位符
- 想要将表达式的计算结果插入字符串中,则需要用到占位符 {}。
格式化控制符
-
{l:d}
l :参数序号
d : 格式控制符
参数序号与 : 之间不能有空格
| 格式控制符 | 说明 |
|---|---|
| s | 字符串 |
| d | 十进制整数 |
| f、F | 十进制浮点数 |
| g、G | 十进制整数或浮点数 |
| e、E | 科学计算法表示浮点数 |
| o | 八进制整数。符号是小写英文字符o |
| x、X | 十六进制整数,x是小写表示,X是大写表示 |
-
%s 占位符 可以接受所有的数据类型
-
%d 占位符 只能接受数字类型 有局限性
-
在字符串前加上 f 来格式化字符串。在这种以 f 大头的字符串中。{变量名}是一个占位符。 (python3.6开始)
a = 11 b = 6 print(f'{a} * {b} = {a*b}') # 11 * 6 = 66
格式化占位符控制符示例:
money = 123456.654321
name = "明哥"
print("{0:s}年龄{1:d},工资是{2:f}元/月".format(name, 26, money))
print("{0}年龄{1},工资是{2:0.2f}元/月".format(name, 26, money)) # 格式化输出保留两位小数3.14
print("{0},工资是{1:G}元/月".format(name, money))
print("{0},工资是{1:g}元/月".format(name, money))
print("{0},工资是{1:e}元/月".format(name, money))
print("{0},工资是{1:E}元/月".format(name, money))
print("十进制数{0:d}的八进制表示为{0:o}".format(18))
print("十进制数{0:d}的十六进制表示为{0:x}".format(18))
print("十进制数{0:d}的十六进制表示为{0:X}".format(18))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-acXga16S-1657347673603)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220706203227199.png)]](https://i-blog.csdnimg.cn/blog_migrate/e4d747878124a9177fa006d6ff97eeab.png)
操作字符串
>>判断类型
| 方法 | 说明 |
|---|---|
| string.isspance() | 如果string中只包含空格,则返回True |
| string.isalnum() | 如果string至少有一个字符并且所有字符都是字母或数字,则返回True |
| string.isalpha() | 如果string至少有一个字符并且所有字符都是字母,则返回True |
| string.isdecimal() | 如果string只包含数字,则返回True,全角数字 |
| string.isdigit() | 如果string只包含数字,则返回True,全角数字、(1)、\u00b2 |
| string.isnumeric() | 如果string只包含数字,则返回True。全角数字、汉字数字 |
| string.istitle() | 如果string是标题化的(每个单词的首字母大写),则返回True |
| string.islower() | 如果string中至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回True |
| string.issupper() | 如果string中至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回True |
| string.startswith(sub) | 检查字符串是否以指定的字符串(sub)开头。是,则返回True。否,则返回False |
| string.endswith(sub) | 检查字符串是否以指定的字符串(sub)结尾。是,则返回True。否,则返回False |
>>查找
| 方法 | 说明 |
|---|---|
| string.find(sub, start, end) | 在索引start到end之间查找子字符sub,如果找到,则返回最左端位置的索引;如果没有找到,则返回-1。 |
| string.rfind(sub) | 从后向前找字符串sub出现的位置。(相当于最后一次出现) |
| string.index(sub) | 查找子字符sub,如果找到,则返回最左端位置的索引;如果没有找到,则报错。 |
| string.count(sub) | 统计一个字符串(sub)在大字符串中出现的次数 |
>>修剪操作(去除空格)
| 方法 | 说明 |
|---|---|
| string.strip() | 获得去除左右两侧空格之后的字符串。 |
| string.lstrip() | 获得去除左侧空格之后的字符串。 |
| string.rstrip() | 获得去除右侧空格之后的字符串。 |
str = ' www.baidu.com \t\r\n'
print(str.strip())
# www.baidu.com
print(str.lstrip())
# www.baidu.com
#
print(str.rstrip())
# www.baidu.com
>>大小写相关操作
| 方法 | 说明 |
|---|---|
| string.capitalize() | 获取字符串首字母大写后的字符串。 |
| string.title() | 获取字符串每个单词首字母大写后的字符串。 |
| string.upper() | 获取字符串大写后的字符串。 |
| string.lower() | 获取字符串小写后的字符串。 |
str = 'hello world,嗨,123,小白python。'
print(str.capitalize())
# Hello world,嗨,123,python。小白 h-->H
print(str.title())
# Hello World,嗨,123,小白Python。 h-->H w-->W p-->P
print(str.upper())
# HELLO WORLD,嗨,123,小白PYTHON。
str_1 = 'HELLO WORLD,嗨,123,小白PYTHON。'
print(str_1)
# HELLO WORLD,嗨,123,小白PYTHON。
print(str_1.lower())
# hello world,嗨,123,小白python。
字符串查找及常用函数
-
str.find(sub, start, end)
在索引start到end之间查找子字符sub,如果找到,则返回最左端位置的索引;如果没有找到,则返回-1。
s_str = "Hello World lxm"
print(s_str.find("l")) # 找到第一个索引
print(s_str.find("l", 4, 6)) # 从索引4找到索引6,没有符合要求。返回-1
print(s_str.find("l", 4)) # 从索引4 一直往后找,找到第一个字符l的所在索引
print(s_str.find("l", 8, 12)) # 从索引8 一直往后找,找到第一个字符l的所在索引
print()
s_str1 = "lxm"
print(s_str1 in s_str) # 字符串是否在另一个字符串中

-
count :统计一个字符串在大字符串中出现的次数
str_name = "A B C D E F G H D E C D A" print(str_name.count("D")) # out: 3 -
isdigit :判断一个字符串里的数据是不是都是数字。
str_pwd = "625" print(str_pwd.isdigit()) # out: True str_user = "625Admin" print(str_user.isdigit()) # out: False -
isalpha : 判断一个字符串里的数据是不是都是字母。中文也算字母。
str_1 = "abcEFG" print("# out: %s" % str_1.isalpha()) # out: True str_1 = " abcEFG" # 加了一个空格 print("# out: %s" % str_1.isalpha()) # out: False str_1 = "/abcEFG" # 加了一个/ print("# out: %s" % str_1.isalpha()) # out: False str_1 = "小明abcEFG" # 加了小明 print("# out: %s" % str_1.isalpha()) # out: True -
startswith : 比较开头的元素是否相同
-
endswith :比较结尾的元素是否相同
msg = "nanjing is jiangsu" print("# out: %s" % msg.startswith("nanjing")) # out: True print("# out: %s" % msg.startswith("n1")) # out: False print("# out: %s " % msg.endswith("su")) # out: True print("# out: %s " % msg.endswith("u")) # out: True -
islower : 判断字符串的值是否全是小写。
-
isupper : 判断字符串的值是否全是大写
msg = "abc" print(msg.islower()) # out: False msg_str = "ABCD" print("# out: %s" % msg_str.isupper()) # out: True
字符串替换
- str.replace(old, new, count)
new字符串替换old字符串。count参数指定了替换old子字符串的个数,count被省略,则替换所有old子字符串。
-
re.sub()
不仅可以对一种字符串进行替代,还可以替代多种字符串。
注意:需要导入import re
text = "AB CD EF GH IJ"
text = text.replace(" ", "|", 2) # 把前两个空格( )替换为|
print(text)
text_1 = "AB CD EF GH IJ"
text_1 = text_1.replace(" ", "|") # 把所有的空格( )替换为|
print(text_1)
import re # 导入re才能使用re.sub
s = '2022/07/07 09:40:30'
print(re.sub(r"/", "-", s)) # 把/替换成-
print(re.sub(r"[/:]", "-",s)) # 把/:替换成-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rAxtHuz2-1657347673605)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220707100622613.png)]](https://i-blog.csdnimg.cn/blog_migrate/0be68b0932712d7ca09e3769d64d24fc.png)
>>字符串分割 (split) 、列表元素连接成字符串(json)
-
str.split(sep, maxsplit)
使用sep子字符串分割字符串str。maxsplit是最大分割次数,如果maxsplit被省略,则表示不限制分割次数。
sep为默认值时,认为空格、\n、\t等都是分隔符。
s = "AB CD EF GH IJ"
print(s.split(" "))
s_1 = "AB CD EF\nGH\tIJ"
print(s_1.split()) # 为默认值时,认为空格、\n、\t等都是分隔符;
print(s.split(" ", 2)) # 根据空格( )分割两次
print(s.split(" ", 1)) # 根据空格( )分割一次
print(s.split(" ")[0]) # 根据空格( )分割,取第一个值。0为索引。
print(s.split(" ", 2)[2]) # 根据空格( )分割两次,取第三值。2为索引

-
json() 方法将列表中的多个字符串连接成一个字符串。
str = 'www baidu com' s = str.split() print(s) # ['www', 'baidu', 'com'] print('.'.join(s)) # www.baidu.com
>>编码/解码
- 解码函数decode() 和编码函数encode()
a = '杳杳明明'
b = a.encode('utf-8')
c = a.encode('gbk')
print(b)
# b'\xe6\x9d\xb3\xe6\x9d\xb3\xe6\x98\x8e\xe6\x98\x8e'
print(c)
# b'\xe8\xc3\xe8\xc3\xc3\xf7\xc3\xf7'
print(b.decode('utf-8'))
# 杳杳明明
print(c.decode('gbk'))
# 杳杳明明
去除字符串两边的空格 strip()
- 只去除字符串两边的空格,中间的不会去除。
str_name = " 小 明 "
str_name = str_name.strip()
print(str_name)
# out: 小 明
函数
定义函数
def 函数名(形式参数列表):
函数体
return 返回值
- 如果没有数据返回则可以省略return语句
>> 给函数加注释
def countNum(num1, num2):
'''
这个一个简单的计算函数
:param num1:参数一
:param num2:参数二
:return:没有返回值
'''
res = num1 + num2
print(f'{num1} + {num2} = {res}')
# 调用
countNum(1,2)
# 1 + 2 = 3
形参与实参
由于定义函数时的参数不是实际数据,会在调用函数时传递给他们实际数据,所以我们称定义函数时的参数为形式参数,简称形参。
称调用函数时传递的实际数据为实际参数,简称实参。
调用函数
使用位置参数调用函数
- 在调用函数时传递的实参与定义函数时的形参顺序一致,这是调用函数的基本形式。
使用关键字参数调用函数
- 在调用函数时可以采用"关键字=实参"的形式,其中,关键字的名称就是定义函数时形参的名称。
- 实参不再受形参的顺序限制
# 定义rect_area函数,width、height 两个形参列表
def rect_area(width, height):
area = width * height
return area
# 使用位置参数调用函数
# 调用函数rect_area
r_area = rect_area(320.33, 480.23)
print("{0} x {1} 长方形的面积:{2}".format(320, 480, r_area))
print("{0} x {1} 长方形的面积:{2:0.2f}".format(320, 480, r_area)) # 结果保留两个小数
r_area = rect_area(0.2225, 2)
print("{0} x {1} 长方形的面积:{2:0.2f}".format(0.2225, 2, r_area)) # 结果保留两个小数
# 使用关键字参数调用函数
print()
r_area = rect_area(width=320.33, height=480.23)
print("{0} x {1} 长方形的面积:{2}".format(320, 480, r_area))
print("{0} x {1} 长方形的面积:{2:0.2f}".format(320, 480, r_area)) # 结果保留两个小数
r_area = rect_area(height=2, width=0.2225) # 实参不再受形参的顺序限制
print("{0} x {1} 长方形的面积:{2:0.2f}".format(0.2225, 2, r_area)) # 结果保留两个小数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W0Y4vv92-1657347673606)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220707110936914.png)]](https://i-blog.csdnimg.cn/blog_migrate/3ffc605c4b60697744acabc342edc9fa.png)
参数
>>参数的作用
- 函数,把具有独立功能的代码块组成一个小模块,在需要的时候调用。
- 函数的参数,增加函数的通用性,针对相同的数据处理逻辑,能够适应更多的数据。
- 在函数 内部 ,把参数当作变量使用。进行需要的数据处理。
- 函数调用时,按照函数定义的参数顺序,把 希望在函数内部处理的数据,通过参数传递
参数的默认值
# 参数默认值为苹果
def like_fruit(name="苹果"): # 苹果就是默认值
return "我喜欢吃{0}".format(name)
like_1 = like_fruit() # 直接调用不给实参,就会使用默认值
like_2 = like_fruit(name="香蕉")
like_3 = like_fruit(name="火龙果")
