







dpdk内存模块整体概述
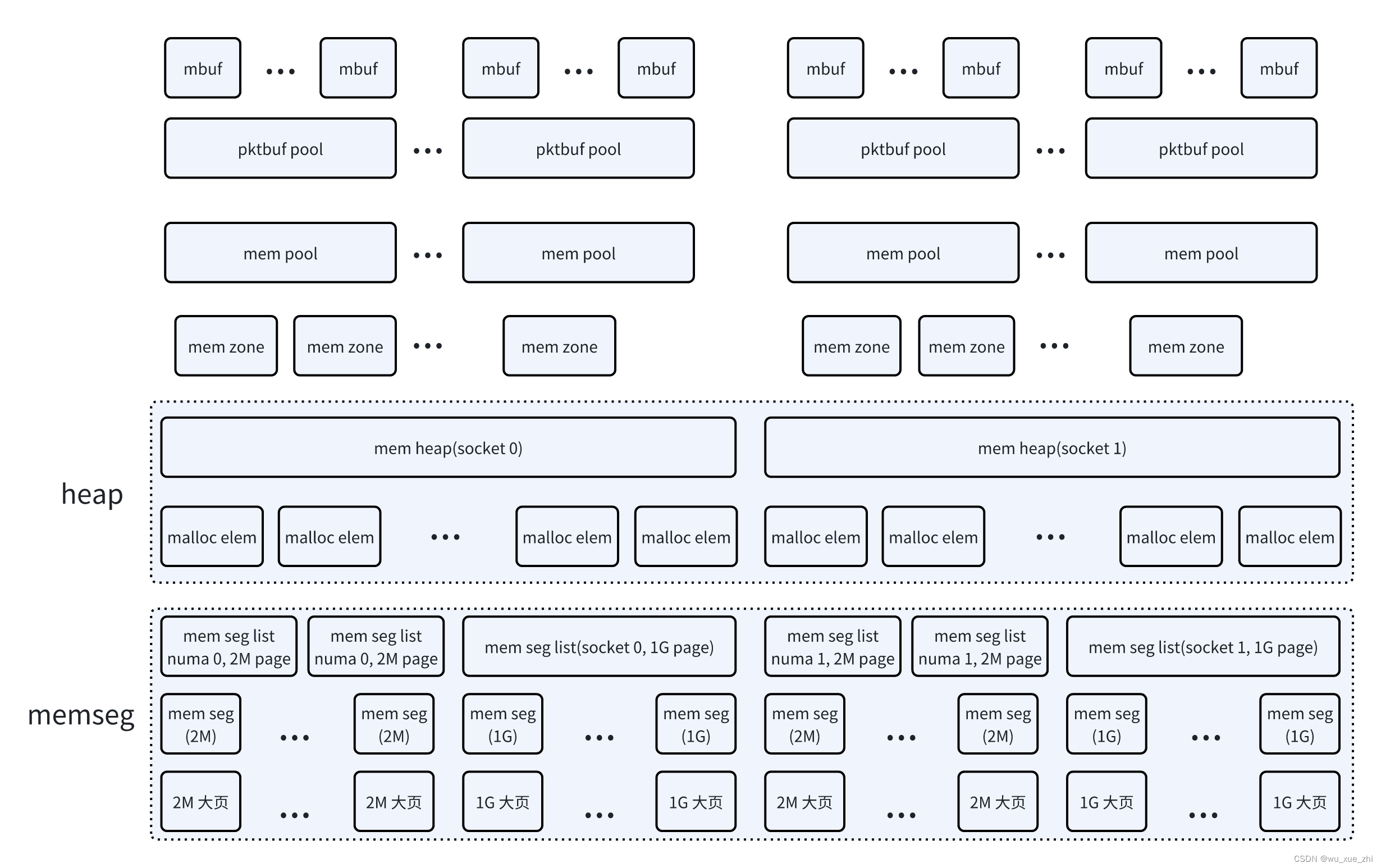
DPDK的内存管理框架,从底层往上依次为:
-
大页系统。
-
获取系统的大页信息。包括各种大页类型,及其可用大页的数目。
-
获取大页文件系统mount的目录(可以参数指定,--huge-dir <path to hugetlbfs directory>),将要创建的大页文件的前缀<hugefile-prefix>(可以参数指定,--file-prefix)
-
每个大页文件系统指定的页的大小是固定的,因此不同页大小的大页,mount的目录是不一样的。--huge-dir参数指定的是一个部分匹配的参数,可以作为前缀和后缀,取匹配系统mount文件信息,找到匹配的mount目录。
-
-
memseg。按照配置参数,创建大页文件,映射大页内存地址。
-
按照配置参数--socket-mem或-m,计算出各个socket需要的各种大页个数。
-
优先使用页面大的大页
-
每个大页对应一个mem seg,需要在指定的大页文件系统目录下,创建一个大页文件。文件名为<hugefile-prefix>map_<index>
-
相同页面大小的mem seg放在一个mem seg list中管理。由于一个mem seg list中存放的mem seg有最大值限制,因此,存放相同页面大小的mem seg,可能会存放在多个mem seg list中。
-
-
malloc heap。用于rte相关的申请、释放内存。
-
每个socket一个heap。
-
会将初始化的mem seg list,按照所在的socket,存放在对应的heap中。
-
每个heap中,按照不同的内存大小(256B、1kB、4kB、16kB...1GB、4GB),管理多个free mem list。初始化时,每个mem seg list作为一个大的空闲内存块,作为一个malloc_elem管理起来,放在一个对应的free mem list中。
-
当要从heap中申请内存时,按照内存大小,到对应的free mem list中申请。如果对应free mem list为空,则找一个较大的free mem list申请。
-
在一个free mem list的成员,即一个malloc_elem中申请内存时,根据申请的大小,以及对齐要求,可能会把malloc_elem切分为两个malloc_elem或三个malloc_elem。其中一个返回给上层应用使用,剩下的两个重新按照大小,放在对应的free mem list中。
-
-
memzone。在对应的heap中申请一块内存,并管理申请的内存信息(其中包含iova地址信息)。
-
可以指定在哪个socket上申请
-
可以指定在哪些大页上申请。
-
可以指定是否需要物理地址连续。
-
可以指定申请内存的对齐要求和边界要求
-
-
mempool。申请固定大小的内存块,并作为一个obj pool管理。
-
申请大块的memzone,并自己切割成多个obj。
-
优先申请一个可以容纳所有obj的memzone。如果申请不到,则内存大小减半,申请memzone。因此最终一个mempool可能申请了多个memzone,分别在每个memzone中切割出多个obj。
-
默认情况下,为了让每个obj,在不同的物理内存的channel和rank上均匀分布,会调整obj实际占用内存的大小。这一特性目前只在x86环境下生效,为了实现这一特性,需要指定-n <number of channels>和-r <number of ranks>参数。可以指定不需要该特性(RTE_MEMPOOL_F_NO_SPREAD)
-
切割obj时,需要保证每个obj的对齐要求。且obj不能跨物理页存储。
-
默认申请的obj是物理地址连续的,可以指定不需要物理地址连续,这样可以节省内存。
-
-
pktbuf pool。 基于mempool管理的mbuf pool。
dpdk初始化memory的流程如下:
总的流程:
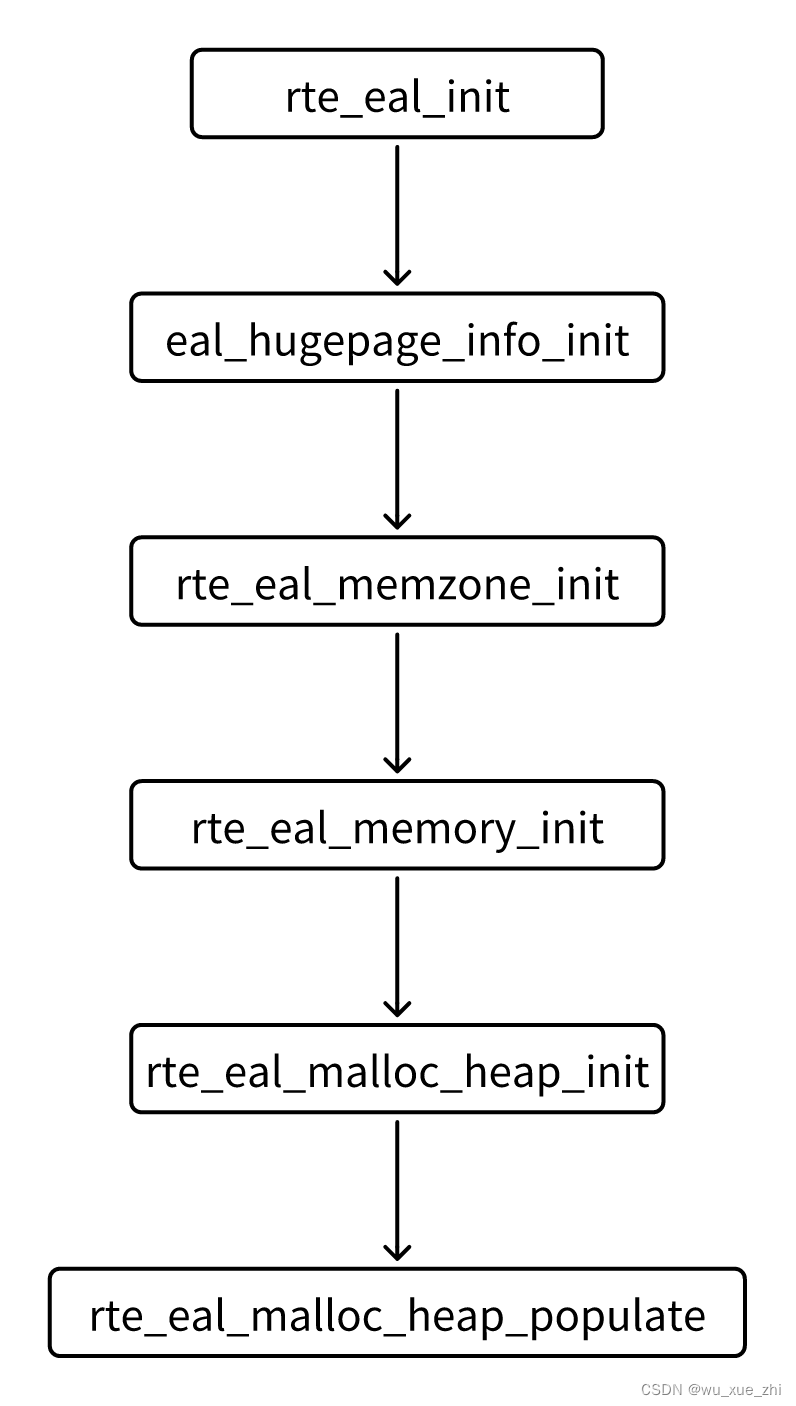
eal_hugepage_info_init

