







654.最大二叉树
题目链接/文章讲解:代码随想录
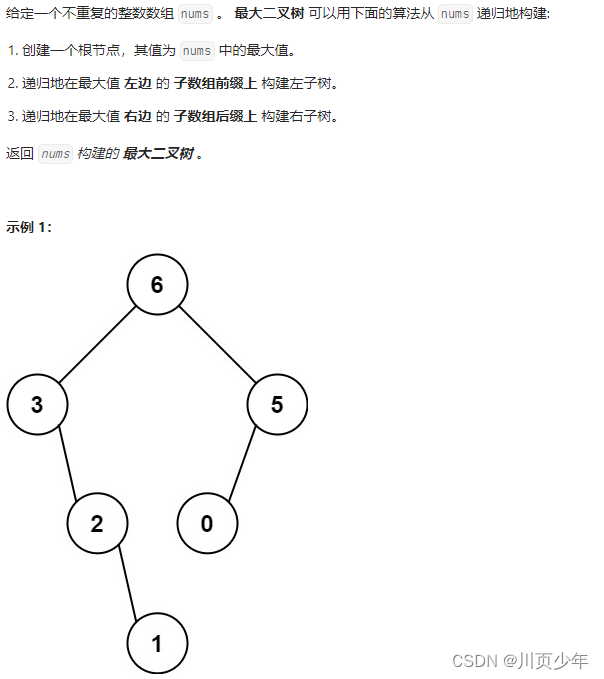
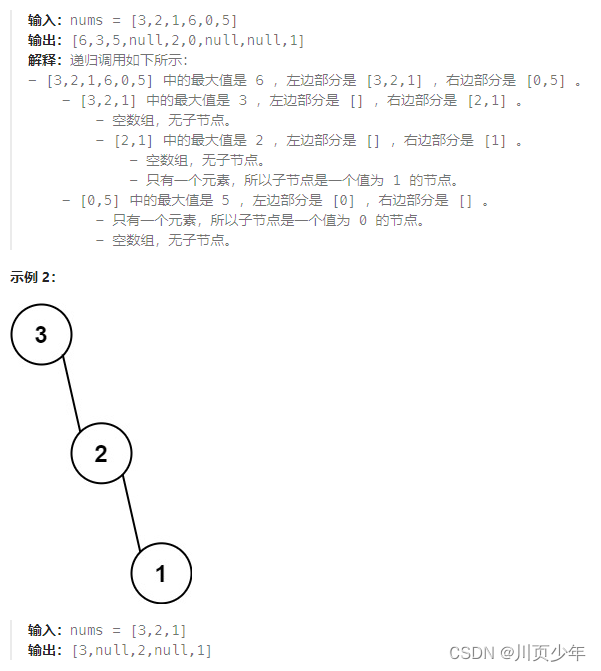

1.分析及思路
与路径总和 从中序与后序遍历序列构造二叉树非常类似,只是处理的时候有点区别,单层递归逻辑一样,只不过一个是用根节点划分,一个是用最大的数划分。凡是构造二叉树之类的题目,都是使用中序遍历进行的,只有有了根节点,才能向外延申,也符合逻辑。
递归三部曲:
1.函数的功能、函数的传入参数、函数的返回值
函数的功能:生成一个结点,并且给它赋值左右孩子
函数的传入参数:题目是根据数组划分的,所以要有一个数组,即int*型。还要有一个数组大小的int型用来标记数组边界。
函数的返回值:找左右孩子时,结点本身是找不到的,只能向下一层递归寻找,所以返回值是struct TreeNode*
2.终止条件
因为数组最小为1,所以当数组大小为1时,终止循环。也可以不加这句,因为数组为1时不会进入递归,到函数最后也是会退出循环。
3.单层递归逻辑
拿到一个数,就为它分配空间,并且寻找其左右孩子。
寻找左右孩子就是递归的调用函数
2.代码及分析
代码中的区间是左闭右开
//获取最大值的下标
int GetMaxIndex(int* nums,int numsSize){
int max = nums[0];//初始化最大值为首元素
int maxIndex = 0;//下标为0
for(int i=0;i<numsSize;i++){
if(nums[i] > max){//如果当前值大于最大值
max = nums[i];//更新最大值
maxIndex = i;//并且记录下标
}
}
return maxIndex;//返回最大值的下标
}
struct TreeNode* constructMaximumBinaryTree(int* nums, int numsSize) {
int maxIndex = GetMaxIndex(nums,numsSize);//获取数组中最大的值的下标
struct TreeNode* Node = (struct TreeNode*)malloc(sizeof(struct TreeNode));
Node->left = NULL;
Node->right = NULL;
Node->val = nums[maxIndex];//初始化结点,并写入最大值
if(numsSize == 1) return Node;//若数组中只有一个元素,则不用再次划分,直接返回它即可。不加它也可以,就是多执行了几步
if(maxIndex != 0)//若最大值的下标不是左边界,则递归的向左寻找其左孩子
Node->left = constructMaximumBinaryTree(nums,maxIndex);
if(maxIndex != numsSize-1)//若最大值的下标不是右边界,则向右寻找其右孩子
Node->right = constructMaximumBinaryTree(&nums[maxIndex+1],numsSize-1-maxIndex);
return Node;