print(like_1)
print(like_2)
print(like_3)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L7WRnJRV-1657347673607)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220707112039319.png)]](https://i-blog.csdnimg.cn/blog_migrate/f25326fe174755f5693b2a4585b27018.png)
可变参数
- Python中的函数可以定义接收不确定数量的参数,这种参数被称为可变参数。
- 可变参数有两种。即在参数前加 * 或 **
基于元组的可变参数(*可变参数)
- *可变参数在函数中被组装成一个元组。
def sum_tol(*numbers):
total = 0.0
for number in numbers:
total += number
return total
print(sum_tol(100, 20, 30.0))
print(sum_tol(10.01, 30.0))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OEieU2qa-1657347673608)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220707113250790.png)]](https://i-blog.csdnimg.cn/blog_migrate/2f60e82eeb3190a8b46057b48b968053.png)
基于字典的可变参数(**可变参数)
- **可变参数在函数中被组装成一个字典
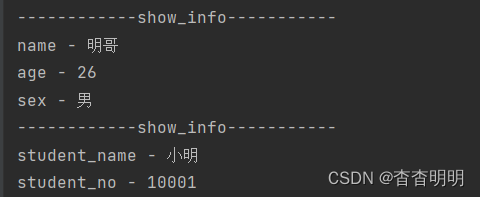
def show_info(**info):
print("------------show_info-----------")
for key, value in info.items():
print("{0} - {1}".format(key, value))
show_info(name="明哥", age=26, sex="男")
show_info(student_name="小明", student_no="10001")
函数的嵌套使用
- 一个函数里面 又调用了另一个函数,这就是 函数嵌套调用
- 如果函数 test2 中,调用了另外一个函数 test1
- 那么执行到调用 test1 函数时,会先把函数 test1 中的任务(代码)都执行完
- 才会回到 test2 中调用函数 test1 的位置,继续执行后续的代码。
def test1():
print('*' * 30)
print('执行函数test1内部代码')
print('*' * 30)
def test2():
print('-' * 30)
test1() # 调用函数test1
print('执行后函数test1后,在执行后续的代码。')
print('-' * 30)
# 调用test2函数
test2()
输出:
# ------------------------------
# ******************************
# 执行函数test1内部代码
# ******************************
# 执行后函数test1后,在执行后续的代码。
# ------------------------------
函数中的变量作用域
全局变量 和 局部变量
-
局部变量: 由某对象或函数内部定义的变量,就是局部变量, 局部变量又可称之为内部变量。
只能被内部引用,而无法被其它对象或函数引用。
-
全局变量:在函数外部定义的变量,或者在函数的内部,用global关键字定义的变量,就是全局变量。
全局变量是可以被本程序所有对象或函数引用。
-
作用域: 作用的范围 局部变量的作用范围只限定在函数的内部; 全局变量的作用范围横跨整个文件;
-
变量的生命周期:内置 > 全局 > 局部
global 用法
- global是Python中的全局变量关键字。
- global关键字的作用是可以使得一个局部变量为全局变量。
# 创建全局变量x
x = "明哥"
def print_value():
x = "无名" # 局部变量
print("(局部变量)函数中的x = {0}".format(x))
print_value()
# 输出:(局部变量)函数中的x = 无名
print("全局变量x = {0}".format(x))
# 输出:全局变量x = 明哥
def print_value_tow():
global x # 将x变量提升为全局变量
x = "明哥丨分晏" # 局部变量
print("(局部变量)函数中的x = {0},\n 并把x变量提升为全局变量".format(x))
print_value_tow()
# 输出:(局部变量)函数中的x = 明哥丨分晏,
# 并把x变量提升为全局变量
print("x = {0}".format(x))
# 输出:x = 明哥丨分晏
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8sbYPBdP-1657347673609)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220707121602701.png)]](https://i-blog.csdnimg.cn/blog_migrate/438feddf841b586b0f532c8dc2afffff.png)
函数类型
- Python中的任意一个函数都有数据类型,这种数据类型是function,被称为函数类型。
- 一个函数可以作为另一个函数返回值使用
- 一个函数可以作为另一个函数参数使用
# 定义减法函数
def sub(a, b):
return a - b
# 定义加法函数
def add(a, b):
return a + b
# 定义平方函数
def square(a):
return a * a
# 定义计算函数
def calc(opr):
if opr == "+":
return add
else:
return sub
f1 = calc("+") # f1实际上是add函数
f2 = calc("-") # f2实际上是sub函数
f3 = calc("") # f2实际上是square函数
print(type(f1))
print(type(f2))
print(type(f3))
print("666 + 111 = {0}".format(f1(666, 111)))
print("666 - 111 = {0}".format(f2(666, 111)))
print("5 * 5 = {0}".format(f3(5)))
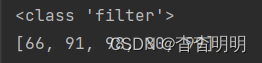
过滤函数filter
- filter(function, iterable)
# 提供过滤条件函数
def fun_1(x):
return x > 50 # 找出大于50的元素
data1 = [66, 15, 91, 28, 98, 50, 7, 80, 99]
filtered = filter(fun_1, data1)
print(type(filtered))
data2 = list(filtered) # 将filtered转换为列表
print(data2)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TVBL4Cqk-1657347673610)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220707182822445-16571897035981.png)]](https://i-blog.csdnimg.cn/blog_migrate/cc4e177f5f97480b22a3712cfa825b4e.png)
映射函数map
- map(function, interable)
# 提供变换规则的函数
def func_2(x):
return x * 2 # 变换规则乘以2
data3 = [11, 22, 33, 44, 25]
mapped = map(func_2, data3)
print(type(mapped))
data4 = list(mapped) # 转换为列表
print(data3)
print(data4)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QVjxOmox-1657347673611)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220707184114941.png)]](https://i-blog.csdnimg.cn/blog_migrate/842c8de8a744f1b81fd5dd90665dcac8.png)
lambda函数
-
使用lambda关键字定义匿名函数。
-
lambda关键字定义的函数也被称为lambda函数。
-
方法:lambda 参数列表:lambda体
lambda体 可以为其他函数
# 定义减法函数
def sub1(a, b):
return a - b
# 定义加法函数
def add1(a, b):
return a + b
# 定义计算函数
def calc(opr):
if opr == "+":
return add1
else:
return sub1
def calc1(opr1):
if opr1 == "+":
return lambda a, b: (a + b) # 替代add1函数
else:
return lambda a, b: (a - b) # 替代sub1函数
print("--------------add1函数、sub1函数结果----------------")
f1 = calc("+") # f1实际上是add1函数
f2 = calc("-") # f2实际上是sub2函数
print("666 + 111 = {0}".format(f1(666, 111)))
print("666 - 111 = {0}".format(f2(666, 111)))
print("--------------lambda函数结果-----------------------")
f6 = calc1("+") # lambda函数
f7 = calc1("-") # lambda函数
print("666 + 111 = {0}".format(f6(666, 111)))
print("666 - 111 = {0}".format(f7(666, 111)))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-il3tIcxk-1657347673611)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\image-20220707185545038.png)]](https://i-blog.csdnimg.cn/blog_migrate/49d5eb0e1954469e5eccb2f45b9740c8.png)
模块
- 模块是python程序架构的一个核心概念
- 模块 就好比是 工具包 ,要想使用这个工具包的工具,就需要 导入import 这个模块
- 每一个以扩展名 py 结尾的 python 源代码文件都是一个 模块
- 在 模块 中定义的全局变量、函数 都是模块能够提供外界直接调用的工具。
>>模块的两种导入方式
-
import 导入
import 模块名1,模块名2import 模块1 import 模块2- 导入之后,通过 模块名. 使用 模块提供的工具----全局变量、函数、类
- 使用 as 指定模块的别名。如果模块的名字太长, 可以使用 as 指定模块的名称,以方便在代码中的使用。
import 模块名1 as 模块别名 -
from - import 导入
from 模块名 import 工具名- 如果希望 从某一个模块 中,导入 部分 工具。就可以用 from…import 的方式
- 导入后,不需要通过 模块名. 访问。 可以直接使用 模块提供的工具----全局变量、函数、类
注意
如果 两个模块,存在 同名的函数,那么 后导入模块的函数, 会 覆盖掉先导入的函数。
- 包 是一个 包含多个模块 的 特殊目录
- 目录下有一个 特殊的文件 ****
- 报名的命名方式和变量名一致。小写字母+_
好处
- 使用 import 包名 可以一次性导入 包 中 所有的模块
示例:
如图有一个 test_包名。里面有两个模块 send_message.py 、receive_message.py 以及特殊文件 ____init____.py
send_message.py 代码:
def send(message):
print(f'正在发送{message}')
receive_message.py 代码:
def receive():
return '接收消息成功。。。'
____init____.py 代码:
# 从当前路径下导入receive_message 、send_message
from . import receive_message
from . import send_message
调用模块
模块使用包.py 代码
import test_
test_.send_message.send('杳杳明明')
return_str = test_.receive_message.receive()
print(return_str)
# 正在发送杳杳明明
# 接收消息成功。。。
创建对象
定义类
语法:
class 类名(父类):
#类体
pass
class Car(object): # object 可以不写。不写默认继承object
#类体
pass # 没有类体时,需要使用关键字pass。不写pass会出现异常。
class Car(): # 等价于上面
#类体
pass
创建对象
- 实例化对象,创建对象。
# 定义类Car
class Car():
#类体
pass
# 创建对象
car = Car() # Python中区分大小写。car是对象,Car是类。
类的成员
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HgvPLYKe-1657347673612)(D:\PycharmProjects\pythonTypora\Python常识概念.assets\类的成员.png)]](https://i-blog.csdnimg.cn/blog_migrate/b074cd4ced319b590c0dc4efcc2d3967.png)
实例变量
- 实例变量就是对象个体特有的“数据”。如狗狗的名称和年龄等。
- 对实例变量访问通过“对象.实例变量”形式访问。
class Dog:
def __init__(self, name, age):
self.name = name # 创建和初始化实例变量name
self.age = age # 创建和初始化实例变量age
d = Dog("土豆", 4) # d为对象
print("我们家狗狗叫{0},{1}岁了。".format(d.name, d.age)) # 通过“对象.实例变量”形式访问实列变量。
# out:我们家狗狗叫土豆,2岁了。
构造方法:
- __init__方法是构造方法,构造方法用来创建和初始化实例变量。注意:init的前后是两个下划线。
class Dog:
# 构造方法和实例方法第一个参数都是self。 self表示当前对象,当前实列。
def __init__(self, name, age, sex="雌性"): # sex="雌性" 为省略值
self.name = name # 创建和初始化实例变量name
self.age = age # 创建和初始化实例变量age
self.sex = sex # 创建和初始化实例变量sex
d1 = Dog("土豆", 2)
d2 = Dog("球球", 3, "雄性")
d3 = Dog(name="豆豆", sex="雄性", age=4)
print("狗狗叫{0},{1}岁了 {2}。".format(d1.name, d1.age, d1.sex))
# out:狗狗叫土豆,2岁了 雌性。
print("狗狗叫{0},{1}岁了 {2}。".format(d2.name, d2.age, d2.sex))
# out:狗狗叫球球,3岁了 雄性。
print("狗狗叫{0},{1}岁了 {2}。".format(d3.name, d3.age, d3.sex))
# out:狗狗叫豆豆,4岁了 雄性。
实例方法
- 实例方法与实例变量一样,都是某个实例(或对象)个体特有的方法。
class Dog:
# 构造方法
def __init__(self, name, age, sex="雌性"):
self.name = name # 创建和初始化实例变量name
self.age = age # 创建和初始化实例变量age
self.sex = sex # 创建和初始化实例变量sex
# 实例方法
def run(self):
print("{}在跑……".format(self.name))
# 实例方法
def speak(self, sound):
print("{}在叫,'{}'!".format(self.name, sound))
dog = Dog("球球", 2)
dog.run()
# out:球球在跑……
dog.speak("旺 旺 旺 旺")
