







一 JPEG编码原理
首先我们先来看一下JPEG的编码原理图
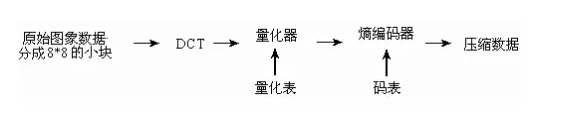
如上图所示,下面进行逐步的分析:
1 RGB->YUV
首先为了降低互相的关联性,将RGB转换为YUV,这样就可以对亮度信号和色度信号进行分别的处理
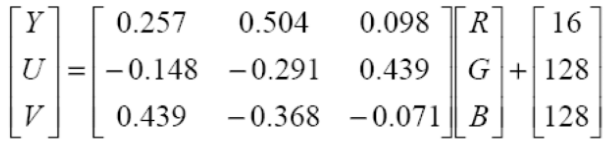
2 零电平偏置下移
由于后面需要对图像进行DCT变换,如果不进行偏移,会使分量值过大,所以在这里采用偏置下移的方法,便于DCT变换量化后直流的系数大大降低,也就降低了数据量。
3 分块
JPEG标准在处理图片时会先把图片分割成一个个8x8像素的方块,源图像如果不是8x8的整数倍,需进行补充,后面的DCT、量化、熵编码都是针对单个方块的操作,编码的产物是这些方块的压缩数据。压缩数据经过解码还原成像素数据,然后将一个个方块拼成一整完整图片的像素数据显示。
4 DCT变换
对每一块进行DCT变化,目的是去除图像数据之间的相关性,便于量化过程去除图像数据的空间冗余。由于人眼对图片中的低频信息(色彩变化不明显,如图片的整体色调,物体轮廓)比较敏感,对高频信息不敏感(色彩变化剧烈,如物体的边缘、人脸上的小斑点),因此我们可以利用DCT变换把图片中高频和低频部分区分开来,然后将高频部分的数据进行压缩,这样就达到压缩图片的功能。
二维DCT变换公式如下所示
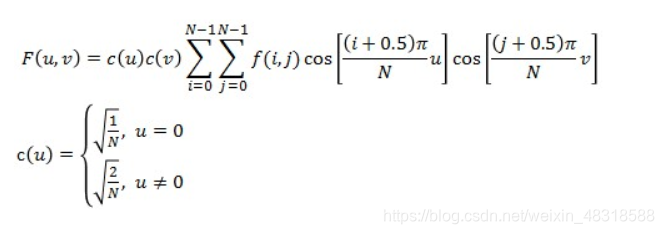
需要特别强调的是,DCT是一种无损变换,这样做的目的是在为下一步的量化做准备。
5 量化
所谓量化其实就是将频率/量化步长,将量化步长以内的精度信息丢失,JPEG算法提供了两张标准的量化系数矩阵,如下所示

可以看出越往左上角,值越小,因此这张量化表的作用就是屏蔽高频信息。
6 压缩
在这里直流分量与交流分量采用了不同的压缩方法。
对于直流分量来说,量化后每一块所得的数值比较大,但相邻块之间的差值比较小,这就很适合采用DPCM的压缩方式,在之前的博客中有较为详细的介绍,但DPCM之后还不够,还要进行霍夫曼编码,进行进一步的压缩
对于交流分量来说,每一块中剩余的交流分量都比较小,JPEG先用RLE(run-length encoding,游程编码)编码将图像数据以“之字形”排列,如下图,这样可以尽可能的将频率为0的数据存储在一起。连续N个0,可以用一个0和一个长度N来表示,压缩效果很好,然后将剩下的位置使用霍夫曼编码。
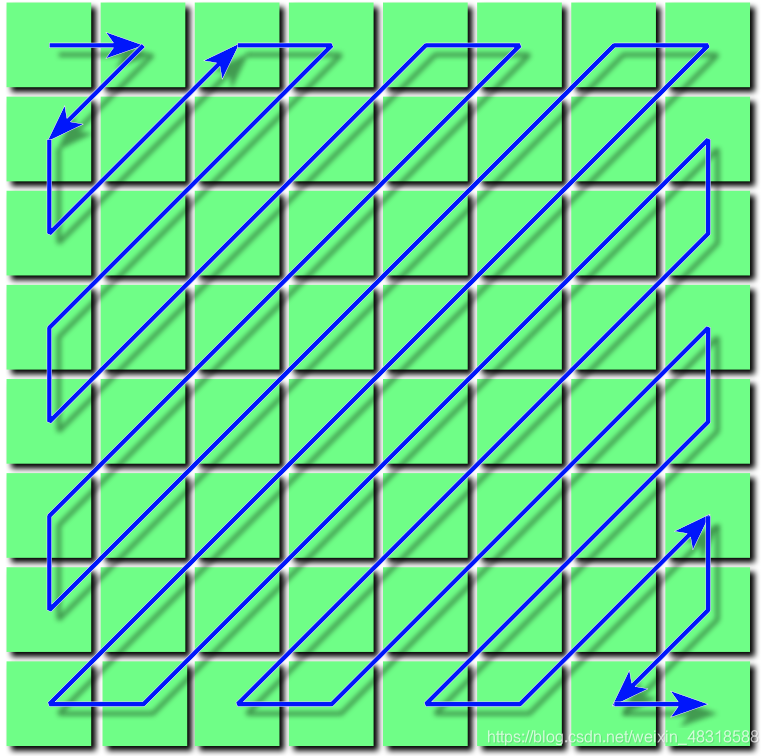
在这里说一句,JPEG的解码就是将其编码过程倒过来,进行一步一步的还原,在这里就不细说了。
二 JPEG文件格式
JPEG文件由一系列字段组成,每个字段都有marker(标记),由0xff开头。接下来对每一个字段进行简要的说明
1 SOI
这个字段定义了文件的起始标记,标记为FFD8。
2 APP0
Application,应用程序保留标记0,标志FFE0,包含一定信息
① 数据长度 2字节 ①~⑨9个字段的总长度
即不包括标记代码,但包括本字段
② 标识符 5字节 固定值0x4A46494600,即字符串“JFIF0”
③ 版本号 2字节 一般是0x0102,表示JFIF的版本号1.2
可能会有其他数值代表其他版本
④ X和Y的密度单位 1字节 只有三个值可选
0:无单位;1:点数/英寸;2:点数/厘米
⑤ X方向像素密度 2字节 取值范围未知
⑥ Y方向像素密度 2字节 取值范围未知
⑦ 缩略图水平像素数目 1字节 取值范围未知
⑧ 缩略图垂直像素数目 1字节 取值范围未知
