






StoryDiffusion 是由南开大学和字节跳动团队联合研发的,基于一致性自注意力机制生成长跨度图像和视频的新型扩散模型(Consistent Self-Attention for Long-Range Image and Video Generation),使用者不需要进行额外训练,就可以生成风格一致的图像序列。
·利用Consistent Self-Attention机制来生成主题一致的连续内容,生成类似于漫画书、连环画等场景的画面
·StoryDiffusion能搭配PhotoMaker使用,生成与参考图一致的内容
项目地址:https://github.com/HVision-NKU/StoryDiffusion
机器选择
根据 StoryDiffusion 的项目描述,其提供的低显存需求的版本是在 Tesla A10 上测试的,即显存要求在 24G,根据项目方预测显存尽量选择在大于 20G,所以在矩池云上使用 StoryDiffusion 时我们可以选择 3090、4090、A6000、A30 和 A100,在这里我们所使用的为 4090。
模型下载
开始前,我们需要提前下载上传以下模型(或者按后文步骤,租用机器后,使用国内源下载使用)
需要提前下载上传以下模型(或者按后文步骤,租用机器后,使用国内源下载使用)
可以使用网盘客户端的导入 HuggingFace 项目功能,这样不需要花钱租用机器下载模型数据。
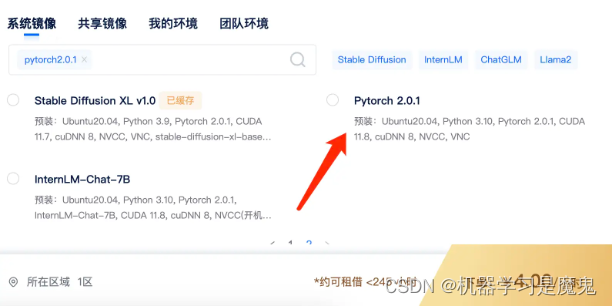
镜像选择
根据项目需求,即,
Python >= 3.8 (Recommend to use Anaconda or Miniconda)
PyTorch >= 2.0.0
我们选择系统镜像 Pytorch 2.0.1 ,
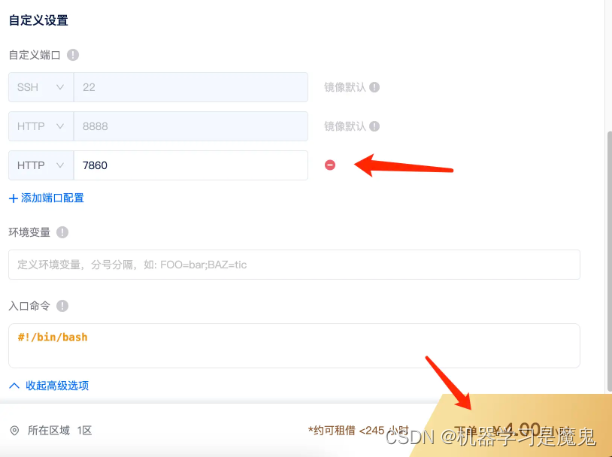
选择镜像后,在下面的高级选项自定义一个7860端口(后面运行 StoryDiffusion web demo 会使用),然后点击下单即可。
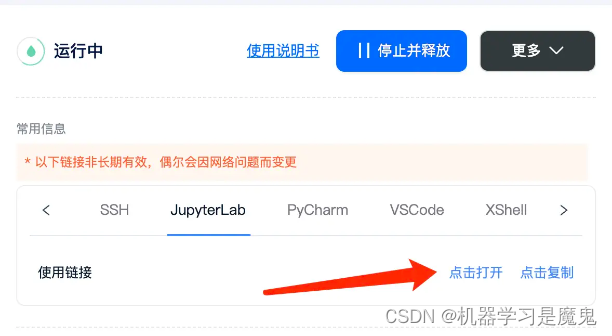
机器启动成功后,点击租用页面的 Jupyterlab --点击打开,
环境安装
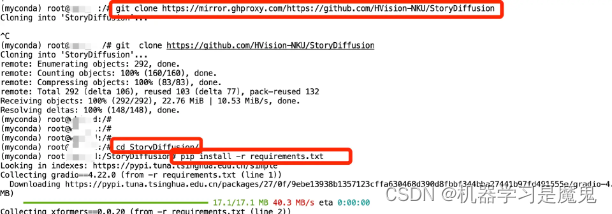
在 Jupyterlab 页面新建一个 Terminal,输入如下指令 clone 项目并安装环境。
cd /mnt
git clone https://mirror.ghproxy.com/https://github.com/HVision-NKU/StoryDiffusion
cd StoryDiffusion
pip install -r requirements.txt
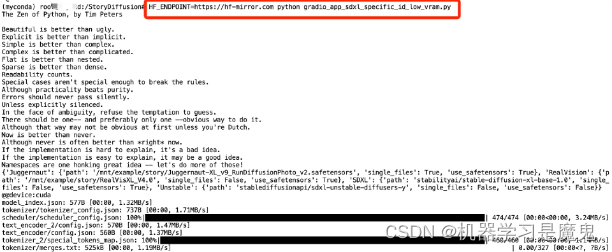
环境安装成功后,可以开始运行项目,输入以下指令即可:
HF_ENDPOINT=https://hf-mirror.com python gradio_app_sdxl_specific_id_low_vram.py