注:为了避免不同的dpdk应用程序的冲突,建议指定--file-prefix参数
注:系统有如下大页统计信息:

- free_hugepages:总的可用大页个数,包括resv_hugepages的个数
- resv_hugepages:已经被应用程序分配但尚未使用的 HugePages 数量(mmap了,但是没有实际读写)
- nr_overcommit_hugepages:动态超配的大页个数配置值(最大可以动态超配的大页个数)
- surplus_hugepages:实际已经超配的大页个数
- 实际可用大页个数 = free_hugepages - resv_hugepages + nr_overcommit_hugepages - surplus_hugepages
rte_eal_memzone_init
主要是初始化rte_config.mem_config->memzones

memzones是struct rte_fbarray数据结构(File-backed shared indexed array),用该数据结构管理struct rte_memzone数组。

rte_eal_memory_init
依次执行下面几个函数:
-
rte_eal_memseg_init
-
eal_memalloc_init
-
rte_eal_hugepage_init
rte_eal_memseg_init
-
通过linux的getrlimit和setrlimit,设置进程可以打开文件的最大值(dpdk会打开很多文件)
-
memseg_primary_init(),调用eal_dynmem_memseg_lists_init(),开始初始化rte_config.mem_config->memsegs。 具体数据结构如下图所示:

