






00.numpy
#生成array
#list转array
#shape的使用
#坐标选取
#:的使用
import numpy as np
a=np.zeros((2,3)) #2行3列 元素为0
b=np.full((2,3),1) #2行3列 元素为1
list1=[[1,2],[3,4],[5,6]] # list1 为列表
array1=np.array(list1) #列表转为数组
c=array1[0,1] #选取数组array1中0行1列数字
d=array1(:,1) #选取数组array1中所有行1列数字
print(d)
01、线性代数
#求最平均值
import numpy as
a=np.array([[-1,2],[3,-4],[-5,6]])
b=np.mean(a,axis=1) #axis=1为横轴取平均数 =0为竖轴取平均数
print(b)
#求最大值1
c=np.maximum(0,a) #a中小于0的由0代替
d=np.array([[0,1],[2,-5],[-1,1]])
p=np.maximum(d,a) #将d与a比较大的保留
#求最大值2
e=np.max(a)
02、神经网络第一层
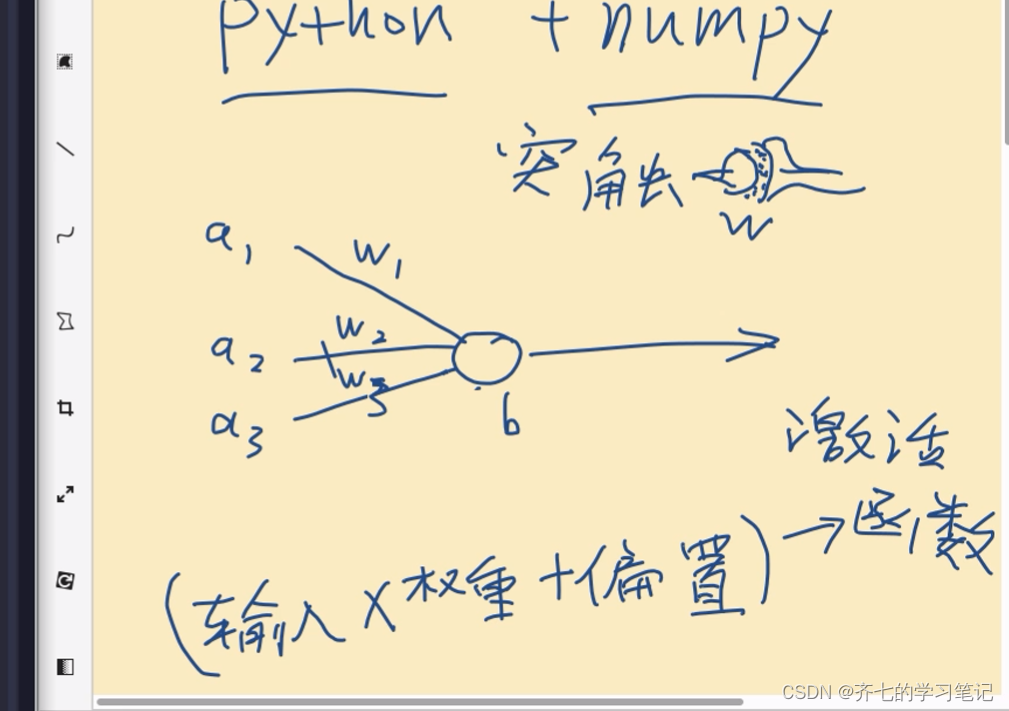
import numpy as np
#输入
a1=-0.9
a2=-0.5
a3=-0.7
inputs=np.array([a1, a2, a3])
#权重
w1=0.8
w2=-0.4
w3=0
weights=np.array([[w1],
[w2],
[w3]])
#偏重
b1=0
# sum1=a1*w1+a2*w2+a3*w3+b1
sum1=np.dot(inputs, weights)+b1
#激活函数
def activation_ReLU(inputs):
return np.maximum(0,inputs)
print(sum1)
print(activation_ReLU(sum1))
00、权重矩阵

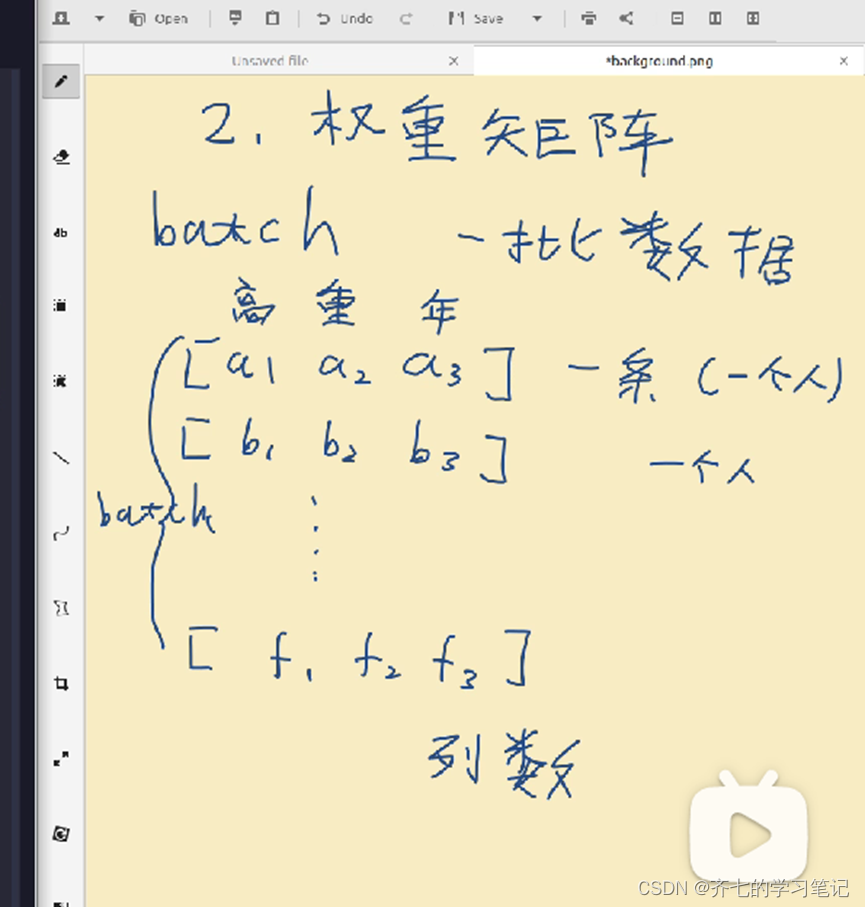
import numpy as np
#生成权重函数
def creat_weights(n_inputs,n_neurons): #neurons 神经元
return np.random.randn(n_inputs,n_neurons) #random 随机生成函数 randn 生成正太分布的函数 n_inputs行 n_neurons 列矩阵
def creat_biases(n_neurons):
return np.random.randn(n_neurons)
#激活函数
def activation_ReLU(inputs):
return np.maximum(0,inputs)
#----------------------------------------------------------------------------
#输入
a11=-0.9
a21=-0.4
a31=-0.7
a12=-0.8
a22=-0.5
a32=-0.6
a13=-0.5
a23=-0.8
a33=-0.2
#batch
inputs=np.array([[a11, a21,a31],
[a12,a22,a23],
[a13,a23,a33]])
#权重
weights=creat_weights(3,2)
print("weights")
print(weights)
#偏重
biases=creat_biases(2)
print("biases")
print(biases)
sum1=np.dot(inputs, weights)+biases
print("sum1")
print(sum1)
print("-----------------------------------")
print("activation_ReLU(sum1)")
print(activation_ReLU(sum1))
03、面向对象的层
00、由层组成网络
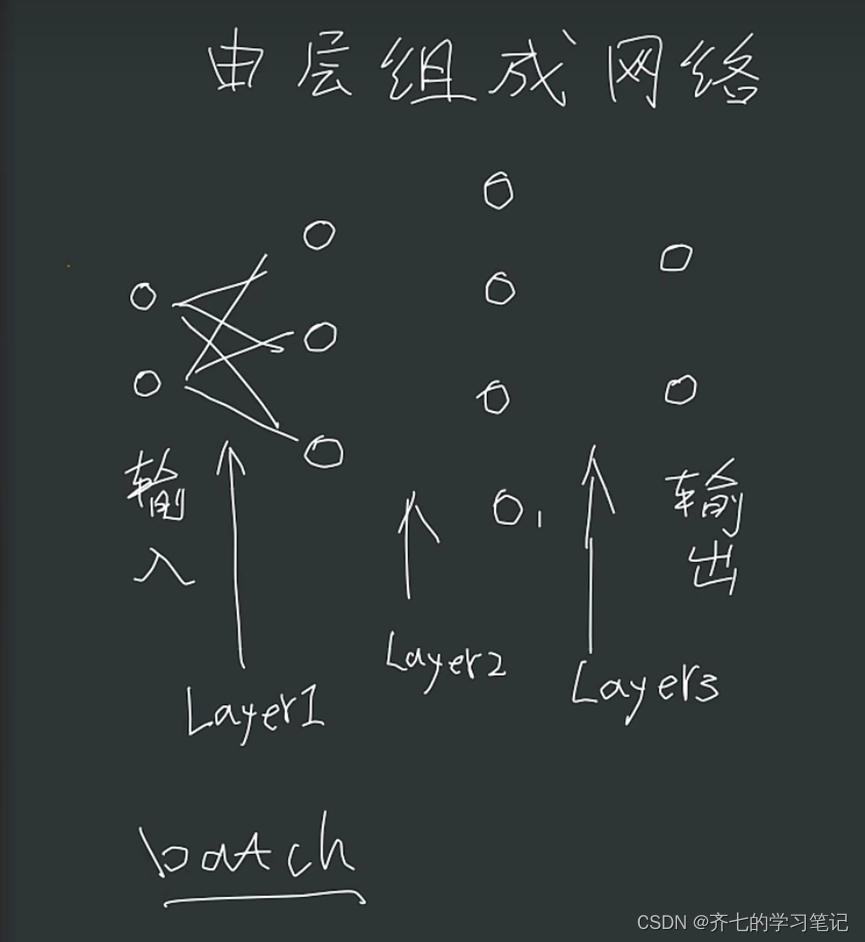
import numpy as np
#生成权重函数
def creat_weights(n_inputs,n_neurons): #neurons 神经元