# out:球球在叫,'旺 旺 旺 旺'!
类变量
- 类变量是属于类的变量,不属于单个对象。
class Account:
interest_rate = 0.0568 # 类变量 利率interest_rate
def __init__(self, owner, amount):
self.owner = owner # 创建并初始化实例变量
self.amount = amount # 创建并初始化实例变量
account = Account("明哥", 88888888.88)
print("账户名:{}".format(account.owner)) # 通过“对象.实例变量”访问
# out:账户名:明哥
print("账户金额:{} 元".format(account.amount)) # 通过"对象.实例变量"访问
# out:账户金额:88888888.88 元
print("利率:{}".format(Account.interest_rate)) # 通过“类名.类变量”访问
# out:利率:0.0568
类方法
- 类方法与类变量类似,属于类,不属于个体实例。
- 关键字:@classmethod
语法如下:
@classmethod
def 类方法名(cls):
pass
class Account:
interest_rate = 0.0568 # 类变量 利率interest_rate
def __init__(self, owner, amount):
self.owner = owner # 定义实例变量账户名
self.amount = amount # 定义实例变量账户金额
# 类方法
@classmethod # 类方法关键字。不加关键字。就成为实例方法了。
def interest_by(cls, amt):
return cls.interest_rate * amt
interest = Account.interest_by(66666.66)
print("计算利息:{:.4f}".format(interest)) # {:.4f} 等价于 {0:0.4f} 保留四位小数。 格式化控制符
# out:计算利息:3786.6663
私有变量
- 为了防止外部调用者随意存取类的内部数据(成员变量),内部数据(成员变量)会被封装为"私有变量"
- 私有变量定义方法:在变量前加上双下划线(__)
class Account:
__interest_rate = 0.0568 # 私有变量 类变量 利率__interest_rate
def __init__(self, owner, amount):
self.owner = owner # 创建并初始化实例变量owner
self.__amount = amount # 创建并初始化私有实例变量__amount
def desc(self):
return "{} 金额:{} 元,利率:{}。".format(self.owner, self.__amount, Account.__interest_rate)
account = Account("明哥", 88888.88)
str_1 = account.desc()
print(str_1)
# out:明哥 金额:88888.88 元,利率:0.0568。
print("账户名:{}".format(account.owner))
# out:账户名:明哥
print("账户金额:{}".format(account.__amount)) # 发生错误 因为私有变量不能被外部访问
# out:AttributeError: 'Account' object has no attribute '__amount'
print("利率:{}".format(Account.__interest_rate)) # 发生错误 因为私有变量不能被外部访问
# out:AttributeError: type object 'Account' has no attribute '__interest_rate'
私有方法
- 私有方法与私有变量的封装是类似。防止外部调用者随意存取类的内部方法
- 定义方法:在方法前加上双下画线(__)
class Account:
__interest_rate = 0.0568 # 私有变量 类变量 利率__interest_rate
# 构造方法
def __init__(self, owner, amount):
self.owner = owner # 创建并初始化实例变量owner 外部调用者可调用
self.__amount = amount # 创建并初始化私有实例变量__amount 外部调用者不可调用
# 私有方法 外部调用者不可调用
def __get_info(self):
return "{} 金额:{}元,利率:{}。".format(self.owner, self.__amount, Account.__interest_rate)
# 实例方法 外部调用者可调用
def desc(self):
print(self.__get_info())
account = Account("明哥", 66666.66)
account.desc() # 调用类的实例方法desc Account类的desc实例方法中可以调用私有变量。 因为desc实例方法在Account类中,属于内部调用。
# out:明哥 金额:66666.66元,利率:0.0568。
account.__get_info() # 外部调用者直接掉用私有方法就会发生错误
# out:AttributeError: 'Account' object has no attribute '__get_info'
使用属性
- 为了实现对象的封装,在一个类中不应该有公有的成员变量,这些成员变量应该被设计为私有的,然后通过公有的set(赋值)和get(取值)方法进行访问
- 关键字:@property
class Dog:
# 构造方法
def __init__(self, name, age, sex="雌性"): # sex="雌性" 省略值:默认值。不给sex赋值,默认为雌性。
self.name = name # 创建并初始化实例变量name 外部调用者可以调用
self.__age = age # 创建和初始化私有实例变量__age 外部调用者不可以调用
@property # 外部调用者获取age值
def age(self):
return self.__age
@age.setter # 外部调用者给age重新赋值
def age(self, age):
self.__age = age
dog = Dog("球球", 3)
print("{}的年龄:{}岁了。".format(dog.name, dog.age))
# out:球球的年龄:3岁了。
dog.age = 2 # 给age重新赋值
print("修改后{}的年龄:{}岁。".format(dog.name, dog.age))
# out:修改后球球的年龄:2岁。
继承性
- 继承也是面向对象重要的基本特性之一。
- 它源于人们认识客观世界的过程,是自然界普遍存在的一种现象。
- 在面向对象编程中,被继承的类称为父类或基类,新的类称为子类或派生类。
继承
-
语法:
class 子类名(父类): # 类体 pass -
例子:
class Animal: # 定义Animal类 作为父类 def __init__(self, name): # 构造方法 self.name = name # 创建并初始化实例变量name def show_info(self): # 实例方法 return "动物的名字是:{}".format(self.name) def move_dong(self): # 实例方法 print("{}动一动……".format(self.name)) # Cat类继承Animal类 父类:Animal 子类:Cat class Cat(Animal): # 子类Cat构造方法。 def __init__(self, name, age): # super() 指代父类 # 调用父类构造方法,初始化父类的成员变量 super().__init__(name) self.age = age # 创建并初始化实例变量age cat = Cat("TOM", 2) # 子类Cat 继承了父类Animal。 可以通过创建子类对象使用父类中的成员变量 cat.move_dong() # out: TOM动一动…… print(cat.show_info()) # out: 动物的名字是:TOM>>父类方法拓展 super()
-
在python中super是一个特殊的类
-
super() 就是使用super类创建出来的对象。
-
最常 使用的场景就是在 重写父类方法时,调用 在父类中封装的方法实现。
多继承
-
语法:
class 子类名(父类1, 父类2, ... , 父类n): # 类体 pass
示例:
# 定义Horse类
class Horse:
# 构造方法
def __init__(self, name):
self.name = name # 创建并初始化实力变量
# 实例方法
def show_info(self):
return "Horse 马的名字:{}".format(self.name)
# 实例方法
def run(self):
return "Horse {}在跑......".format(self.name)
# 定义 Donkey类
class Donkey:
# 构造方法
def __init__(self, name):
self.name = name # 创建并初始化name
# 实例方法
def show_info(self):
return "Donkey 驴的名字:{}".format(self.name)
# 实例方法
def run(self):
return "Donkey {}在跑......".format(self.name)
# 实例方法
def roll(self):
return "Donkey {}打滚.....".format(self.name)
# 子类Mule继承父类House,继承父类Donkey
class Mule(Horse, Donkey):
# 子级中的构造方法
def __int__(self, name, age):
# 初始化父类中的成员变量。
super().__init__(name)
self.age = age # 创建并初始化实力变量。子类中
m = Mule("骡宝利") # 创建m对象
print(m.run()) # 继承父类Horse
# out:Horse 骡宝利在跑......
print(m.roll()) # 继承父类Donkey
# out: Donkey 骡宝利打滚.....
print(m.show_info()) # 继承父类Horse
# out: Horse 马的名字:骡宝利
重写
class Horse:
def __init__(self, name):
self.name = name # 创建并初始化实例变量
def show_info(self):
return "Horse 马的名字:{}".format(self.name)
def run(self):
return "Horse 马({})在跑......".format(self.name)
class Donkey:
def __init__(self, name):
self.name = name # 创建并初始化实例变量name
def show_info(self):
return "Donkey 驴的名字:{}".format(self.name)
def run(self):
return "Donkey 驴({})在跑......".format(self.name)
def roll(self):
return "Donkey 驴打滚...{}".format(self.name)
class Mule(Horse, Donkey):
def __init__(self, name, age):
super().__init__(name) # 初始化父类成员变量
self.age = age # 创建并初始化成员变量
# show_info方法重写
def show_info(self):
return "Mule 方法重写: 骡:{},{}岁。".format(self.name, self.age)
m = Mule("骡宝莉", 2)
print(m.run())
# out:Horse 马(骡宝莉)在跑......
print(m.roll())
# out:Donkey 驴打滚...骡宝莉
print(m.show_info())
# out:Mule 方法重写: 骡:骡宝莉,2岁。
新式类 和旧式(经典)类
object 是 Python 为所有对象提供的 基类(父类),提供有一些内置的属性和方法,可以使用 dir 函数查看。
- 新式类:以 object 为基类的类。推荐使用。
- 经典类:不以 object 为基类的类。不推荐使用
- 在 Python3.x 中定义类时,如果没有指定父类,会 默认使用 object 作为该类的 基类
- 在 Python3.x 中定义的类都是 新式类
- 在 Python2.x 中定义类时,如果没有指定父类,则不会以 object 作为该类的 基类。
- 新式类 和 经典类 在多继承时,会影响到方法的搜索顺序
- 为了保证编写的代码可以同时 在 Python2.x 和 Python3.x 运行。定义类时,如果没有父类,建议统一继承自 object。
多态性
- ”多态“值对象可以表现出多种形态。
- 例如:猫、狗、鸭子都属于东武,他们有”叫“和”动“等行为,但是”叫“的方式不同。”动“的方式也不同。
- 一龙生九子,九子各不同。
继承与多态
- 在多个子类继承父类,并重写父类得方法后,这些子类所创建的对象之间就是多态的。这些对象采用不同的方式实现父类方法。
class Animal:
def speak(self):
print("动物叫,但不知道是那种动物叫.....")
class Dog(Animal):
def speak(self):
print("小狗,旺旺旺叫......")
class Cat(Animal):
def speak(self):
print("小猫:喵喵喵叫......")
an1 = Dog()
an2 = Cat()
an1.speak()
# out:小狗,旺旺旺叫......
an2.speak()
# out:小猫:喵喵喵叫......
异常捕获
捕获异常
- 语法:
try:
<可能会引发异常的语句>
except[异常类型]: # 异常类型可以省略
<处理异常>
i = input("请输入字数:")
n = 8888
try:
result = n / int(i)
print(result)
print("{}除以{}等于{}".format(n, i, result))
except ZeroDivisionError as e:
print("不能除以0,异常:{}".format(e))
# out: 不能除以0,异常:division by zero
多个except代码块
- 语法:
try:
<可能会引发异常的语句>
except[异常类型1]:
<处理异常>
except[异常类型2]:
<处理异常>
...
except:
<处理异常>
示例:
i = input("请输入字数:")
n = 8888
try:
result = n / int(i)
print(result)
print("{}除以{}等于{}".format(n, i, result))
except ZeroDivisionError as e:
print("不能除以0,异常:{}".format(e))
# out: 不能除以0,异常:division by zero
except ValueError as e:
print("输入的【{}】是无效数字,异常:{}".format(i, e))
# out:输入的【ddd】是无效数字,异常:invalid literal for int() with base 10: 'ddd'
多重异常捕获
- 如果多个except代码块的异常处理过程类似,则可以合并处理,这就是多重异常捕获
n = 8888
try:
result = n / int(i)
print(result)
print("{}除以{}等于{}".format(n, i, result))
except (ZeroDivisionError, ValueError) as e:
print("异常发生,异常:{}".format(e))
# out: 异常发生,异常:division by zero
# out: 异常发生,异常:invalid literal for int() with base 10: 'ddd'
try-except语句嵌套
i = input("请输入字数:")
n = 8888
try:
i2 = int(i)
try:
result = n / i2
print(result)
print("{}除以{}等于{}".format(n, i, result))
except ZeroDivisionError as e:
print("不能除以0,异常:{}".format(e))
# out:不能除以0,异常:division by zero
except (ZeroDivisionError, ValueError) as e:
print("输入的【{}】是无效数字,异常:{}".format(i, e))
# out: 输入的【ddd】是无效数字,异常:invalid literal for int() with base 10: 'ddd'
使用finally代码块释放资源
- 语法:
try:
<可能会引发异常的语句>
except[异常类型1]:
<处理异常>
except[异常类型2]:
<处理异常>
...
except:
<处理异常>
finally:
<释放资源>
示例:
i = input("请输入字数:")
n = 8888
try:
i2 = int(i)
try:
result = n / i2
print(result)
print("{}除以{}等于{}".format(n, i, result))
except ZeroDivisionError as e:
print("不能除以0,异常:{}".format(e))
# out:不能除以0,异常:division by zero
except (ZeroDivisionError, ValueError) as e:
print("输入的【{}】是无效数字,异常:{}".format(i, e))
# out: 输入的【ddd】是无效数字,异常:invalid literal for int() with base 10: 'ddd'
finally:
print("释放资源")
# out: 释放资源
# 发生异常,不发生异常。都会打印释放资源
print("{}除以{}等于{}".format(n, i, result))
except (ZeroDivisionError, ValueError) as e:
print("异常发生,异常:{}".format(e))
# out: 异常发生,异常:division by zero
# out: 异常发生,异常:invalid literal for int() with base 10: 'ddd'
try-except语句嵌套
i = input("请输入字数:")
n = 8888
try:
i2 = int(i)
try:
result = n / i2
print(result)
print("{}除以{}等于{}".format(n, i, result))
except ZeroDivisionError as e:
print("不能除以0,异常:{}".format(e))
# out:不能除以0,异常:division by zero
except (ZeroDivisionError, ValueError) as e:
print("输入的【{}】是无效数字,异常:{}".format(i, e))
# out: 输入的【ddd】是无效数字,异常:invalid literal for int() with base 10: 'ddd'
使用finally代码块释放资源
- 语法:
try:
<可能会引发异常的语句>
except[异常类型1]:
<处理异常>
except[异常类型2]:
<处理异常>
...