按照每个socket下的每个大页类型来分配memseg_list,需要计算出每个需要分配多少个memseg_list,
以及每个memseg_list下,需要多少个mem seg。按照配置的最大值来分配,而不管当前系统实际有多少大页。
具体算法如下:
-
为每个socket下,每种大页类型分配memseg_list资源。各个socket下的各种大页类型,期望分配的最大的内存大小一样。按照支持的最大内存(512GB)平均分配,或者RTE_MAX_MEM_MB_PER_TYPE(默认配置65536MB)来设置,各个socket下的各种大页类型的最大内存值。
但是由于如下一些个性化的限制(.config文件可修改),各个socket下的各种大页类型的实际最大内存值可能有所修正:
-
每个类型的seg list的最大个数。RTE_MAX_MEMSEG_LISTS(默认配置128)/总类型数(socket个数*大页类型数)
-
每个seg list下seg mem最大个数。RTE_MAX_MEMSEG_PER_LIST(默认配置8192)
-
每个类型的seg mem最大个数的限制。RTE_MAX_MEMSEG_PER_TYPE(默认配置32768)
-
-
根据如上信息计算出,分配给各个socket下的各种大页类型的,memseg_list的个数,以及每个memseg_list下mem seg的个数。同一种大页类型,不管在哪个socket下,其memseg_list的个数相同,且每个memseg_list下的mem seg的个数相同。
-
以2个socket,2个大页类型(2M和1G)为例,来说明实际的分配过程和结果:
-
每socket,每大页类型,分配65536MB=64GB内存(RTE_MAX_MEM_MB_PER_TYPE=65536)。
-
对于2M的大页,总共需要64*1204MB/2MB=32768个seg mem,但是由于一个seg list最多只能有RTE_MAX_MEMSEG_PER_LIST(8192)个seg mem,因此需要分为多个seg list(32768/8192=4)存放。由于每个类型的seg list的最大个数为:RTE_MAX_MEMSEG_LISTS/总类型数=128/(2*2)=32,没有超过该最大值。因此可以为2M的大页,分配4个seg list,每个seg list内存为16G,每个里面有8192个2M大小的seg mem(对应一个2M的大页)。
-
对于1G的大页,总共需要64GB/1GB=64个seg mem,因此一个seg list就够了。该seg list总大小为64G,下面有64个1G大小的seg mem(对应一个1GB的大页)
-
rte_eal_memseg_init分配完seg list之后,对每个seg list,map了一个虚拟地址,并没有对该地址进行读写,因此这些虚拟地址实际并没有对应的物理内存,留待后面进一步处理。上面的例子中,只使用了10个seg list,memsegs数组中剩下的数组成员,没有初始化,其page_sz为0。
eal_memalloc_init
主线流程为遍历有效的seg list,调用fd_list_create_walk。最终效果是给每个seg list下的每个seg mem创建一个存储对应文件描述符的数据实体:全局数组fd_list[]。

注:如果存在--single-file-segments的配置参数,则不会为每个seg mem申请一个fd。
rte_eal_hugepage_init
主线流程调用的是eal_dynmem_hugepage_init()。该函数具体实现如下:
-
根据配置计算各个socket需要使用的大页类型,以及该类型的大页的个数。(优先使用页面大的大页类型)
-
配置包括--socket-mem指定各个socket要使用的内存大小。
-
如果没有指定--socket-mem,则使用-m参数指定的总的内存的大小,然后根据当前的work cpu在各个socket上的分布,来计算各个socket要使用的内存的大小。
-
-
根据每个socket需要的大页类型及其数量,遍历seg list,分配seg mem(前面rte_eal_memseg_init已经按照最大的内存,初始化了seg list,并创建了seg list下的seg mem fbarray数组,但没有初始化seg mem实体)。这里按照实际配置参数指定的内存需求,获取指定数量的seg mem,创建大页映射。具体做法如下:
-
从seg list下,申请指定数量的空闲的seg mem,对于指定的socket和大页类型,如果一个seg list下的seg mem数量不够,可能从多个seg list下获取seg mem。(此时seg list下的seg mem都是空闲的)。被申请分配的seg mem,被标记为used(rte_fbarray带有查找空闲、标记used的功能)。
-
对于每个seg mem,创建并打开一个文件:<huge-mount_dir>/<hugefile-prefix>map_<index>。同时设置一个共享lock(read lock)。
-
<huge-mount_dir>是可以通过配置参数指定;
-
<hugefile-prefix>也是可以通过配置参数指定,默认是"rte";
-
<index>计算方法为seg-list-index * RTE_MAX_MEMSEG_PER_LIST + mem-seg-index
-
-
创建好的文件描述符,写入fd_list[list_idx].fds[seg_idx]。
-
文件大小设置为seg mem对应的大页的大小
-
mmap大页文件,va地址根据之前seg list匿名映射的地址+seg mem的偏移算出来。mmap的flag为MAP_SHARED | MAP_POPULATE | MAP_FIXED。意思为:和其他进程共享、预先分配物理页、指定map的地址。
-
获取iova的地址。如果当前是VA模式,直接返回va地址,如果是PA模式,则获取PA(具体实现是读取进程的页表文件/proc/<p-id>/pagemap,获取va对应的pa地址)。
-
对mem seg实体赋值(前面rte_eal_memseg_init只是申请了空间)。设置flag为RTE_MEMSEG_FLAG_DO_NOT_FREE,即不需要释放。
-
注:为了mmap的大页内存是从指定的socket上分配的,在分配seg mem,mmap seg mem fd之前,要设置内存分配的偏好(numa_set_preferred(socket_id)),并在申请完之后,恢复之前的偏好设置。
-
注:为了避免mmap出现SIGBUS异常,导致进程非正常退出。还通过sigaction,捕获异常情况(具体参见alloc_seg函数的实现)。
-
rte_eal_malloc_heap_init
根据当前实际使用的cpu,来确定当前使用了哪些socket节点。并根据实际使用的socket的个数,来初始化指定个数的malloc_heaps。每个socket有一个对应的heap。

注: 这里还调用register_mp_requests()注册了多进程之前的消息处理函数。(为什么在这里注册? 只有heap模块会用到这些消息?dpdk多进程,有待进一步分析)
rte_eal_malloc_heap_populate
rte_eal_malloc_heap_populate->malloc_add_seg->malloc_heap_add_memory
遍历seg list,将每个used的seg mem(即前面rte_eal_hugepage_init分配了对应的大页的seg mem)加入到对应的heap中去。heap使用struct malloc_elem管理内存块。需要根据seg list所属的socket,找到对应的heap。
如果多个seg mem是地址连续的,会放到一个struct malloc_elem中去,malloc_elem会有一个指针指向第一个seg mem。
一个heap下,会按照地址,从小到大,将malloc_elem串起来。
每个seg mem对应的内存块,其前一部分是struct malloc_elem数据结构,作为该内存块在heap中的管理header。debug编译选项下,会存在tailer cookie。(下图借用了他人的图片)