return np.random.randn(n_inputs,n_neurons) #random 随机生成函数 randn 生成正太分布的函数 n_inputs行 n_neurons 列矩阵
def creat_biases(n_neurons):
return np.random.randn(n_neurons)
#激活函数
def activation_ReLU(inputs):
return np.maximum(0,inputs)
#----------------------------------------------------------------------------
#输入
a11=0.9
a21=-0.4
a12=-0.8
a22=0.5
a13=-0.5
a23=-0.8
a14=0.7
a24=-0.3
a15=-0.9
a25=0.4
#batch
inputs=np.array([[a11, a21],
[a12,a22],
[a13,a23],
[a14,a24],
[a15,a25]])
#第一层
weights1=creat_weights(2,3)
biases1=creat_biases(3)
# 第二层
weights2=creat_weights(3,4)
biases2=creat_biases(4)
#第三层
weights3=creat_weights(4,2)
biases3=creat_biases(2)
#第一层运算
sum1=np.dot(inputs, weights1)+biases1
output1=activation_ReLU(sum1)
print("output1")
print(output1)
print("-----------------------------------")
#第二层运算
sum2=np.dot(output1, weights2)+biases2
output2=activation_ReLU(sum2)
print("output2")
print(output2)
print("-----------------------------------")
#第三层运算
sum3=np.dot(output2, weights3)+biases3
output3=activation_ReLU(sum3)
print("output3")
print(output3)
print("-----------------------------------")
--------------------------------------------------------进化-------------------------------------------------------------------
01、面向对象的层
import numpy as np
#激活函数
def activation_ReLU(inputs):
return np.maximum(0,inputs)
#定义一个层类
class Layer: #定义类,用class
def __init__(self,n_inputs,n_neurons):
self.weights=np.random.randn(n_inputs,n_neurons)
self.biases=np.random.randn(n_neurons)
def layer_forward(self,inputs): #定义向前运算函数——解决层的运算
sum1=np.dot(inputs,self.weights)+ self.biases
self.output=activation_ReLU(sum1)
return self.output
#----------------------------------------------------------------------------
#输入
a11=0.9
a21=-0.4
a12=-0.8
a22=0.5
a13=-0.5
a23=-0.8
a14=0.7
a24=-0.3
a15=-0.9
a25=0.4
#batch
inputs=np.array([[a11, a21],
[a12,a22],
[a13,a23],
[a14,a24],
[a15,a25]])
#第一层
layer1= Layer(2,3)
#第二层
layer2= Layer(3,4)
#第三层
layer3= Layer(4,2)
#第一层运算
output1=layer1.layer_forward(inputs)