}卡哥思路
思路大致一样,只是递归出口不一样。由于递归时就要产生新结点,所以在一开始就申请空间,然进行递归出口的判断,最后在进行左右孩子寻找的递归。
1.函数的功能、函数的传入参数、函数的返回值
函数的功能:生成一个结点,并且给它赋值左右孩子
函数的传入参数:题目是根据数组划分的,所以要有一个数组,即int*型。还要有一个数组大小的int型用来标记数组边界。
函数的返回值:找左右孩子时,结点本身是找不到的,只能向下一层递归寻找,所以返回值是struct TreeNode*
2.终止条件
由于题目不会给一个空数组,所以在递归时,遇到只剩下一个元素时结束掉。就算它递归进去也不会有任何数值产生,因为它会成为叶子结点,不会传入左右数组。
3.单层递归逻辑
拿到一个数,就为它分配空间,并且寻找其左右孩子。
寻找左右孩子就是递归的调用函数
//获取最大值的下标
int GetMaxIndex(int* nums,int numsSize){
int max = nums[0];//初始化最大值为首元素
int maxIndex = 0;//下标为0
for(int i=0;i<numsSize;i++){
if(nums[i] > max){//如果当前值大于最大值
max = nums[i];//更新最大值
maxIndex = i;//并且记录下标
}
}
return maxIndex;//返回最大值的下标
}
struct TreeNode* constructMaximumBinaryTree(int* nums, int numsSize) {
//每次递归都说明有一个新结点的产生
struct TreeNode* Node = (struct TreeNode*)malloc(sizeof(struct TreeNode));
//初始化该结点
Node->left = NULL;
Node->right = NULL;
if(numsSize == 1){//若数组中只剩下一个元素,则说明遍历结束
Node->val = nums[0];//把元素赋值给结点
return Node;
}
int maxIndex = GetMaxIndex(nums,numsSize);//获取数组中最大的值的下标
Node->val = nums[maxIndex];//不是最后一个元素,则保存数组中最大的值,作为结点的值
if(maxIndex != 0){//不是左边界,则向左寻找左孩子
Node->left = constructMaximumBinaryTree(nums,maxIndex);
}
if(maxIndex != (numsSize-1))//若最大值的下标不是右边界,则向右寻找其右孩子
Node->right = constructMaximumBinaryTree(nums+maxIndex+1,numsSize-1-maxIndex);
return Node;
}617.合并二叉树
题目链接/文章讲解: 代码随想录
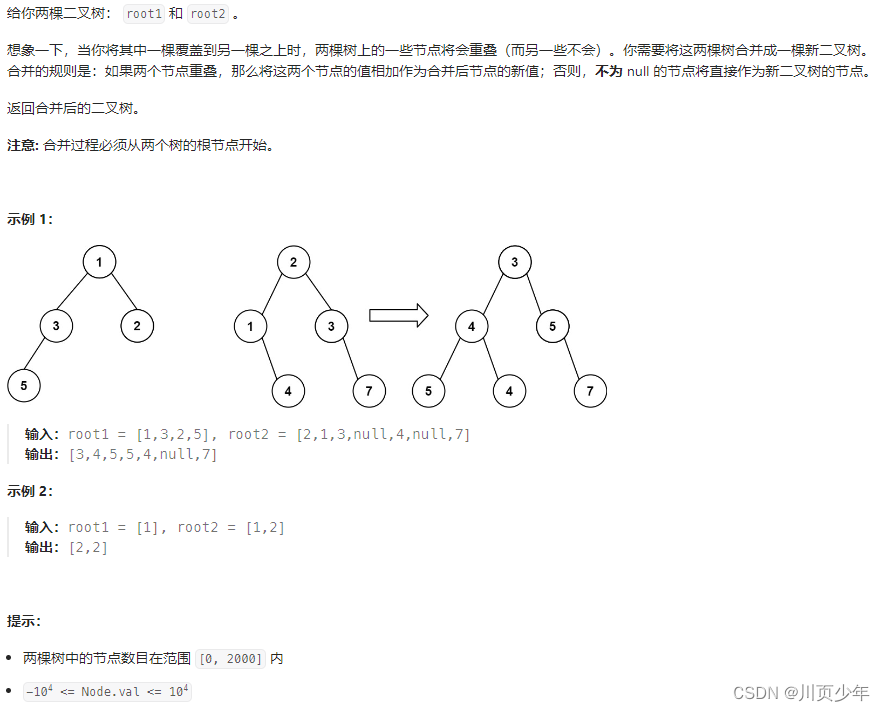
1.分析及思路
同步遍历两个二叉树,把对应的元素相加即可。前序遍历符合一般的思路,先多中结点进行合并,然后再进行左右结点的合并。因为要遍历树所以可以采用递归,这里使用前序遍历的递归。