malloc_elem会按照当前自己的大小(可能是多个连续的seg mem拼接起来的大小),选择一个free_heap[]成员放入。(下图借用了他人的图片)
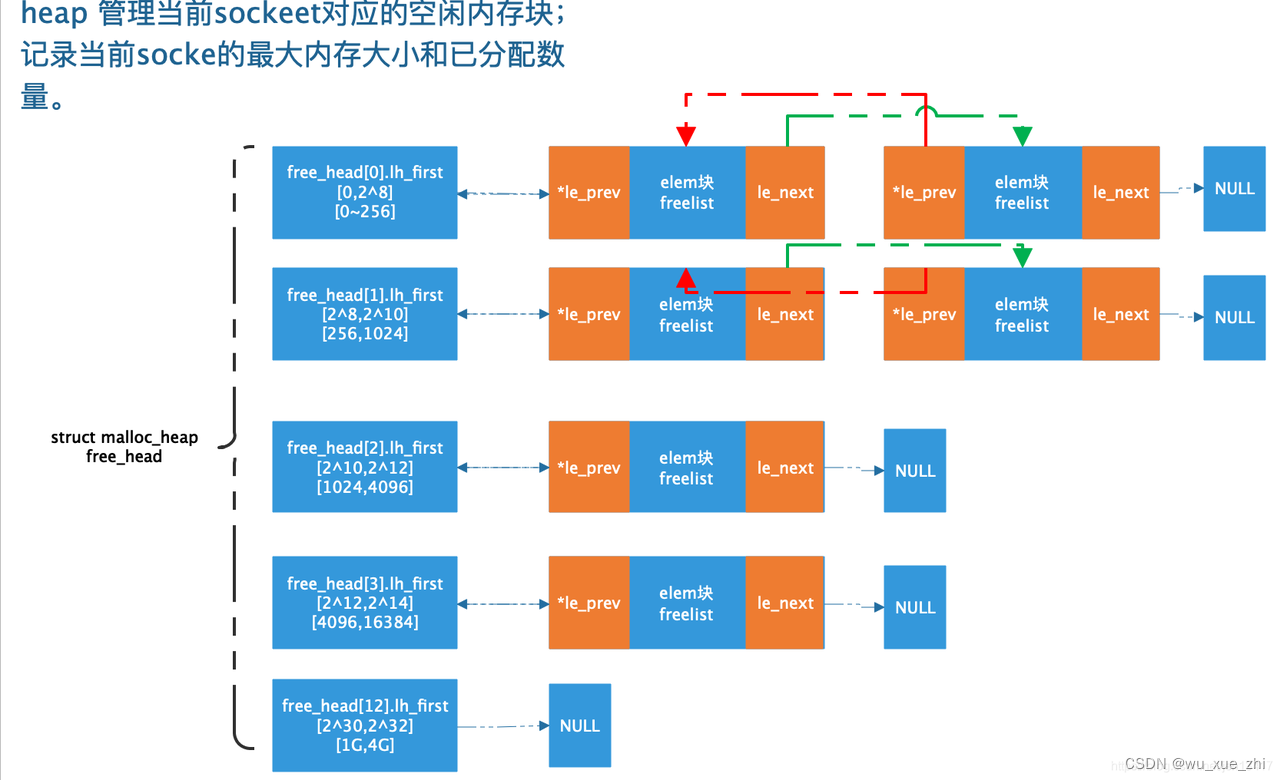
当从一个malloc_elem中分配内存的时候,可能会对malloc_elem切割,切割出来的malloc_elem是直接串起来的:
-
内存从尾部开始分配,考虑到分配内存的对齐要求,有可能尾部还剩余一部分。这一部分如果实际可用部分大于cache line字节(去除header和tail),则会分离出一个新的malloc_elem。
-
对于前面剩下的空间,如果空间也足够大(实际可用部分大于cache line字节),也会分离出一个新的malloc_elem。
-
如果前面有剩下空间,但是空间不够大,则不需要分离出一个新的malloc_elem。但是会初始化一个pad类型的伪header,通过这个header能够找到真的header。(伪header的存在是因为,free mem的时候,默认header就在free的data addr的前面,找到该header,如果为pad类型的header,那么再往前偏移,找到真的header)

-
注:因为malloc_elem切割后,其大小会发生变化,因此可能会加入到新的free_head[]中去。
为申请内存的时候,会切割多个malloc_elem。因此释放malloc_elem时,也要找到前后相邻的malloc_elem,如果是free的话,则尝试重新合并。
申请内存的时候,如果有物理地址连续的要求,则会检查malloc_elem对应的seg list在物理地址上是否连续。并尝试找到符合要求的malloc_elem。(legacy模式,会按照物理地址对seg list下的seg mem进行重排,保证seg mem是物理地址连续的)
VFIO-PCI写iommu页表
对于VA模式,需要将设备访问的dma地址,通过vfio-pci写入iommu页表。默认情况下,DPDK会让所有的设备都使用一个相同的iommu表,并遍历seg mem,将所有的初始化的seg mem对应的va地址,通过vfio接口,写入iommu表。同时也会注册动态分配内存的事件的回调,当dpdk初始化的内存不够用,需要从系统中分配新的内存时,会调用注册的回调函数,该函数会将新的内存地址,写入iommu表。
注:DPDK会将当前进程管理的所有memory,都写入iommu表,即使某个设备只使用自己分配的memory,用于DMA。这样管理比较粗放,但是也有自己的好处,不需要各个驱动程序自己写iommu表,DPDK底层架构统一处理,使用者不感知。(vfio-pci设备直通vm时,qemu也是类似的管理,qemu会把vm的所有内存都注册到iommu表中)。
memzone
memzone是使用fbarray数组管理的,初始化时只申请了数组空间。默认大小为2560个。对外提供的分配接口有如下3个:
const struct rte_memzone *rte_memzone_reserve(const char *name,
size_t len, int socket_id,
unsigned flags);
const struct rte_memzone *rte_memzone_reserve_aligned(const char *name,
size_t len, int socket_id,
unsigned flags, unsigned align);
const struct rte_memzone *rte_memzone_reserve_bounded(const char *name,
size_t len, int socket_id,
unsigned flags, unsigned align, unsigned bound);这个三个函数最终还是调用一个函数,然后该函数在调用heap提供的接口,从heap中申请内存。
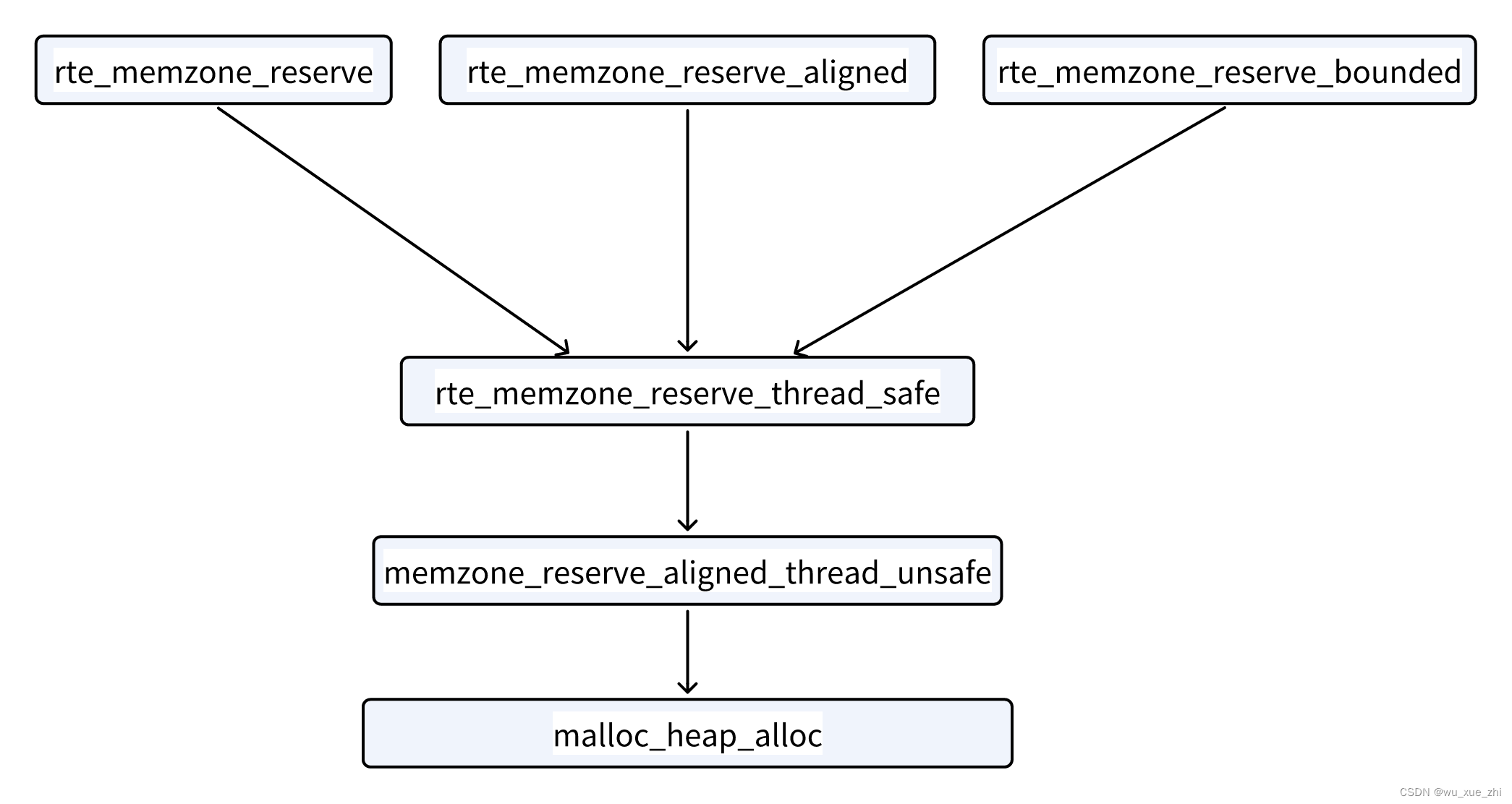
注:align参数为对齐要求,即申请的地址的首地址,必须是align的倍数,最小的对齐单位是一个cacheline(一般为64字节)。bound参数为申请的内存的地址空间不能跨越bound,必须落在一个bound内(这就要求申请的长度len,不能大于bound)。flags参数可以指定在哪些类型的大页上申请,比如指定在2M类型的大页上申请,同时还可以指定申请的内存空间在物理上是要连续的。
一个memzone的解读如下:

申请memzone,一般是用于申请dma空间,和硬件交互,比如申请队列的buff空间,这是因为memzone提供了dma地址的信息(iova),同时申请空间时,还可以指定物理连续,以及对齐要求,以满足某些硬件对于地址对齐的特殊要求。 普通的rte_malloc没法满足物理地址连续的要求,和边界对齐的要求;同时也没办法直接获取到iova(可以自己写代码调用sem mem模块的代码获取,但这不是提供给上层应用的接口)。
rte malloc
rte malloc模块提供了下面几个申请内存的接口,对应C语言的malloc等库函数。
//按照指定对齐方式申请内存,默认会从调用该函数的线程所在的cpu所对应的socket申请内存。
//type参数用于debug,没什么功能性的用处
void *rte_malloc(const char *type, size_t size, unsigned align)
//按照指定对齐方式,从指定的socket节点申请内存
void *rte_malloc_socket(const char *type, size_t size, unsigned align, int socket)
//同rte_malloc和rte_malloc_socket,只是内存会清0
void *rte_zmalloc(const char *type, size_t size, unsigned align)
void *rte_zmalloc_socket(const char *type, size_t size, unsigned align, int socket)
//同rte_zmalloc和rte_zmalloc_socket,内存也会清0,只是size入参拆分了两个
void *rte_calloc(const char *type, size_t num, size_t size, unsigned align)
void *rte_calloc_socket(const char *type, size_t num, size_t size, unsigned align, int socket)
//按照新的大小扩充原有内存,会先尝试分配ptr后面的内存,如果ptr后面空闲内存不够,
//则新申请一块新的内存,socket为当前线程cpu所在的socket,
//并copy原有内存的数据到新的内存,然后释放旧内存
//ptr可以为NULL,此时相当于rte_malloc,直接申请一块新的内存
void *rte_realloc(void *ptr, size_t size, unsigned int align)
//如果socket和原有ptr所在的socket不一样,则在指定的socket上申请一块新内存,
//如果一样,则优先扩充原有内存块,不能扩充则申请新的内存块
void *rte_realloc_socket(void *ptr, size_t size, unsigned int align, int socket)
void rte_free(void *ptr);rte malloc跟memzone一样,会从指定的heap中申请内存,只是memzone把iova等信息管理了起来了。
rte malloc还提供了创建heap,用户自己初始化,申请新的内存放入heap中,然后再自己动态申请和释放,供自己使用的系列API接口。驱动一般不用,应该是给上层的应用程序使用。此时rte malloc、memzone reserv等接口申请的内存,一般是不会从这些heap中申请内存的,用户要从这些heap中申请内存可能要调用更底层的heap接口来申请内存了。
//申请新的heap,heap的socket-id从RTE_MAX_NUMA_NODES开始递增分配,以区别普通的heap。
//此时socket-id不能代表一个有效的numa节点,只能代表一个heap。
//至于heap中的内存来源于哪个socket,有用户控制,用户可能在任意地方申请内存。
int rte_malloc_heap_create(const char *heap_name);
//用户需要自己mmap大页,并往heap中添加大页内存。
//该函数会申请一个新的seg list,并在该seg list下申请新的seg mem。
//如果调用多次的话,往同一个heap中添加多次内存,会创建多个seg list
int rte_malloc_heap_memory_add(const char *heap_name, void *va_addr, size_t len,