print("output1")
print(output1)
print("-----------------------------------")
#第二层运算
output2=layer2.layer_forward(output1)
print("output2")
print(output2)
print("-----------------------------------")
#第三层运算
output3=layer3.layer_forward(output2)
print("output3")
print(output3)
--------------------------------------------------------再进化----------------------------------------------------------------
04、面向对象的网络
import numpy as np
NETWORK_SHAPE=[2,3,4,2] #神经网络形状 第一层2个神经元,第二层3个神经元,第三层4个神经元,第四层2个神经元
#激活函数
def activation_ReLU(inputs):
return np.maximum(0,inputs)
#定义一个层类
class Layer: #定义类,用class
def __init__(self,n_inputs,n_neurons):
self.weights=np.random.randn(n_inputs, n_neurons)
self.biases=np.random.randn(n_neurons)
def layer_forward(self,inputs): #定义向前运算函数——解决层的运算
sum1=np.dot(inputs, self.weights)+self.biases
self.output=activation_ReLU(sum1)
return self.output
#定义一个网络类
class Network:
def __init__(self,network_shape): #定义层
self.shape=network_shape
self.layers=[ ]
for i in range(len(network_shape)-1): #减1是因为有4层神经元,就有4-1层权重矩阵 (w以及b)
layer=Layer(network_shape[i],network_shape[i+1])
self.layers.append(layer) #append表示将layer放入到·layers中
#前馈运算函数
def network_forward(self, inputs): #定义层的运算
outputs=[inputs]
for i in range (len(self.layers)):
layer_output=self.layers[i].layer_forward(outputs[i])
outputs.append(layer_output)
print(outputs)
return outputs
#----------------------------------------------------------------------------
#输入
a11=0.9
a21=-0.4
a12=-0.8
a22=0.5
a13=-0.5
a23=-0.8
a14=0.7
a24=-0.3
a15=-0.9
a25=0.4
#batch
inputs=np.array([[a11, a21],
[a12,a22],
[a13,a23],
[a14,a24],
[a15,a25]])
def main():
network=Network(NETWORK_SHAPE)
network.network_forward(inputs)
#----------TEST-----------
def test ():
pass
#-----------yunxing-------------
main()05、softmax激活函数 + 标准化
import numpy as np
NETWORK_SHAPE=[2,3,4,5,2] #神经网络形状 第一层2个神经元,第二层3个神经元,第三层4个神经元,第四层2个神经元
#标准化函数
def normalize(array):