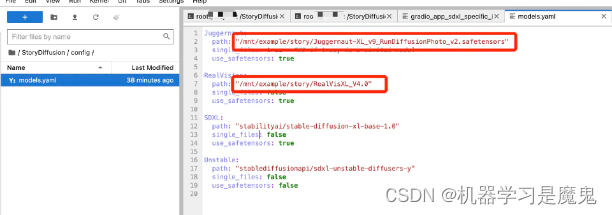
如果你已经下载好模型,并上传到了网盘,可以 Jupyterlab 打开 StoryDiffusion 项目文件夹下的config/models.yaml文件,将里面的模型路径改成你服务器里对应路径。
网盘对应机器中的/mnt目录,比如网盘下 abc 目录下的 123.csv 文件路径就是:/mnt/abc/123.csv
程序运行成功后会显示端口号,这时我们访问租用页面自定义的 7860 端口对应链接即可访问服务。
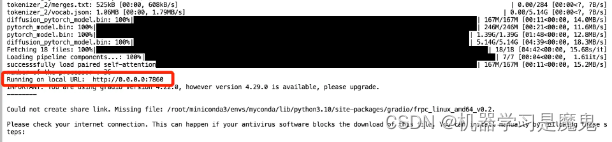
点击即可打开服务页面。
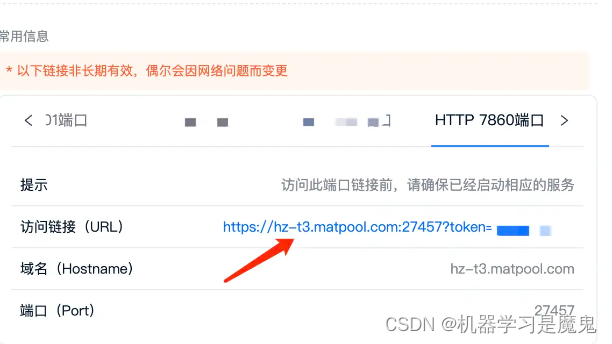
使用StoryDiffusion
在页面中根据提示即可开始使用 StoryDiffusion。
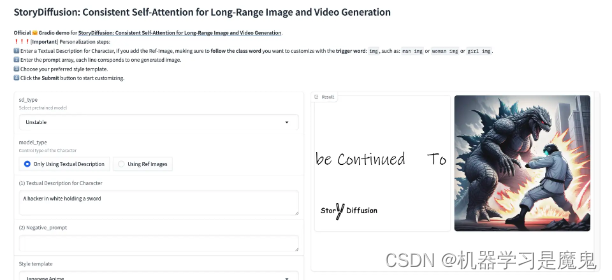
根据官方给的 DEMO 进行分析,我们发现
(1)prompt中,以#开头的内容,会出现在图中成为文字注解的部分
(2)以[NC]开头的内容,指的是没有定义的角色会出现在该图片中
[Bob] at home, read new paper #at home, The newspaper says there is a treasure house in the forest.
[Bob] on the road, near the forest
[Alice] is make a call at home # [Bob] invited [Alice] to join him on an adventure.
[NC]A tiger appeared in the forest, at night
[NC] The car on the road, near the forest #They drives to the forest in search of treasure
[Bob] very frightened, open mouth, in the forest, at night
[Alice] very frightened, open mouth, in the forest, at night
[Bob] and [Alice] running very fast, in the forest, at night
[NC] A house in the forest, at night #Suddenly, They discovers the treasure house!
[Bob] and [Alice] in the house filled with treasure, laughing, at night #He is overjoyed inside the house.
我们也可以输入自己的prompt,进而生成图片。


















 2759
2759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