递归三部曲:
1.函数的功能、函数的传入参数、函数的返回值
函数的功能:合并两个树,返回其根节点
函数的传入参数:合并两个树,很明显,传入两个根节点
函数的返回值:最终会返回结点
2.终止条件
假设遇到非空结点,处理顺序是,合并其值,然后修改其左右孩子的值。所以它不能作为终止条件。当遇到非空时,没有办法进行合并值。所以作为终止条件。有三种情况
root1 == NULL和root2 == NULL
root1 != NULL 和root2 == NULL
root1 == NULL和root2 != NULL
三种情况
3.单层递归的逻辑
拿到一个非空的结点,要做的是就是,中结点合并,然后寻找其左孩子的值,右孩子的值。
即左孩子的值,右孩子的值就是调用该函数。
2.代码及注释
struct TreeNode* mergeTrees(struct TreeNode* root1, struct TreeNode* root2) {
if(root1 == NULL && root2 != NULL) return root2;//当root1为空时,返回root2
if(root1 != NULL && root2 == NULL) return root1;//当root2为空时,返回root1
if(root1 == NULL && root2 == NULL) return NULL;//都为空时,返回空
struct TreeNode* Node = (struct TreeNode*)malloc(sizeof(struct TreeNode));
Node->val = root1->val + root2->val;//中。中结点合并
Node->left = mergeTrees(root1->left,root2->left);//左。寻找左孩子的值
Node->right = mergeTrees(root1->right,root2->right);//右。寻找右孩子的值
return Node;//返回该结点
}卡哥思路
大体思路一样只是,递归的出口简化了。用的root1作为返回的结果。
struct TreeNode* mergeTrees(struct TreeNode* root1, struct TreeNode* root2) {
if(root1 == NULL) return root2;//当root1为空时,如果root为空,则还是返回空,空也是root2
if(root2 == NULL) return root1;//所以它两个谁为空返回另一个即可
root1->val = root1->val + root2->val;//中。中结点合并
root1->left = mergeTrees(root1->left,root2->left);//左。寻找左孩子的值
root1->right = mergeTrees(root1->right,root2->right);//右。寻找右孩子的值
return root1;//返回该结点
}700.二叉搜索树中的搜索
题目链接/文章讲解: 代码随想录