max_number=np.max(np.absolute(array),axis=1,keepdims=True) #找每一行最大值(绝对值)
scale_rate=np.where(max_number==0,1,1/max_number)
norm=array*scale_rate
return norm
#激活函数
def activation_ReLU(inputs):
return np.maximum(0,inputs)
#softmax激活函数 每行相加等于1 概率 ///放在最后一层的激活函数
def activation_softmax(inputs):
max_values=np.max(inputs,axis=1,keepdims=True) #挑选每一行最大值
slided_inputs=inputs -max_values #减去最大值
exp_values=np.exp(slided_inputs) #对slided_inputs求指数
norm_base=np.sum(exp_values,axis=1,keepdims=True) #每一行数求和
norm_values=exp_values/norm_base #标准化
return norm_values
#定义一个层类
class Layer: #定义类,用class
def __init__(self,n_inputs,n_neurons):
self.weights=np.random.randn(n_inputs, n_neurons)
self.biases=np.random.randn(n_neurons)
def layer_forward(self,inputs): #定义向前运算函数——解决层的运算
self.output=np.dot(inputs, self.weights)+self.biases
return self.output
#定义一个网络类
class Network:
def __init__(self,network_shape): #定义层
self.shape=network_shape
self.layers=[ ]
for i in range(len(network_shape)-1): #减1是因为有4层神经元,就有4-1层权重矩阵 (w以及b)
layer=Layer(network_shape[i],network_shape[i+1])
self.layers.append(layer) #append表示将layer放入到·layers中
#前馈运算函数
def network_forward(self, inputs): #定义层的运算
outputs=[inputs]
for i in range (len(self.layers)):
layer_sum = self.layers[i].layer_forward(outputs[i])
if i < len(self.layers)-1:
layer_output=activation_ReLU(layer_sum)
layer_output=normalize(layer_output) #标准化
else:
layer_output=activation_softmax(layer_sum)
outputs.append(layer_output)
print(outputs)
return outputs
#----------------------------------------------------------------------------
#输入
a11=0.9
a21=-0.4
a12=-0.8
a22=0.5
a13=-0.5
a23=-0.8
a14=0.7
a24=-0.3
a15=-0.9
a25=0.4
#batch
inputs=np.array([[a11, a21],
[a12,a22],
[a13,a23],
[a14,a24],
[a15,a25]])
def main():
network=Network(NETWORK_SHAPE)
network.network_forward(inputs)
#----------TEST-----------
def test ():
pass
#-----------yunxing-------------
main()06、生成数据和可视化
00、分类任务与数据

#生成数据和可视化
import matplotlib.pyplot as plt
import numpy as np