except:
<处理异常>
finally:
<释放资源>
示例:
i = input("请输入字数:")
n = 8888
try:
i2 = int(i)
try:
result = n / i2
print(result)
print("{}除以{}等于{}".format(n, i, result))
except ZeroDivisionError as e:
print("不能除以0,异常:{}".format(e))
# out:不能除以0,异常:division by zero
except (ZeroDivisionError, ValueError) as e:
print("输入的【{}】是无效数字,异常:{}".format(i, e))
# out: 输入的【ddd】是无效数字,异常:invalid literal for int() with base 10: 'ddd'
finally:
print("释放资源")
# out: 释放资源
# 发生异常,不发生异常。都会打印释放资源
>>一个完成的异常语法
- else try下方代码运行时,不出现异常报错。执行成功后,则执行else之下的代码
- finally 无论try下方代码执行是否成功,都执行下方代码
try:
num = int(input('请输入一个整数:'))
result = 8 / num
print(result)
except:
print('出现异常......')
else:
# 如果当前代码执行成功后,则执行else之下的代码
print('运算成功')
finally:
print('无论执行是否成功,都执行这段语句。')
>>抛出raise异常
应用场景
- 在开发中,除了 代码执行出错,Python 解析器会 抛出 异常之外。
- 还可以根据 应用程序 特有的业务需求 主动抛出异常
- Python 中提供了一个Exception 异常类
- 在开发时,如果满足 特定业务需求时, 希望抛出异常,可以
- 创建一个 Exception 对象
- 使用 raise 关键字 抛出 异常对象
需求示例:
- 定义 input_password 函数,提示用户输入密码
- 如果用户输入长度<8, 抛出异常。
- 如果用户输入长度>=8,返回输入的密码。
def input_password():
# 1. 提示用户输入密码
pwd = input('请输入密码:')
# 2. 判断用户输入的密码是否满足长度要求
if len(pwd) >= 8:
return pwd
# 3. 如果用户输入的密码不满足长度要求,则创建异常对象并抛出异常
print('主动抛出异常')
# 自定义错误类型
ex = Exception('密码长度不够...')
# 4. 主动抛出异常
raise ex
# 在主函数中捕获异常
if __name__ == '__main__':
try:
print(input_password())
except Exception as e:
print(e)
# 请输入密码:234
# 主动抛出异常
# 密码长度不够...
时间
在Python中通常有这几种方式表达时间:
-
时间戳(timestamp),表示的是从1970年1月1日00:00:00开始计算按秒计算的偏移量。例子:1554864776.161902
-
元祖(
struct_time)共九个元素。由于Python的time模快实现主要调用C库。所以各个平台可能有所不同索引(Index) 属性(Attribute) 值(Value) 0 tm_year(年) 如2022 1 tm_mon(月) 1-12 2 tm_mday(日) 1-31 3 tm_hour(时) 0-23 4 tm_min(分) 0-59 5 tm_sec(秒) 0-61 6 tm_wday(weekday) 0-6(0表示周一) 7 tm_yday(一年中的第几天) 1-366 8 tm_isdst(是否是夏令时) 默认-1
时间日期格式化符号:
| 格式 | 说明 |
|---|---|
| %y | 两位数的年份表示(00-99) |
| %Y | 四位数的你年份表示(0000-9999) |
| %m | 月份(01-12) |
| %d | 月内中的一天(0-31) |
| %H | 24小时制小时数(0-23) |
| %I | 12小时制小时数(01-12) |
| %M | 分钟数(00-59) |
| %s | 秒(00-59) |
| %a | 本地简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化的月份名称 |
| %B | 本地完整的月份名称 |
| %c | 本地相应的日期表示和时间表示 |
| %j | 年内的一天(001-366) |
| %p | 本地A.M.或P.M.的等价符 |
| %U | 一年中的星期数(00-53)星期天为星期的开始 |
| %w | 星期(0-6),星期天为星期开始。 |
| %W | 一年中的星期数(00-53),星期一为星期的开始。 |
| %x | 本地相应的日期表示 |
| %X | 本地相应的时间表示 |
| %Z | 当前时区的名称 |
time模块的常用方法
import time
time.time(): 返回当前时间的时间戳。time.localtime([secs]): 将一个时间戳转换为当前时区的struct_time。若sec参数未提供,则以当前时间为准。time.gmtime([secs]): 和localtime()方法类似,gmtime()方法是将一个时间戳转为UTC时区(0时区)的struct_time。time.mktime(t): 将一个struct_time转为时间戳。time.sleep(secs): 现成推迟指定的时间运行,单位为秒。time.strftime(format[, t]): 将一个代表时间的元祖或者struct_time(如由time.localtime()和time.gmtime())转化为格尔石化的时间字符串。如果 t 未指定,将传入time.localtime()。- 举例:
time.strftime('%Y-%m-%d %X', time.localtime())输出:2022-08-18 21:25:28
- 举例:
time.strptime(string[, format]):把一个格式化的时间字符串转化为struct_time。实际上它和strftime()是逆操作。- 举例:
time.strptime('2022-08-18 21:25:28','%Y-%m-%d %X')输出:time.struct_time(tm_year=2022, tm_mon=8, tm_mday=18, tm_hour=21, tm_min=25, tm_sec=28, tm_wday=3, tm_yday=230, tm_isdst=-1)
- 举例:
datetime模块
import datetime
相比于time模块,datetime模块的接口则更直观、更容易调用。
模块定义了下面这几个类:
datetime.date: 表示日期的类。 常用的属性year、month、day;datetime.time: 表示时间的类。 常用的属性有hour、minute、second、microsecond;datetime.datetime: 表示时间日期。datetime.timedelta:表示时间间隔,即连个时间点之间的长度datetime.tzinfo: 与时区有关的相关信息。
datetime常用的方法:
-
dt = datetime.datetime.now(): 返回当前的datetime日期类型。dt.timestamp(): 返回时间戳dt.today(): 返回今天日期dt.year:返回年dt.timetuple():返回struct_time元组。
import datetime dt = datetime.datetime.now() print(dt) # 2022-08-18 20:59:02.802579 print(dt.timestamp()) # 1660827542.802579 print(dt.today()) # 2022-08-18 20:59:02.802580 print(dt.year) # 2022 print(dt.timetuple()) # time.struct_time(tm_year=2022, tm_mon=8, tm_mday=18, tm_hour=20, tm_min=59, tm_sec=2, tm_wday=3, tm_yday=230, tm_isdst=-1) -
datetime.date.fromtimestamp(1660827542.802579): 把一个时间戳转为datetime日期类型。print(datetime.date.fromtimestamp(1660827542.802579)) # 2022-08-18 -
时间运算
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)**注意:**参数中没有年的选项,可以使用 weeks=56 来表示一年。
day = datetime.datetime.now() ddelay = datetime.timedelta(days=1) wdelay = datetime.timedelta(weeks = 5) ydelay = datetime.timedelta(weeks = 56) print(day) # 2022-08-18 21:21:29.890482 print(day - ddelay) # 一天前的时间 # 2022-08-17 21:21:29.890482 print(day + ddelay) # 一天后的时间 # 2022-08-19 21:21:29.890482 print(day - wdelay) # 5 周前 # 2022-07-14 21:21:29.890482 print(day + wdelay) # 5 周后 # 2022-09-22 21:21:29.890482 print(day - ydelay) # 一年前 # 2021-07-22 21:21:29.890482 print(day + ydelay) # 一年后 # 2023-09-14 21:21:29.890482 -
时间替换
day.replace(day=1): 把天替换1day.replace(year=None, month=None, day=None, hour=None, minute=None, second=None, microsecond=None, tzinfo=True, fold=None)day = datetime.datetime.now() # 当月1号 print(datetime.date(datetime.date.today().year, datetime.date.today().month, 1)) # 2022-08-01 # 当月1号 print(datetime.date.today().replace(day=1)) # 2022-08-01 # 上月1号 print((datetime.date.today().replace(day=1) - datetime.timedelta(1)).replace(day=1)) # 2022-07-01一、日志Logging
日志界别
日志级别分为5个级别
使用场景
| 级别 | 日志函数 | 描述 |
|---|---|---|
| DEBUG | logging.debug() | 最低级别,用于小细节。 通常用于来记录详细的信息,方便定位问题进行调试。在生产环境我们一般不开启DEBUG。 |
| INFO | logging.info() | 用于记录关键代码点的信息,以便代码是否按照我们预期的执行**,生产环境中通常会设置INFO级别。** |
| WARNING | logging.warning() | 记录某些不能预期发生的情况,如磁盘不足。 |
| ERROR | logging.error() | 用于记录错误。用于一个更严重的问题导致某些功能不能正常运行时记录的信息。 |
| CRITICAL | logging.critical() | 最高级别。当发生严重错误,导致应用程序不饿能继续运行时记录的信息。 |
日志级别等级排序
CRITICAL> ERROR> WARNING> INFO> DEBUG
级别越高打印的日志越少,反之亦然,即
DEBUG: 打印全部的日志
INFO: 打印 info, warning, error, critical 级别的日志
WARNING: 打印 warning, error, critical 级别的日志,默认情况下日志的级别是WARGING
ERROR: 打印 error, critical 级别的日志
CRITICAL: 打印 critical 级别
备注:注意代码中日志级别需要使用大写
日志格式化输出参数含义
| 参数 | 含义 |
|---|---|
| %(asctime)s | 字符串形式的当前时间。默认格式是 “2022-08-17 00:18:45,896”。逗号后面的是毫秒 |
| %(levelname)s | 文本形式的日志级别 |
| %(message)s | 用户输出的消息 |
| %(filename)s | 调用日志输出函数的模块的文件名 |
| %(name)s | Logger的名字%(levelno)s数字形式的日志级别 |
| %(levelno)s | 数字形式的日志级别 |
| %(pathname)s | 调用日志输出函数的模块的完整路径名,可能没有 |
| %(module)s | 调用日志输出函数的模块名 |
| %(funcName)s | 调用日志输出函数的函数名 |
| %(lineno)d | 调用日志输出函数的语句所在的代码行 |
| %(created)f | 当前时间,用UNIX标准的表示时间的浮 点数表示 |
| %(relativeCreated)d | 输出日志信息时的,自Logger创建以来的毫秒数 |
| %(thread)d | 线程ID。可能没有 |
| %(threadName)s | 线程名。可能没有 |
| %(process)d | 进程ID。可能没有 |
封装l日志类
import logging
class Log:
"""
日志类
:param level: 不传递level参数时,默认日志级别为DEBUG
:param power_handler: False 控制台处理器开启、文件处理器关闭。 True 文件处理器开启,控制台处理器关闭
:param filepath: 文件处理器的日志的路径包含名称。 默认'./fileLog.txt'
"""
# level: 不传递level参数时,默认日志级别为DEBUG
# powerHandle: False 控制台处理器开启、文件处理器关闭。 True 文件处理器开启,控制台处理器关闭
# filePath: 文件处理器的日志的路径包含名称。 默认'./LOG/fileLog.txt'
def __init__(self, level='DEBUG', power_handler=True, filepath='./LOG/fileLog.txt'):
# 创建日志器
self.log = logging.getLogger(name='杳杳明明') # name 设置 %(name)s 打印的名字。
self.powerHandle = power_handler
self.filePath = filepath
self.level = level
self.log.setLevel(level) # 设置日志级别
def console_handle(self):
"""
控制台处理器
:param level: 日志级别,不传递参数时为'DEBUG'
:return: 返回控制台处理器 console_handler
"""
console_handler = logging.StreamHandler()
console_handler.setLevel(self.level)