⑨ 缩略图RGB位图 长度可能是3的倍数 缩略图RGB位图数据
3 DQT
也就是量化表,JPEG文件一般有2个DQT段,为Y值(亮度)定义1个, 为UV值(色度)定义1个。每张量化表都由FFDB开始,量化表中的第一个字节被分成了高四位和低四位来用。高四位表示了该量化表的精度,0:8位;1:16位;低四位表示了量化表ID,取值范围为0~3;接下来是所有的表项,数量为(64×(精度+1))字节,里面都是量化的系数。量化表中的数据按照Z字形保存量化表内8x8的数据
4 SOF0
标志位FFC0,包含图像基本信息
段标识 1 FF
段类型 1 C0
段长度 2 其值=8+组件数量×3
(以下为段内容)
样本精度 1 8 每个样本位数(大多数软件不支持12和16)
图片高度 2
图片宽度 2
组件数量 1 3 1=灰度图,3=YCbCr/YIQ 彩色图,4=CMYK 彩色图
(以下每个组件占用3字节)
组件 ID 1 1=Y, 2=Cb, 3=Cr, 4=I, 5=Q
采样系数 1 0-3位:垂直采样系数
4-7位:水平采样系数
量化表号 1
5 DHT
标志位FFC4,存放哈夫曼表,JPEG文件里有2类Haffman 表:一类用于DC(直流量),一类用于AC(交流量)。一般有4个表:亮度的DC和AC,色度的DC和AC。最多可有6个。该Marker以FFC4作为开始标记。然后是字段长度,类型(AC/DC),索引(Index),位表(bit table),值表(value table)。
6 SOS
扫描行开始,标志位FFDA,表明了字段的长度,然后说明了颜色分量数,该与SOF字段中的数据应该是保持一致的。然后针对于每一个颜色分量信息,给出了每个分量的DC/AC使用的哈夫曼表编号。
三 代码解读
本次实验主要做到了JPG文件转换为YUV文件,并且输出了量化系数以及霍夫曼码表。
首先先来看一下如何写入YUV文件,原先的代码为分别生成.Y .U .V文件,其实只需要将这三个写入的数据按照YUV的顺序写入YUV文件即可,具体代码如下所示
static void write_yuv(const char *filename, int width, int height, unsigned char **components)
{
FILE *F;
char temp[1024];
snprintf(temp, 1024, "%s.Y", filename);
F = fopen(temp, "wb");
fwrite(components[0], width, height, F);
fclose(F);
snprintf(temp, 1024, "%s.U", filename);
F = fopen(temp, "wb");
fwrite(components[1], width*height/4, 1, F);
fclose(F);
snprintf(temp, 1024, "%s.V", filename);
F = fopen(temp, "wb");
fwrite(components[2], width*height/4, 1, F);
fclose(F);
snprintf(temp, 1024, "%s.YUV", filename);
F = fopen(temp, "wb");
fwrite(components[0] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 583
583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