rte_iova_t iova_addrs[], unsigned int n_pages, size_t page_sz);
int rte_malloc_heap_memory_remove(const char *heap_name, void *va_addr, size_t len);
int rte_malloc_heap_destroy(const char *heap_name);rte mempool
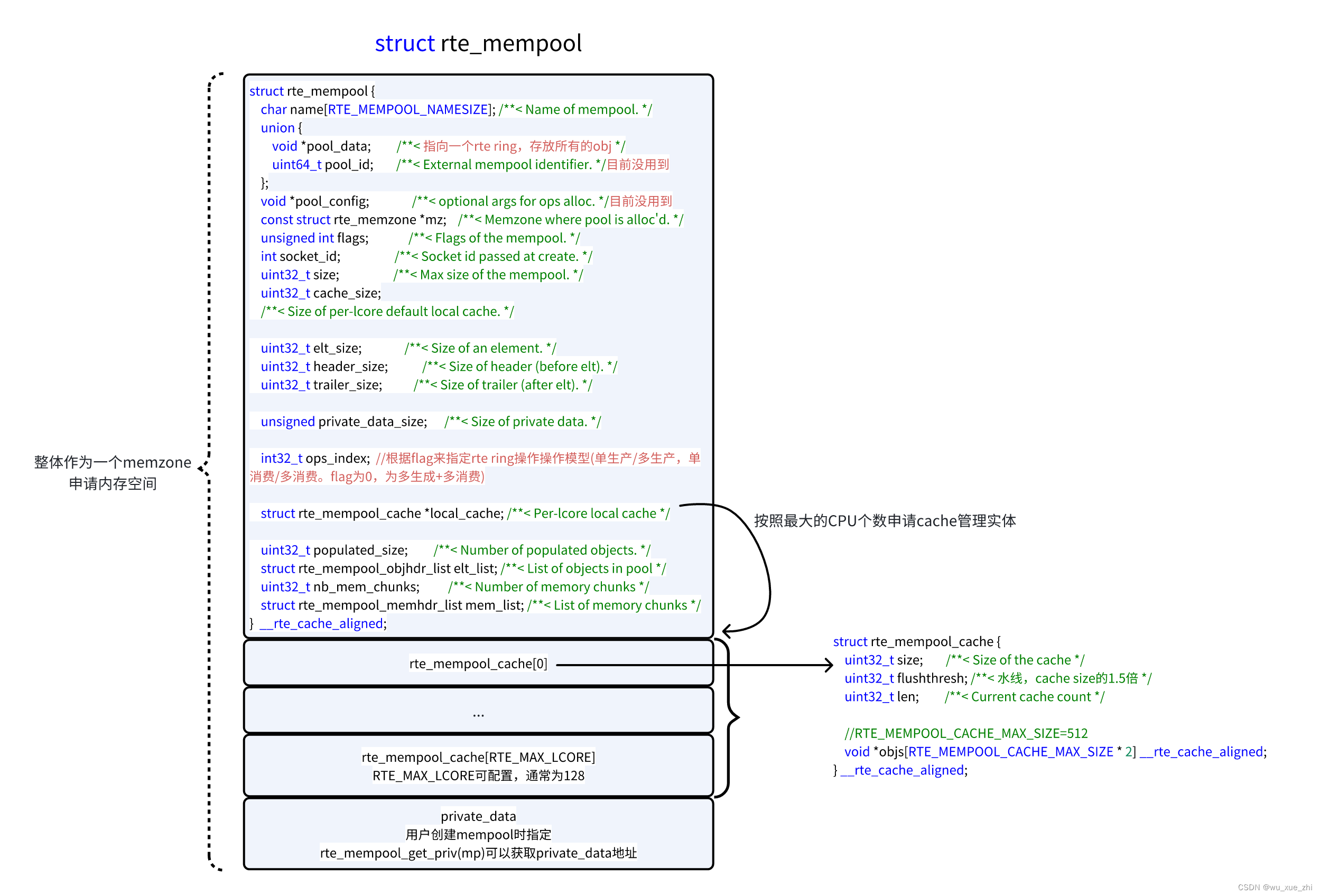
struct rte_mempool *
rte_mempool_create(const char *name, unsigned n, unsigned elt_size,
unsigned cache_size, unsigned private_data_size,
rte_mempool_ctor_t *mp_init, void *mp_init_arg, //用户自定义的初始化mp回调,一般没人用
rte_mempool_obj_cb_t *obj_init, void *obj_init_arg, //成员对象的初始化,很多都会用到
int socket_id, //指定在哪个socket申请内存,包括mempool管理实体
unsigned flags //定义如下
);
//flags定义:
//RTE_MEMPOOL_F_NO_IOVA_CONTIG:默认申请的内存都是IOVA连续的,这里可以指定不需要连续
//RTE_MEMPOOL_F_SP_PUT:默认是多生产这模式,这里可以指定为单生产者
//RTE_MEMPOOL_F_SC_GET:默认是多消费者这模式,这里可以指定为单消费者
//RTE_MEMPOOL_F_NO_SPREAD:默认申请obj内存的时候,会尽量让不同的obj跨不同的内存channel分布,
// 这样可以在并发读写这些obj时,能够提高并行度。
// 为了实现obj跨不同的内存channel分布,会对obj的大小根据dpdk的配置参数
// channel和rank,对obj的内存大小进程调整(可能会增加pad空间),以满足
// obj尽可能的跨channel和rank分布。(具体原理是依据x86的内存地址特性,
// 其中有些固定的bit代表存储的channel,有些bit代表存储的rank)。
// 设置该标记表示不需要离散存储obj,这样做可能会节省一些内存(因为不需要pad)
//RTE_MEMPOOL_F_NO_CACHE_ALIGN:默认cache line对齐,这里可以指定不需要对齐,只针对成员对象。
// 如果不要求对齐的话,那么obj内存申请不会尽量跨不同的内存channel分布。
// 此时会默认设置RTE_MEMPOOL_F_NO_SPREAD。因为要让obj跨不同的内存channel分布的话,
// 可能会有满足一定对齐要求的pad位。mempool数据管理如下:
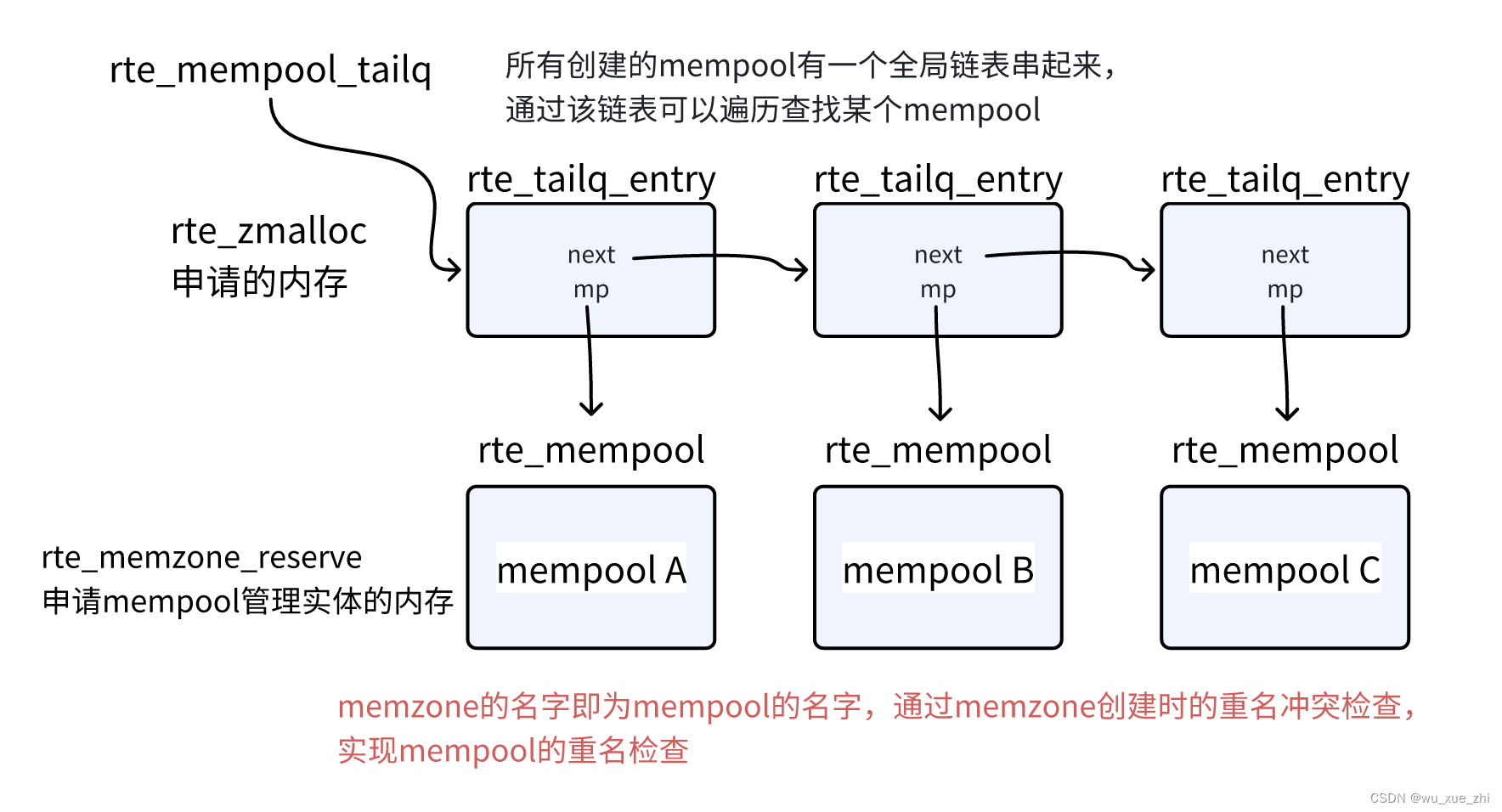
mempool的管理实体:
mempool为obj成员申请的内存,是优先申请能够放的下所有成员大块内存(memzone),然后自己再切割成一个一个的obj成员。如果申请不了足够大的整块内存,则内存大小减半申请,如果还是申请不到,再减半申请,直到能够申请到为止。因此mempool可能申请多个memzone来存放obj成员。一些关键算法如下:
-
计算需要多少内存可以存放所有的obj成员。
-
如果没有物理地址连续的要求(申请时打上RTE_MEMPOOL_F_NO_IOVA_CONTIG标记),那么申请的内存大小按照obj_num*obj_size算出(这里不考虑mem_chunk_reserve的情况,通用的mempool接口mem_chunk_reserve为0)。如果要求物理地址连续,那么需要保证obj存储时不要跨页。
-
为了保证obj存储时不要跨页,因此不能简单的按照obj_num*obj_size来算出。需要先算出一个页能够存放几个完整的obj成员,页剩下的部分不用;然后计算总共需要多个页来存储。这些页的个数加起来作为总的需要申请的内存。(不同的页大小,会导致算出来的总内存大小不同)
-
因为系统里面同时存在多个大页类型,而使用memzone时,为了尽可能申请成功,这里不会强制指定某个大页(mempool会优先在1G的大页中申请,但不强制)。因此按照上一步中,选择什么样的页大小计算需要的内存总量是一个问题。mempool目前使用当前系统的最小的大页大小来计算,这样能保证申请的内存足够大,当然,如果在较大的大页中申请内存的话,可能不一定需要这么多内存。
-