# 控制台处理器添加格式器
console_handler.setFormatter(self.get_formatter()[0])
return console_handler
def file_handle(self):
"""
文件处理器
:param level: 日志级别,不传递参数时为'DEBUG'
:return: 返回文件处理器 file_handler
"""
file_handler = logging.FileHandler(self.filePath, mode='a', encoding='utf-8')
file_handler.setLevel(self.level)
# 文件处理器添加格式器
file_handler.setFormatter(self.get_formatter()[1])
return file_handler
def get_formatter(self):
"""
控制台的输出格式样式
:return: [0] : 控制台控制器格式 、[1] : 文件控制器格式
"""
# 控制台控制器输出格式
console_fmt = logging.Formatter(fmt='%(name)s >> %(levelname)s >> %(asctime)s : %(message)s ')
# 文件控制器输出格式
file_fmt = logging.Formatter(fmt='%(name)s >> %(levelname)s >> %(asctime)s : %(message)s ')
return console_fmt, file_fmt
def get_log(self):
if self.powerHandle:
# 日志器添加文件处理器
self.log.addHandler(self.file_handle())
else:
# 日志器添加控制台处理器
self.log.addHandler(self.console_handle())
# 返回日志实例对象
return self.log
调用方式
from 日志.logClass import Log
class Test():
def __init__(self):
logg = Log('INFO', False) # ******************************
self.logger = logg.get_log() # ******************************
def test1(self):
self.logger.critical('*' * 30)
self.logger.debug('这是debug信息')
self.logger.info('这是info信息')
self.logger.warning('这是warning信息')
self.logger.error('这是error信息')
self.logger.critical('这是critical信息')
self.logger.critical('*' * 30)
test = Test()
test.test1()
二 office文件操作
关于 import os
-
os.getcwd(): 获取当前工作目录print(os.getcwd()) # D:\PycharmProjects\xiaobaiPyhton\office操作 -
os.chdir(): 改变当前工作目录 -
os.listdir(path): 的所有文件和目录名、print(os.listdir()) # ['1.py', '2.py', 'Excel', 'os模块.py'] -
os.removedirs(path):用于删除多个目录。 删除为空(没有文件或子目录)的目录。 -
os.remove(path): 用于删除一个文件os.remove('1.py') print(os.listdir()) # ['2.py', 'Excel', 'os模块.py'] -
os.path.isfile(path): 检验给出的路径是否是一个文件。是返回True,否返回False。print(os.path.isfile('../office操作/a')) # False print(os.path.isfile('os模块.py')) # True -
os.path.isdir(path): 检验给出的路径是否是一个目录。是返回True,否返回False。print(os.path.isdir('../office操作/a')) # True print(os.path.isdir('os模块.py')) # False -
os.path.exists(path): 检验给出的路径(文件、目录)是否真实存在。是返回True,否返回False。print(os.path.exists('../office操作/a')) # True print(os.path.exists('os模块.py')) # True print(os.path.exists('../office操作/yymm')) # False print(os.path.exists('yymm.py')) # False -
os.path.dirname(): 获取路径名。父级目录print(os.path.dirname(r'D:\PycharmProjects\xiaobaiPyhton\office操作\a')) # D:\PycharmProjects\xiaobaiPyhton\office操作 print(os.path.exists('os模块.py')) # ../office操作 -
os.path.abspath(): 获取绝对路径print(os.path.abspath(r'..\office操作\a')) # D:\PycharmProjects\xiaobaiPyhton\office操作\a print(os.path.abspath('os模块.py')) # D:\PycharmProjects\xiaobaiPyhton\office操作\os模块.py -
os.path.basename(): 获取文件名。 目录名成、文件名称(加后缀)print(os.path.basename(r'..\office操作\a')) # a print(os.path.basename(r'D:\PycharmProjects\xiaobaiPyhton\office操作\os模块.py')) # os模块.py -
os.system():运行shell命令 -
os.rename(old, new): 重命名。print(os.listdir()) # ['2.py', 'a', 'Excel', 'os模块.py'] os.rename('2.py','newname.py') print(os.listdir()) # ['a', 'Excel', 'newname.py', 'os模块.py'] -
os.makedirs():创建多级目录。os.makedirs(r'./yymm/yy/mm') print(os.listdir()) # ['a', 'Excel', 'newname.py', 'os模块.py', 'yymm'] print(os.listdir('./yymm')) # ['yy'] print(os.listdir('./yymm/yy')) # ['mm'] -
os.mkdir(): 创建单个目录print(os.listdir()) # ['a', 'Excel', 'newname.py', 'os模块.py', 'yymm'] os.mkdir('yymm2') print(os.listdir()) # ['a', 'Excel', 'newname.py', 'os模块.py', 'yymm', 'yymm2'] -
(file): 获取文件属性- st_size :文件大小,字节。
- st_atime :文件最后访问时间
- st_mtime :文件最后修改时间
- st_ctime :文件创建时间
print(os.stat('os模块.py').st_mode) # 权限模式 # 33206 print(os.stat('os模块.py').st_ino) # inode number # 10414574138321044 print(os.stat('os模块.py').st_dev) # device # 2056052283 print(os.stat('os模块.py').st_nlink) # number of hard links # 1 print(os.stat('os模块.py').st_uid) # 所有用户的user id # 0 print(os.stat('os模块.py').st_gid) # 所有用户的group id # 0 print(os.stat('os模块.py').st_size) # 文件的大小,字节为单位 # 2742 print(os.stat('os模块.py').st_atime) # 文件最后访问时间 # 1660750601.4009764 print(os.stat('os模块.py').st_mtime) # 文件最后修改时间 # 1660750601.3243368 print(os.stat('os模块.py').st_ctime) # 文件创建时间 # 1660745727.6715767 -
os.path.getsize(filename)、os.path.getatime()、os.path.getmtime()、os.path.getctime()、: 获取文件大小、最后访问时间、最后修改时间、文件创建时间print(os.path.getsize('os模块.py')) # 文件的大小,字节为单位 # 3204 print(os.path.getatime('os模块.py')) # 文件最后访问时间 # 1660750988.7907565 print(os.path.getmtime('os模块.py')) # 文件最后修改时间 # 1660750988.6825705 print(os.path.getctime('os模块.py')) # 文件创建时间 # 1660745727.6715767 -
os.getpid: 获取子进程id -
os.getppid: 获取父进程id
2.1Excel文件操作
先导入Workbook、load_workbook模块
1、创建一个Excel文件
-
实例化一个工作簿workbook
from openpyxl import Workbook from openpyxl import load_workbook wb = Workbook() # 实例化一个工作簿workbook -
获取当前活动(active)的sheet
# 获取当前活动(active)的sheet sheet = wb.active -
获取/设置 当前活动(active)的sheet的名称
# 获取当前活动(active)的sheet的名称 print(sheet.title) # 设置当前活动(active)的sheet的名称 sheet.title = '杳杳明明'
写数据
-
方式一: 数据可以直接分配到单元格中(可以输入公式)
sheet['B9'] = '张三' sheet['C9'] = '男' sheet['D9'] = '南京' -
方式二:可以附加行,从第一列开始附加(从最下方空白出,最左开始)(可以输入多行)
sheet.append([1, 2, 3]) -
方式三:
cell(rowNum, cloNum): rowNum表示行数,cloNum表示列数(A=1,B=2, C=3 …)# 方式三:cell(rowNum, cloNum) sheet.cell(9, 1).value = '9表示行数,1表示列数(A=1,B=2, C=3 ...)' -
方式四:Python 类型会被自动转换
sheet['A3'] = datetime.datetime.now().strftime('%Y-%m-%d')
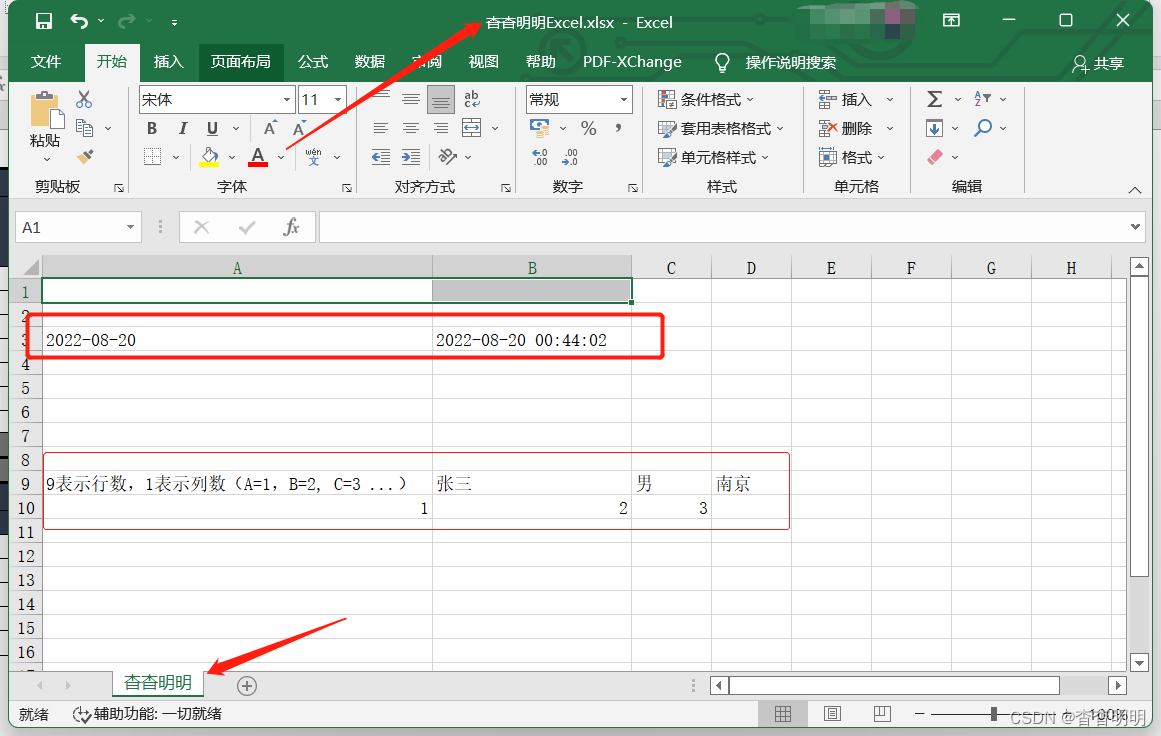
sheet['B3'] = datetime.datetime.now().strftime('%Y-%m-%d %X')
-
保存Excel文件。
save(filename):filename: excel的文件名(路径)。 如果不想覆盖之前的excel文件,可以改个excel文件的名称。相当于另存为。wb.save('杳杳明明Excel.xlsx') -
保存后打开数据示意图:
2、 打开已有Excel文件
举列表格数据:
-
打开已存在的Excel文件(周报_杳杳明明20220808.xlsx)
参数 说明 filename excel文件名(路径) read_only 是否只读。 False:可以读也可以写;True:只能读;默认False keep_vba=KEEP_VBA 保留vba内容(这并不意味着你可以使用它) data_only 是否读取公式计算后的结果。True:读取计算后的结果;False:不读取计算后的结果。默认False keep_links 是否应该保留外部工作簿的链接。默认为True # 打开已存在的Excel wb = load_workbook(r'D:\某某公司\周报模板\周报_杳杳明明20220808.xlsx') -
获取工作表sheet的名称。推荐使用
sheetnames# 方式一:sheetnames print(wb.sheetnames) # ['Sheet1', 'Sheet2', 'Sheet3', 'Sheet4'] # 方式二:get_sheet_names() 已过时 print(wb.get_sheet_names()) # 已过时 # ['Sheet1', 'Sheet2', 'Sheet3', 'Sheet4'] -
读取哪个工作表sheet的内容设置。
# 读取哪一个工作表sheet # 方式一:workbook[shhetname] 推荐使用 sheet = wb['Sheet1'] # 方式二:get_sheet_by_name(sheetname) 已过时 sheet = wb.get_sheet_by_name('Sheet1') # 方式三: sheet = wb[wb.sheetnames[0]] #获取指定序列对应名称的工作表 # 方式四:workbook.worksheets[index] 获取指定索引序号的一张工作表。 sheet = wb.worksheets[0] #获取指定索引序号的一张工作表。
获取Excel文件中的数据
-
获取B4单元格数据
# 获取B4单元格 print(sheet['B4']) # <Cell 'Sheet1'.B4> # 获取B4单元格的值 # 方式一: print(sheet['B4'].value) # 2022-08-08 00:00:00 # 方式二: print(sheet.cell(4,2).value) # 2022-08-08 00:00:00-
方式一:
sheet['B4'].value直接使用B4获取 -
方式二:
sheet.cell(4,2).value使用cell函数获取。cell(rowNum, colNume): rowNum表示行数,colNume表示列数(A=1,B=2, C=3 …)
-
-
单列获取数据
# 选中B列4行至B列10行的cell print(sheet['B4:B10']) # ((<Cell 'Sheet1'.B4>,), (<Cell 'Sheet1'.B5>,), (<Cell 'Sheet1'.B6>,), (<Cell 'Sheet1'.B7>,), (<Cell 'Sheet1'.B8>,), (<Cell 'Sheet1'.B9>,), (<Cell 'Sheet1'.B10>,)) # 获取B列4行至B列10行的值。 循环获取值。 for cell in sheet['B4:B10']: print(cell) # (<Cell 'Sheet1'.B4>,) print(cell[0].value) # 因为cell是元组,所以用索引[0]取值。 # 2022-08-08 00:00:00 -
循环获取工作表sheet的每行每列的值.