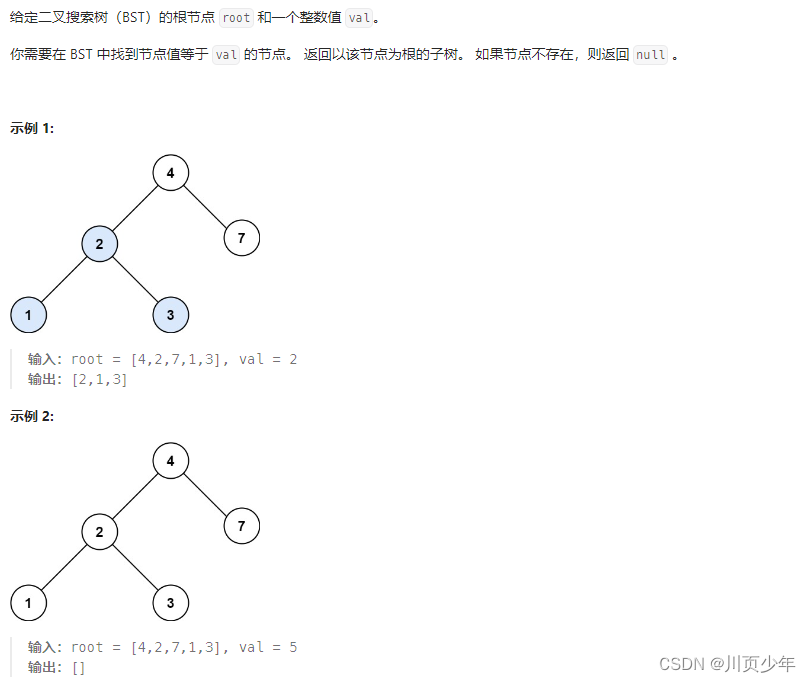

1.当成普通的树
1.1分析及思路
当成普通的二叉树时,只需在遍历整个树时,加上判断值即可。
递归三部曲:
1.函数的功能、函数的传入参数、函数的返回值
函数的功能:查找树中是否有该值
传入参数:一个结点、一个要查找的数值
返回值:要返回一个结点,因为下边的结点要上返回找没找到
2.终止条件
当传入空结点时,无法查找所以结束。
3.单层递归逻辑
拿到一个结点,先判断和目标值相等吗,相等就返回,不相等就向左右子树寻找。
1.2代码及注释
struct TreeNode* searchBST(struct TreeNode* root, int val) {
if(root == NULL) return NULL;//空结点结束
if(root->val == val)//判断是否等于目标值
return root;
struct TreeNode* Node = searchBST(root->left,val);//向左子树寻找
if(Node != NULL)//左子树没找到
return Node;
return searchBST(root->right,val);//向
}2.二叉搜索树的特性
2.1分析及思路
二叉搜索树中,所有的结点都是左孩子小于中结点小于右孩子,根据这个特性就可以直到目标值的路线,该路线没有找到就说明其不存在。
递归三部曲:
1.函数的功能、返回值、参数
函数的功能:在搜索二叉树中寻找目标值
参数:目标值和二叉树
返回值:目标值的结点
2.终止条件
当结点为空时,说明查找结束。因为不为空时,就会继续进行目标值的判断
3.单层循环逻辑
若等于目标值,则直接返回结果。若小于目标值,则转向右孩子,大于目标值,则转向左孩子。
2.2代码及注释
struct TreeNode* searchBST(struct TreeNode* root, int val) {
//root为空时,是中断条件。等于目标值是单层递归逻辑
if( (root == NULL) || (root->val == val) ) return root;
struct TreeNode* Node = NULL;
if(root->val > val) Node = searchBST(root->left,val);//暂存左子树的寻找结果
if(root->val < val) Node = searchBST(root->right,val);//暂存右子树的寻找结果
return Node;
}3.迭代法二叉搜索树
3.1分析及思路
对树进行遍历时,很明显是当结点为空时,退出循环。在寻找过程中若找的则退出循环。
按照搜索二叉树的特性进行搜索。
3.2代码及注释
struct TreeNode* searchBST(struct TreeNode* root, int val) {
while(root != NULL){//非空就说明,还没找完
if(root->val == val) break;//碰到目标值直接结束循环
else if(root->val < val) root = root->right;//小于目标值转向左子树
else root = root->left;//大于目标值转向右子树