mem chunk,记录了实际memppol obj实际分布在哪些连续的iova地址连续的内存块。每个mem chunk有iova地址,虚拟地址,以及内存长度信息。这样做是为了有些特殊设备,不使用vfio,自己实现了类似iommu的功能,此时可以自己遍历mem chunk,写自己的硬件页表。
sfc驱动(Solarflare Communications公司,2019被Xilinx收购)就是这么做的,该驱动遍历了所有的mempool,并对每个mempool,遍历所有的mem chunk,并写自己的dma页表。
注:还有一种更底层的,范围更大的dam页表的实现方式是,在初始化时,直接遍历所有的mem seg,获取VA和PA(IOVA)的信息,然后写自己的页表;同时注册内存事件的回调(rte_mem_event_callback_register),在后续动态扩容大页内存时,感知扩容的内存信息,写自己的页表。这种实现方式类似dpdk vfio的实现。

mempool的cache特性。每个cpu核有一个自己的cache的obj数据,初始化时不会填充obj对象。
-
上层应用在第一次申请时obj对象时,发现cache为空,可能会从rte ring(存储公共obj资源)中获取obj对象,一部分给用户,一部分填满cache。
-
后续再申请obj时,优先从cache中获取。如果不够的话,会从rte ring中获取。(但是如果rte ring中也没有,则申请不到,此时不会从其他cpu的cache中取obj。因此在创建mempool时,为了保证obj的个数足够使用,要考虑到各个cpu的cache中会有额外的消耗,要多申请一些obj资源)
-
在释放obj时,优先释放到cache中。如果一次释放的很多,超过水线 (1.5倍的设置的cache size),则直接释放到rte ring中。
rte pktmbuf pool
struct rte_mempool *
rte_pktmbuf_pool_create(const char *name, unsigned n,
unsigned cache_size, uint16_t priv_size, uint16_t data_room_size,
int socket_id);
//priv_size,不是指mempool的priv_size,而是指mbuf中的priv_size。
//mempool中的priv_data存放了mbuf的一些信息,是一个固定的结构体大小。pktmbuf pool在mempool之上,封装了mbuf的一些特性。返回的mempool结构体,pktmbuf pool没有单独的管理实体,其管理信息是存储在mempool管理实体中的private data中。