- 按行遍历
# 循环获取一个工作表sheet的每个单元格的值 for row in sheet: # print(row) # (<Cell 'Sheet1'.A1>, <MergedCell 'Sheet1'.B1>, <MergedCell 'Sheet1'.C1>, <MergedCell 'Sheet1'.D1>, <MergedCell 'Sheet1'.E1>, <MergedCell 'Sheet1'.F1>, <MergedCell 'Sheet1'.G1>) for cell in row: # print(cell) # < Cell'Sheet1'.A1 > # < MergedCell 'Sheet1'.B1 > # < MergedCell 'Sheet1'.C1 > # < MergedCell 'Sheet1'.D1 > # < MergedCell 'Sheet1'.E1 > # < MergedCell 'Sheet1'.F1 > # < MergedCell 'Sheet1'.G1 > print(cell.value, end=',') # 每行单元个以,拼接起来, print() # 一行数据换一行打印 # 输出 # 个人 工 作 周 报 表,None,None,None,None,None,None, # 本周工作完成情况,None,None,None,None,None,None, # 星期,日期,项目名称,工作安排及完成情况,工作量(人/天),责任人,备注, # 星期一,2022-08-08 00:00:00,项目名称1,工作安排及完成情况1,1,杳杳明明1,备注1, # 星期二,2022-08-09 00:00:00,项目名称2,工作安排及完成情况2,2,杳杳明明2,备注2, # 星期三,2022-08-10 00:00:00,项目名称3,工作安排及完成情况3,3,杳杳明明3,备注3, # 星期四,2022-08-11 00:00:00,项目名称4,工作安排及完成情况4,4,杳杳明明4,备注4, # 星期五,2022-08-12 00:00:00,项目名称5,工作安排及完成情况5,5,杳杳明明5,备注5, # 星期六,2022-08-13 00:00:00,None,None,None,None,None, # 星期日,2022-08-14 00:00:00,None,None,None,None,None, # None,None,None,None,None,None,None, # None,None,None,None,None,None,None, # 下周工作计划安排,None,None,None,None,None,None, # 序号,项目名称,None,计划工作内容,工作量(人/天),责任人,备注, # 1,2022-08-15 00:00:00,项目名称6,工作安排及完成情况6,6,杳杳明明6,备注6, # 2,2022-08-16 00:00:00,项目名称7,工作安排及完成情况7,7,杳杳明明7,备注7, # 3,2022-08-17 00:00:00,项目名称8,工作安排及完成情况8,8,杳杳明明8,备注8, # 4,2022-08-18 00:00:00,项目名称9,工作安排及完成情况9,9,杳杳明明9,备注9, # 5,2022-08-19 00:00:00,项目名称10,工作安排及完成情况10,10,杳杳明明10,备注10,-
按列遍历
# A1, A2, A3 ...这样的顺序遍历 for column in sheet.columns: for cell in column: print(cell.value, end=',') print() # 个人 工 作 周 报 表,本周工作完成情况,星期,星期一,星期二,星期三,星期四,星期五,星期六,星期日,None,None,下周工作计划安排,序号,1,2,3,4,5, # None,None,日期,2022-08-08 00:00:00,2022-08-09 00:00:00,2022-08-10 00:00:00,2022-08-11 00:00:00,2022-08-12 00:00:00,2022-08-13 00:00:00,2022-08-14 00:00:00,None,None,None,项目名称,2022-08-15 00:00:00,2022-08-16 00:00:00,2022-08-17 00:00:00,2022-08-18 00:00:00,2022-08-19 00:00:00, # None,None,项目名称,项目名称1,项目名称2,项目名称3,项目名称4,项目名称5,None,None,None,None,None,None,项目名称6,项目名称7,项目名称8,项目名称9,项目名称10, # None,None,工作安排及完成情况,工作安排及完成情况1,工作安排及完成情况2,工作安排及完成情况3,工作安排及完成情况4,工作安排及完成情况5,None,None,None,None,None,计划工作内容,工作安排及完成情况6,工作安排及完成情况7,工作安排及完成情况8,工作安排及完成情况9,工作安排及完成情况10, # None,None,工作量(人/天),1,2,3,4,5,None,None,None,None,None,工作量(人/天),6,7,8,9,10, # None,None,责任人,杳杳明明1,杳杳明明2,杳杳明明3,杳杳明明4,杳杳明明5,None,None,None,None,None,责任人,杳杳明明6,杳杳明明7,杳杳明明8,杳杳明明9,杳杳明明10, # None,None,备注,备注1,备注2,备注3,备注4,备注5,None,None,None,None,None,备注,备注6,备注7,备注8,备注9,备注10,
-
获取一个工作表sheet 指定范围(从第4行到第8行A至F列)的单元格的值
-
按行遍历:
iter_rows(min_row=None, max_row=None, min_col=None, max_col=None, values_only=False)参数 说明 官方翻译得来的说明 min_row 起始行,起始值默认是1 最小行索引(基于1的索引) max_row 结束行,默认是最大的行 最大行索引(基于1的索引) min_col 起始列 ,起始值默认是1 最小列索引(基于1的索引) max_col 结束列,默认是最大的列 最大列索引(基于1的索引) values_only False:返回单元格的对象
True:返回单元格内容是否只返回单元格值 - 实现代码
# 按行获取从第4行到第8行A至F列。 A=1,B=2,C=3,D=4,E=5,F=5 for row in sheet.iter_rows(min_row=4, max_row=8, min_col=1, max_col=6): # 设置了values_only=True for cell in row: print(cell.value, end=', ') # 此处取值无需加value。 cell就是值 print() # 星期一, 2022-08-08 00: 00:00, 项目名称1, 工作安排及完成情况1, 1, 杳杳明明1, # 星期二, 2022-08-09 00: 00:00, 项目名称2, 工作安排及完成情况2, 2, 杳杳明明2, # 星期三, 2022-08-10 00: 00:00, 项目名称3, 工作安排及完成情况3, 3, 杳杳明明3, # 星期四, 2022-08-11 00: 00:00, 项目名称4, 工作安排及完成情况4, 4, 杳杳明明4, # 星期五, 2022-08-12 00: 00:00, 项目名称5, 工作安排及完成情况5, 5, 杳杳明明5, -
按列遍历
iter_cols(min_col=None, max_col=None, min_row=None, max_row=None, values_only=False)-
实现代码
# 按列获取 从第4行到第8行A至F列的单元格数据 for column in sheet.iter_cols(min_col=1,max_col=6,min_row=4,max_row=8): for cell in column: print(cell.value, end=',') print() # 星期一,星期二,星期三,星期四,星期五, # 2022-08-08 00:00:00,2022-08-09 00:00:00,2022-08-10 00:00:00,2022-08-11 00:00:00,2022-08-12 00:00:00, # 项目名称1,项目名称2,项目名称3,项目名称4,项目名称5, # 工作安排及完成情况1,工作安排及完成情况2,工作安排及完成情况3,工作安排及完成情况4,工作安排及完成情况5, # 1,2,3,4,5, # 杳杳明明1,杳杳明明2,杳杳明明3,杳杳明明4,杳杳明明5,
-
-
3、给excel数据设置各种样式
3.1 需要导入的类
from openpyxl.styles inport Font : 字体
from openpyxl.styles inport colors :颜色
from openpyxl.styles inport Alignment :对齐方式
3.2 字体 Font
字体颜色
- 调用方式
- color=colors.Color(index=2)
- color=colors.Color(rgb=‘00FF0000’)
- color=colors.COLOR_INDEX[2]
Color(index=0) # 根据索引进行填充
#
Color(rgb='00000000') # 根据rgb值进行填充
# index
COLOR_INDEX = (
'00000000', '00FFFFFF', '00FF0000', '0000FF00', '000000FF', #0-4
'00FFFF00', '00FF00FF', '0000FFFF', '00000000', '00FFFFFF', #5-9
'00FF0000', '0000FF00', '000000FF', '00FFFF00', '00FF00FF', #10-14
'0000FFFF', '00800000', '00008000', '00000080', '00808000', #15-19
'00800080', '00008080', '00C0C0C0', '00808080', '009999FF', #20-24
'00993366', '00FFFFCC', '00CCFFFF', '00660066', '00FF8080', #25-29
'000066CC', '00CCCCFF', '00000080', '00FF00FF', '00FFFF00', #30-34
'0000FFFF', '00800080', '00800000', '00008080', '000000FF', #35-39
'0000CCFF', '00CCFFFF', '00CCFFCC', '00FFFF99', '0099CCFF', #40-44
'00FF99CC', '00CC99FF', '00FFCC99', '003366FF', '0033CCCC', #45-49
'0099CC00', '00FFCC00', '00FF9900', '00FF6600', '00666699', #50-54
'00969696', '00003366', '00339966', '00003300', '00333300', #55-59
'00993300', '00993366', '00333399', '00333333', #60-63
)
BLACK = COLOR_INDEX[0] # 黑色 00000000
WHITE = COLOR_INDEX[1] # 白色 00FFFFFF