}
return root;
}98.验证二叉搜索树
题目链接/文章讲解: 代码随想录
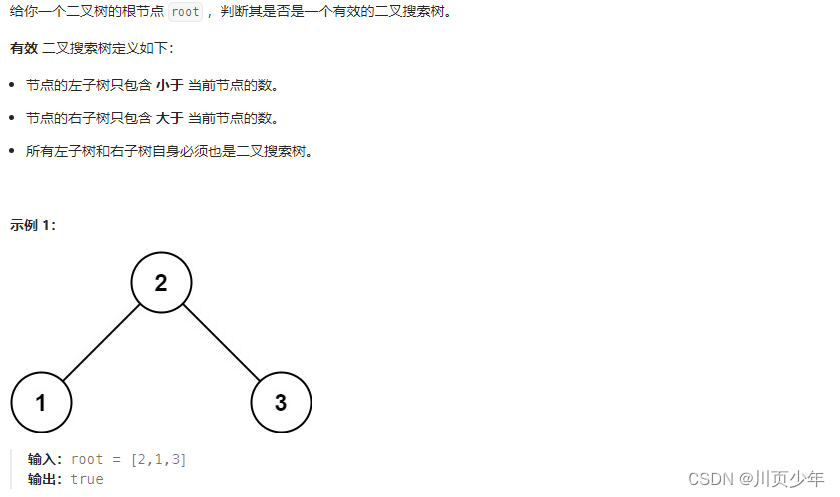
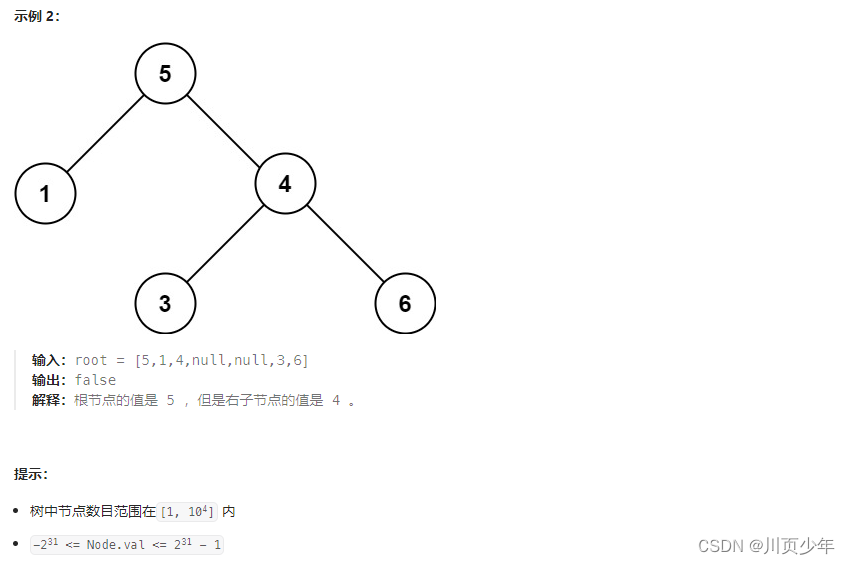
1.分析及思路
二叉搜索树,根节点大于左子树,小于右子树。每一个结点都符合这个逻辑。所以使用中序遍历时,会得到一个升序的数组。只需在进行中序遍历时,保证前一个结点小于后一个结点即可。
递归三部曲:
1.功能、参数、返回值
功能:判断该树是不是二叉搜索树,即判断你左子树是否全小于根节点,根节点是否全小于右子树。
参数:由于leetcode中全局变量,会影响不同的测试案例,所以不使用全局变量,用struct TreeNode** pre来保存每次遍历该结点的前一个结点。root用来传入二叉排序树的根节点
返回值:由于结点需要快速返回其判断的结果给上一层,且有一个不符合即整个树不符合。所以需要快速返回结果。用bool
2.终止条件
假设遇到一个非空结点,我们要做的就是判断其左子树符合条件吗,判断其左右孩子及根节点符合条件吗,判断其右子树符合条件吗,所以当结点为非空无法进行判断,所以当结点为空时,结束递归。
3.单层递归逻辑
当遇到一个结点时,判断其左子树符合条件吗,即递归调用函数,根节点时判断,上一次的值是否小于它(因为中序遍历一定是一个递增的),判断右子树符合条件吗。
2.代码及注释
//pre用来保存前驱
bool traversal(struct TreeNode** pre,struct TreeNode* root){
if(root == NULL) return true;//递归出口
if(!traversal(pre,root->left)) return false;//左子树不符合条件是直接返回空
if(*pre != NULL && (*pre)->val >= root->val) return false;//根节点与前一个结点进行比较
*pre = root;//更新结点
if(!traversal(pre,root->right)) return false;//判断右子树是否符合条件
return true;
}
bool isValidBST(struct TreeNode* root) {
struct TreeNode* pre = NULL;//运行开始时,没有前驱
return traversal(&pre,root);
}
3.其它讲解
注意的是,每一个结点都符合,左子树<根节点<右子树。所以不能进行
(root->val > root->left->val) && (root->val < root->right->val)的判断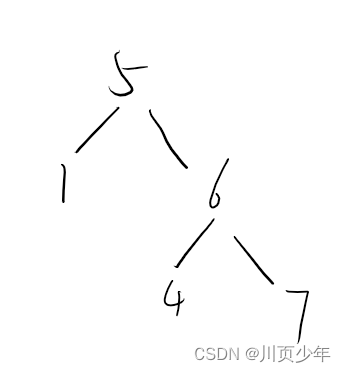 则1<5<6符合,
则1<5<6符合,
4<6<7符合,但是整体来看右子树应该都比5大,所以不符合。
因为leetcode每个测试用例的全局变量相互影响,所以用局部变量进行重置,所以传入了一个新的参数。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