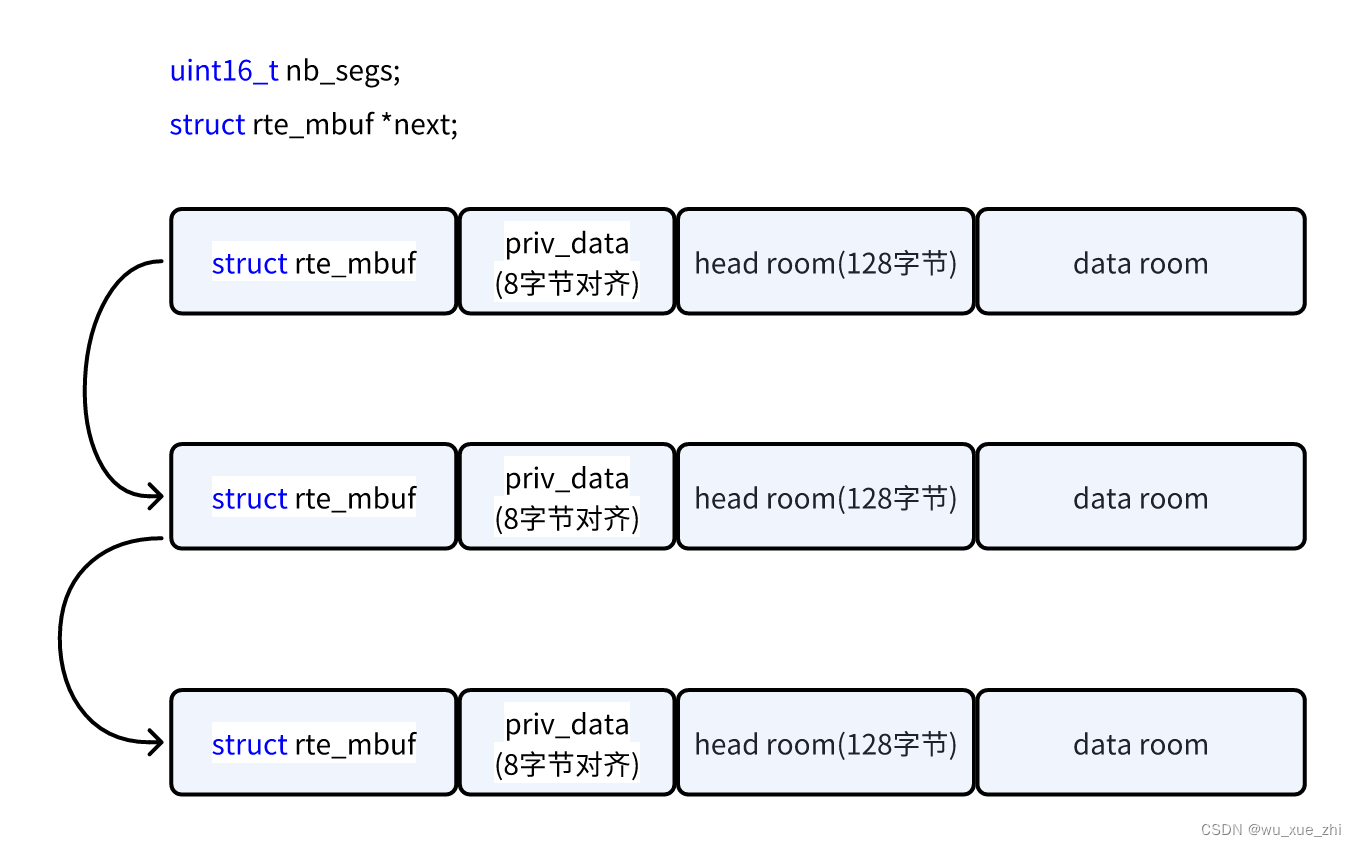
mbuf数据结构如下,一个mempool obj被切分成mbuf的不同部分

多个mbuf可以串起来,作为一个大包。
heap动态扩容
如果没有配置--legacy-mem参数,那么dpdk支持动态扩容内存。也就是说,不受-m或--socket-mem参数限定的内存大小,但是要受限于--socket-limit参数的配置。
heap的动态扩容对上层调用者是不感知的。不管是mempool、memzone、还是rte malloc,都是在heap中申请内存,如果对应的heap中,空闲内存不够,则会根据当前申请内存的缺口,尝试去扩容heap。
因为heap的底层要依赖seg list,因此此时会在seg list中申请一块连续的空闲seg mem(seg mem的个数是在初始化时,按照最大的系统内存配置申请的,因此一般是足够用的),然后创建大页文件,map地址。(map的虚拟地址,是按照seg list的base_va计算的。seg list在初始化时,会按照所有的seg mem个数,来匿名map一大块内存,即预先占用这么大的虚拟内存空间)。这些新申请的seg mem,不会标注为RTE_MEMSEG_FLAG_DO_NOT_FREE,即这些seg mem是可以释放的。(每次在free malloc_elem给heap的时候,会尝试free那些没有RTE_MEMSEG_FLAG_DO_NOT_FREE标记的seg mem,删除大页文件,并将大页返回给OS系统)
对于external socket,即开放给第三方来自己管理的heap。在申请内存时,目前是不支持动态扩容的。
QA
多dpdk应用程序大页冲突问题
dpdk应用程序,最好指定大页文件的mount目录(参数为:--huge-dir <path to hugetlbfs directory>),和大页文件前缀--file-prefix,防止和其他dpdk应用程序的大页目录冲突。
指定大页目录之前需要先mount这个目录:
mkdir <path>
mount -t hugetlbfs none <path> -o pagesize=2048K
DPDK在使用PA模式时,必须要使用大页
因为map的大页内存的虚拟地址跟其物理地址的映射关系不会变(天然会pin住)。目前没有用户态的api接口可以pin住内存,只能借助vfio-pci的map接口可以pin住,但vfio-pci的map接口是为了在VA模式下,写iommu页表使用的。
动态内存申请模式
指定--legacy-mem,传统内存模式,在内存不够用时,不支持动态申请内存。不指定该参数,则默认为动态内存模式。
DPDK 17.11及早期版本,一般应用程序启动会通过-m或--socket-mem参数指定应用程序使用的内存大小,之后DPDK应用程序就会reserve相应大小的内存,然后整个程序运行期间调用rte_malloc()或rte_memzone_reserve()等内存分配结构都是从这个reserve内存池中进行分配的,超过reserve内存的大小将无法分配。
但在动态内存模式下,应用程序可以不再需要通过-m或--socket-mem来预留内存,应用程序启动是完全可以不占用什么内存,当调用rte_malloc()或rte_memzone_reserve()等接口时动态的从系统中分配内存,并注册到DPDK的内存管理中,同样在调用释放内存接口时也会动态的将内存进行释放(从DPDK内存管理中删除)。这样应用程序可以不需要事先估算需要的内存大小,而采用按需分配,更加灵活(不过对于使用hugepage时,系统还是需要预留足够的hugepage)。
不过在动态内存模式情况下-m或--socket-mem参数仍然可以使用,但是其语义和lagecy模式有所不同,动态模式下-m或--socket-mem参数指定的是应用程序预留的最小内存。这部分内存应用程序不会释放,当需要申请更多的内存时应用程序可以超出这部分预留内存动态添加,为了可以限制应用程序所能使用的最大内存,动态内存提供了--socket-limit参数来指定当前socket所能使用的内存大小上限。















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