RED = COLOR_INDEX[2] # 红色 00FF0000
BLUE = COLOR_INDEX[4] # 蓝色 000000FF
GREEN = COLOR_INDEX[3] # 绿色 0000FF00
YELLOW = COLOR_INDEX[5] # 黄色 00FFFF00
代码调用:
sheet['B3'] = datetime.datetime.now().strftime('%Y-%m-%d %X')
# 声明样式
myfont = Font(name='等线', size=24, color=colors.Color(index=2), italic=False, bold=True)
sheet['B3'].font = myfont
设置行高、列宽
- 行的高度可以设置为0~409之间的整数或浮点值。这个值表示高度的点数。一个点等于1/72英寸。默认的行高是12.75。
- 列宽可以设置为0~255之间的整数或浮点数。这个值表示使用默认字体大小时(11点),单元格可以显示的字符数。默认的列宽时8.43个字符。
- 列宽为零或行高为零,将是单元格隐藏。
# 设置行高、列换。 第三行行高为40,B列列宽为40
sheet.row_dimensions[3].height = 40
sheet.column_dimensions['B'].width = 40
单元格合并
merge_cells()
# merge_cells
# 方式一:
sheet.merge_cells(start_column=2, end_column=3, start_row=3, end_row=8)
# 方式二:
sheet.merge_cells('B3:C8')
拆分单元格
unmerge_cells()
# 方式一:
sheet.unmerge_cells(start_column=2, end_column=3, start_row=3, end_row=8)
# 方式二:
sheet.unmerge_cells('B3:C8')
冻结窗格
-
freeze_panesworksheet对象都有一个freeze_panes属性,可以设置为一个Cell对象或一个单元格坐标的字符串。
请注意:单元格上边的所有列都会冻结,但单元格所在的行和列不会冻结。
-
要解冻所有的单元格,就将freeze_panes设为None 或’A1’
freeze_panes的设置 冻结的行或列 sheet.freeze_panes=‘A2’ 行1 sheet.freeze_panes=‘B1’ 列A sheet.freeze_panes=‘C1’ 列A和列B sheet.freeze_panes=‘C2’ 行1和列A和列B sheet.freeze_panes=‘A1’ 解除冷冻窗格 sheet.freeze_panes=None 解除冷冻窗格
2.2PDF和Word文件操作
待补充
三、网络
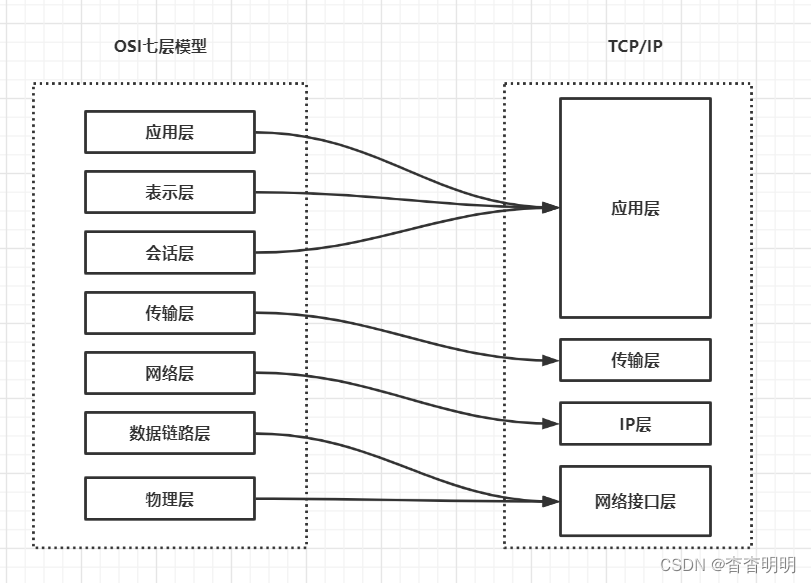
协议与OSI七层模型
OSI七层模型与TCP/IP协议
ISO 国际化标准组织 认证
- 应用层:各种应用程序,使用网络的第一个层环节。
- 表现层:数据的格式化,加密解密,压缩解压缩。
- 会话层:建立,管理,终止应用之间的会话连接。
- 传输层:提供端到端的数据服务,可靠不可靠。
- 网络层:逻辑寻址,路由选择
- 数据链路层:将分组数据分装成帧
- 物理层:在介质上传输比特,提供物理规约
优点
- 建立统一通信标准
- 降低开发难度,明确各层分工。
TCP/IP模型
七层模型太过复杂,工作应用实践难度大,所以简化成了TCP/IP模型
- 应用层:HTTP、FTP、SMTP、DNX…等应用协议
- 传输层:TCP、UDP
- 网络层:IP、ARP、RARP、ICMP
- 网络接口层:各种通信网络接口
通信地址
IP地址
- 一台计算机在网络当中的地址编号标识
IPV4
- 由4个部分组成,每个部分都是整数,取值范围0~255。 例如:192.168.0.6
IPV6
- 由8个部分组成,每个部分4个16进制数字
公网IP/内网IP
- 公网IP:连接到互联网上的公共IP地址,大家都能访问。
- 内网IP: 局域网范围由网络设备分配的地址,不能被主动访问。
windows查看ip:ipconfig
linux查看ip:ifconfig
查看网络连通命令:ping ip/网址
端口
- 在linux系统中,端口可以有65536(2的16次方)个之多
端口号
- 端口是通过端口号来标记的,端口号只有整数,范围从0 ~ 65535
知名端口号
- 知名端口号是众所周知的端口号,范围从0 ~ 1023
- 80端口分配给HTTP服务
- 21端口分配给FTP服务
动态端口
- 动态端口的范围是1024到65535
socket套接字概念
socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中mSocket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
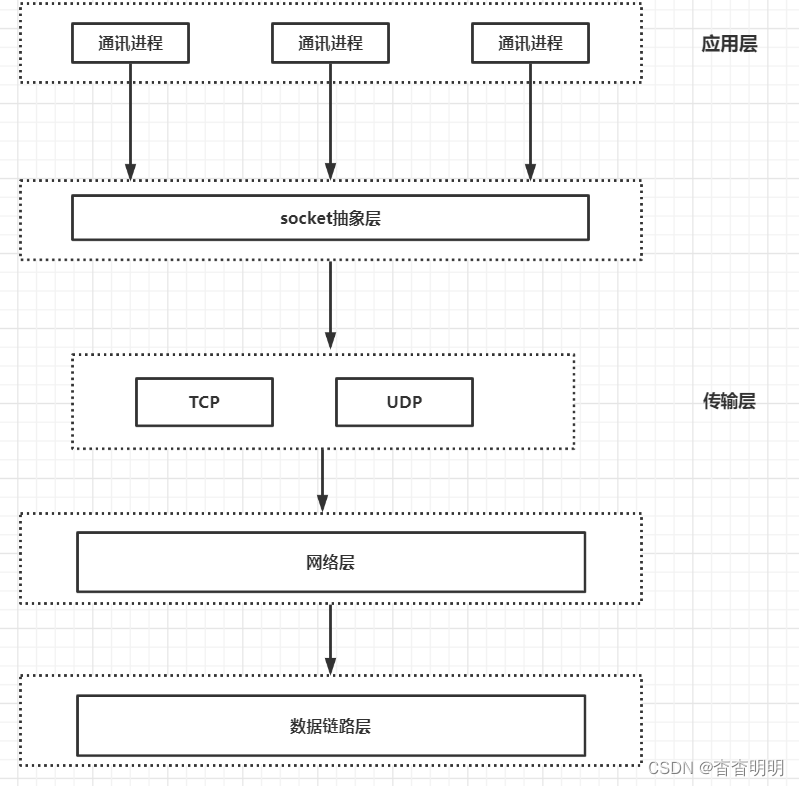
应用层的一种编程方法
socket(): 创建套接字bind(): 绑定IP端口sendto(): 发送消息recvfrom(): 接受消息close(): 关闭套接字
函数 socket.socket 创建了一个socket,该函数带有两个参数:
Address Family: 可以选择AF_INET(用于Internet进程间通讯)或者AF_UNIX(用于同一台机器进程间通信),实际工作中常用AF_INET。Type: 套接字类型,可以是SOCK_STREAM(流式套接字,主要用于TCP协议)或者SOCK_DGRAM(数据报套接字,主要用于UDP协议)
创建一个tcp socket(TCP套接字)
import socket
# 创建tcp套接字
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# ...这里是使用套接字的功能(省略)
# 不用的时候, 关闭套接字
s.close()
创建一个udp socket(UDP套接字)
import socket
# 创建udp套接字
s = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
# ...这里是使用套接字的功能(省略)
# 不用的时候, 关闭套接字
s.close()
udp网络程序-发送、接受数据
创建一个基于udp的网络程序流程。 具体如下:
- 创建客户端套接字
- 发送/接受数据
- 关闭套接字
网络调试助手netassist5.0.3
下载netassist5.0.3链接: https://pan.baidu.com/s/127m1luohc4uDknBmIDH0fA 提取码: yymm
代码如下:
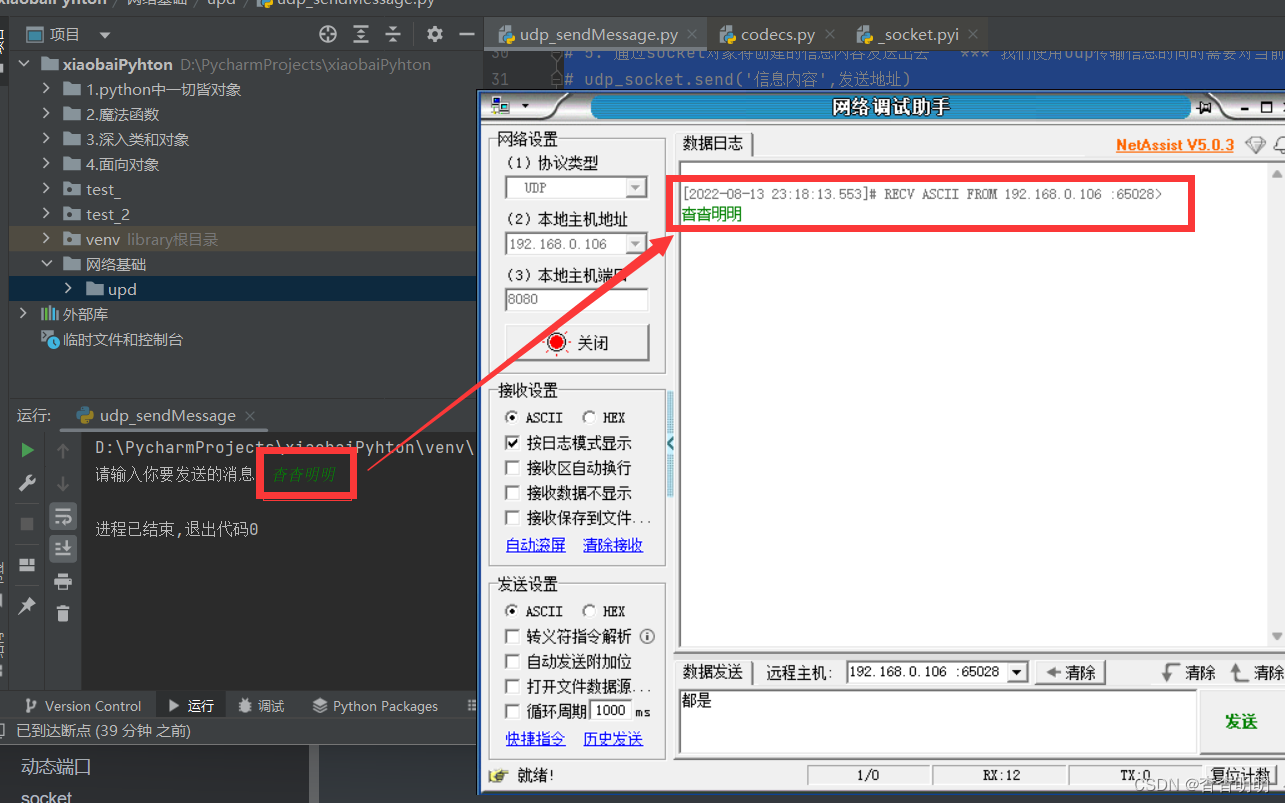
udp发送消息:
# 第一步 内置了socket方法
# 导入socket
import socket
# 2. 通过python内置的socket方法创建套接字对象
'''
创建udp 套接字需要两个参数
ip协议类型
ipv4
ipv6
套接字类型
tcp
udp
'''
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 3. 指定发送地址
'''
ip:电脑
port:应用程序
'''
# dest_address = ('ip地址', 端口)
dest_address = ('192.168.0.106', 8080)
# 4. 创建要发送的信息内容
send_message = input('请输入你要发送的消息:')
# 5. 通过socket对象将创建的信息内容发送出去 *** 我们使用udp传输信息的同时需要对当前信息内容进行编码
# udp_socket.send('信息内容',发送地址)
udp_socket.sendto(send_message.encode('utf-8'), dest_address)
# 6. 发送完消息之后关闭套接字 并释放端口就资源
udp_socket.close()
udp接受消息:
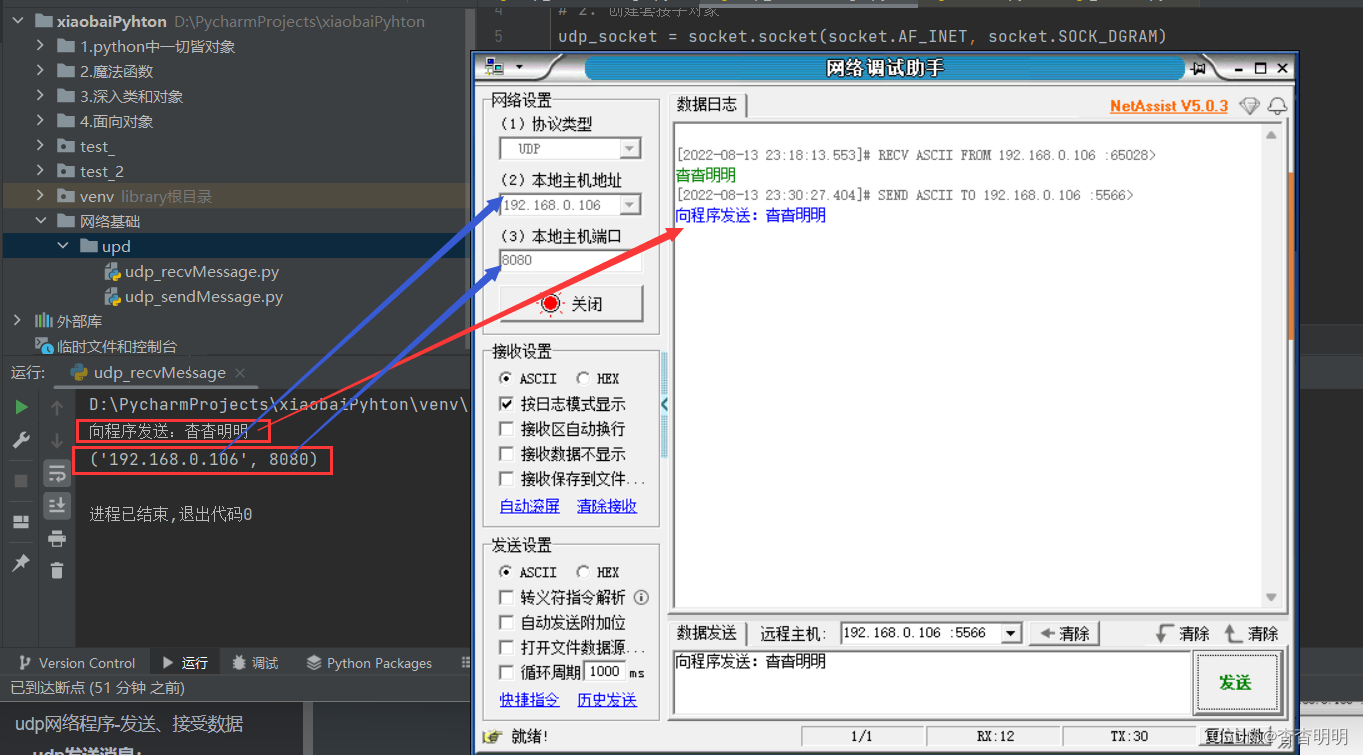
代码如下
# 导入socket
import socket # 需要使用 socket.socket()
# from socket import * # 使用socket() 就可以。
# 2. 创建套接字对象
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 3. 绑定本机信息
localhost_address = ('', 5566) # 如果ip地址为空字符串 默认绑定本机ip
udp_socket.bind(localhost_address)
# 4. 等待向本机发送信息
'''
1024 : 本次能够接收的最大信息字节数
当接收都信息之后返回的类型是一个元组
第一个元素是信息内容
第二个元素是当前发送放的ip和port
'''
recv_message = udp_socket.recvfrom(1024)
# 显示 接收信息之后需要对信息进行解码,否则会出现内容乱码
print(recv_message[0].decode('utf-8'))
print(recv_message[1])
# 关闭套接字
udp_socket.close()
udp简单的聊天软件
import socket
# 数据发送
def send_message(udp_socket):
# 1. 获取用户要发送的消息
msg = input('请输入要发送的消息:')
# 2. 输入对方的IP地址
dest_ip = input('请输入对方的ip地址:')
# 3. 输入对方的port 必须是一个int类型 强转
try:
dest_post = int(input('请输入对方的端口号:'))
# 4. 发送数据
udp_socket.sendto(msg.encode('utf-8'), (dest_ip,dest_post))
except Exception as e:
print('请输入一个正确的端口号,错误类型为:%s' % e)
# 接受数据
def recv_message(udp_socket):
# 1. 接受数据
recv_msg = udp_socket.recvfrom(1024)
# 2. 数据解码
recv_ip_port = recv_msg[1]
recv_msg_data = recv_msg[0].decode('utf-8')
print(f'消息内容:{recv_msg_data},发送方的地址与端口:{recv_ip_port}')
# 创建一个主函数
def main():
# 1. 创建套接字
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2. 绑定本机信息 接受发送方传递过来的信息
udp_socket.bind(('', 5567))
# 3. 因为之前所编写的udp程序只能运行一次, 但是我们在接受消息的时候必须要保证当前程序没有退出。
# 死循环保证当天聊天工具一直在运行
while True:
# 设计功能
print('=' * 30)
print('1 发送消息')
print('2 接受消息')
print('=' * 30)
op_num = input('请输入您要操作的功能序号:')
# 针对用户输入的序号进行功能调用
if op_num == '1':
# 发送消息
send_message(udp_socket)
pass
elif op_num == '2':
# 接受消息
recv_message(udp_socket)
pass
else:
print('输入有误,请重新输入序号。')
# 创建测试入口
if __name__ == '__main__':
main()
udp套接字特点:
- 可能会出现数据丢失
- 传输过程简单,实现容易
- 数据以数据包的形式传输
- 数据传输效率高
TCP套接字
面向连接的传输服务
- 提供了可靠的数据传递,
传输过程中无丢失、无失序、无差错、无重复 - 可靠性保障机制(自动完成)
- 在通信之前需要简历数据连接
- 确认应答机制
- 通讯结束后正常断开连接
三次握手(连接)
- 客户端向服务器发送报文请求连接
- 服务收到请求回复报文可连接
- 客户端收到回复再次发送报文建立连接
四次挥手(断开)
- 发送方发送报文请求断开
- 接收方收到请求回复信息收到,并准备断开
- 接收方准备完成,再次发送表示可以断开
- 发送方收到确定,发送最终消息完成断开
TCP套接字细节
- tcp连接中一端退出,另一个端依然阻塞在recv,此时recv会马上返回一个空字符串
- 如果一端已经不存在,任然通过send向其发送数据则会产生BrokenPipeError
- 一个服务端可以同时连接多个客户端,也能够被重复连接。
TCP编程流程
socket: 创建套接字bind:绑定地址listen: 设置监听accept: 等待处理连接send/recv: 发送/接受消息close: 关闭连接
tcp接受消息
# 开发者:杳杳明明
# 目的:学习Python
# 开发时间:2022/8/21 14:42
# 1. 导入模块
from socket import *
# 创建套接字
tcp_socket = socket()
# 连接服务端
tcp_socket.connect(('127.0.0.1', 8888))
# 发送消息
msg = input('>>:')
tcp_socket.send(msg.encode())
# 关闭连接
tcp_socket.close()
tcp发送消息
# 开发者:杳杳明明
# 目的:学习Python
# 开发时间:2022/8/21 14:35
from socket import *
# 创建套接字。 默认时TCP, 流式套接字
tcp_socket = socket(AF_INET, SOCK_STREAM)
# 绑定地址
tcp_socket.bind(('0.0.0.0', 8888))
# 设置监听 listen 最多设置1024 linux自动配置
# 具备了监听的属性,被客户端连接的属性
tcp_socket.listen(5)
# 等待处理客户端的连接
print('等待客户端连接中...')
# acceept 阻塞函数,处理客户端的连接请求,没有连接则阻塞。
# connfd 处理该连接的专门套接字
connfd, addr = tcp_socket.accept()
print('连接的客户端是:', addr)
# 接受处理客户端的信息
data = connfd.recv(1024)
print('消息:', data.decode())
# 关闭连接
connfd.close()
tcp_socket.close()
文件传输服务端
服务端:
# 开发者:杳杳明明
# 目的:学习Python
# 开发时间:2022/8/21 15:15
"""
1、建立TCP套接字
2、等待客户端内连接
3、接受图片内容
4、保存图片
5、终止连接
"""
# 导入模块
from socket import *
import time
# 创建套接字
socket = socket()
# 绑定IP
socket.bind(('0.0.0.0', 8888))
# 设置监听
socket.listen(5)
# 创建connef
connfd, addr = socket.accept()
# 接收客户端的数据
data = connfd.recv(1024 * 1024)
# 用时间戳作为文件的名字
file_name = str(time.time()).split('.')[0]+str(time.time()).split('.')[1]
file_name_jpg = f'{file_name}.jpg'
f = open(file_name_jpg, 'wb')
f.write(data)
f.close()
# 关闭连接
connfd.close()
socket.close()
客户端:
# 开发者:杳杳明明
# 目的:学习Python
# 开发时间:2022/8/21 15:32
"""
1、创建套接字
2、连接服务端
3、读取文件内容
4、发送文件内容
5、关闭连接
"""
# 导入模块
from socket import *
# 创建套接字
socket = socket()
# 连接服务端
socket.connect(('127.0.0.1',8888))
# 读取文件内容
f = open(r'C:\Users\62547\Pictures\Camera Roll\2.jpg','rb')
data = f.read()
# 发送文件内容
socket.send(data)
# 关闭连接
f.close()
socket.close()
粘包问题
- 产生原因
- 为了解决数据传输中的速率不协调问题,操作系统设置了缓冲区
- 实际网络过程比较复杂,导致消息收发不一致。
- tcp以字节流方式进行数据传输,在接受的时候不区分消息边界。
- 带来问题
- 如果发送的消息每次都是独立的,需要接受端取独立解析消息时会带来消息误解问题
- 解决方式
- 人工设置消息边界
- 减缓消息发送速度
使用场景
- tcp适合对准确要求高,传输数据大的场景
- 文件传输:数据下载(电影、音乐),上传图片,访问网站
- 邮箱发送
- 点对点数据传输:登录、远程、红包、一对一聊天
- upd适合可靠性要求相对不高,传输自由的场景
- 视频流:直播、视频聊天
- 广播:网络广播、群发消息
- 实时性要求高:如游戏等
四、进程
进程主要类跟函数(方法)使用
-
Process:创建进程对象
-
target:绑定执行的目标函数
-
args(元组):给target函数位置传参
-
kwargs(字典):给target函数键值传参
-
start(): 启动进程
-
join(): 回收资源,等待子进程完成
-
name:为当前进程实例的别名
-
terminate():不管任务是否完成,立即终止
-
使用进程示例:
模块:multiprocessing
import multiprocessing创建步骤:
- 将需要新进程执行的事件分装成函数
- 通过模块的Process类创建进程对象,关联函数
- 通过进程对象设置进程信息与属性
- 通过进程对象调用start启动进程
- 通过进程对象调用join回收资源
-
示例代码
-
无参进程
# 开发者:杳杳明明 # 目的:学习Python # 开发时间:2022/8/21 16:32 # 导入模块multiprocessing import multiprocessing from time import sleep # 创建进程执行的函数 def fun(): print('子进程函数开始执行...') # 睡眠模拟程序执行 sleep(2) print('子进程函数执行完成...') # windows系统下,必须把子进程相关代码放入if。 linux 不需要 if __name__ == '__main__': # 创建子进程进程对象 pro = multiprocessing.Process(target=fun) # 启动子进程,进程诞生并开始执行fun函数 pro.start() # 模拟主进程的执行 print('主进程开始执行...') sleep(5) print('主进程执行完成...') # 收回 pro.join() -
有参进程
# 开发者:杳杳明明 # 目的:学习Python # 开发时间:2022/8/21 16:40 from multiprocessing import Process from time import sleep # 创建包含参数的进程函数 def emp(sec, name): for i in range(3): sleep(sec) print('my name is %s' % name) # 创建主进程 if __name__ == '__main__': # 位置传参 # pro = Process(target=emp, args=(2, '杳杳明明')) # 关键字传参 pro = Process(target=emp, kwargs={'name': '杳杳明明', 'sec': 4}) # 执行 pro.start() # 回收 pro.join()
-
进程的属性
process.daemon = True: 设置True 子进程随父进程的退出而推出。 在start()之前设置process.name: 查看进程的名字process.pid: 查看进程的IDprocess.is_alive():查看进程的存活状态
# 开发者:杳杳明明
# 目的:学习Python
# 开发时间:2022/8/21 17:01
import time
from multiprocessing import Process
from time import sleep
from time import localtime
from time import strftime
def fun():
for i in range(5):
# 打印时间
print(strftime('%Y-%M-%d %X', localtime()))
sleep(3)
if __name__ == '__main__':
pro = Process(target=fun)
# 设置True 子进程随父进程的退出而推出。 在start()之前设置
pro.daemon = True
pro.start()
# 查看进程id
print(pro.pid)
# 16148
# 查看进程名字
print(pro.name)
# Process-1
# 查看进程的存活状态
print(pro.is_alive())
# True
'''
os.getpid 获取子进程
os.getppid 获取父进程
sys.exit 退出进程
'''
进程——多子进程
# 开发者:杳杳明明
# 目的:学习Python
# 开发时间:2022/8/21 17:12
from multiprocessing import Process
import time, os, sys
# 创建多个函数
def fun1():
time.sleep(2)
print('看书')
print(os.getppid(), '----', os.getpid())
def fun2():
time.sleep(2)
print('听歌')
print(os.getppid(), '----', os.getpid())
def fun3():
time.sleep(2)
print('睡觉')
print(os.getppid(), '----', os.getpid())
if __name__ == '__main__':
# 函数列表
process_list = [fun1, fun2, fun3]
# 回收列表
jobs = []
# 循环执行多个进程
for fun in process_list:
p = Process(target=fun)
jobs.append(p)
p.start()
# 循环回收
for i in jobs:
i.join()


















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