import math
import random
import matplotlib.pyplot as plot
NUM_OF_DATA=100
def tag_entry(x,y): #设置打标
if x**2+y**2<1:
tag=0
else:
tag=1
return tag
def creat_data(num_of_data): #随机生成数据
entry_list=[]
for i in range(num_of_data):
x=random.uniform(-2,2)
y=random.uniform(-2,2)
tag= tag_entry(x,y)
entry=[x,y,tag]
entry_list.append(entry)
return np.array(entry_list)
#------------可视化--------
def plot_data(data,title):
color=[]
for i in data[:,2]: #[:,2]指每一行第三个元素
if i==0:
color.append("orange")
else:
color.append("blue")
plt.scatter(data[:,0],data[:,1],c=color) #scatter 表示散点
plt.title(title)
plt.show()
#-----------------
if __name__=="__main__":
data=creat_data(NUM_OF_DATA)
print( data)
plot_data(data,"demo")
# print(creat_data(NUM_OF_DATA))
01、调用数据
import numpy as np
import test1 as ts
NETWORK_SHAPE=[2,3,4,5,2] #神经网络形状 第一层2个神经元,第二层3个神经元,第三层4个神经元,第四层2个神经元
#标准化函数
def normalize(array):
max_number=np.max(np.absolute(array),axis=1,keepdims=True) #找每一行最大值(绝对值)
scale_rate=np.where(max_number==0,1,1/max_number)
norm=array*scale_rate
return norm
#激活函数
def activation_ReLU(inputs):
return np.maximum(0,inputs)
#分类函数
def classify(probabilities):
classification=np.rint(probabilities[:,1]) #取出的值进行“四舍五入”
return classification
#softmax激活函数 每行相加等于1 概率 ///放在最后一层的激活函数
def activation_softmax(inputs):
max_values=np.max(inputs,axis=1,keepdims=True) #挑选每一行最大值
slided_inputs=inputs -max_values #减去最大值
exp_values=np.exp(slided_inputs) #对slided_inputs求指数
norm_base=np.sum(exp_values,axis=1,keepdims=True) #每一行数求和
norm_values=exp_values/norm_base #标准化
return norm_values
#定义一个层类
class Layer: #定义类,用class
def __init__(self,n_inputs,n_neurons):
self.weights=np.random.randn(n_inputs, n_neurons)
self.biases=np.random.randn(n_neurons)
def layer_forward(self,inputs): #定义向前运算函数——解决层的运算
self.output=np.dot(inputs, self.weights)+self.biases
return self.output
#定义一个网络类
class Network:
def __init__(self,network_shape): #定义层
self.shape=network_shape
self.layers=[ ]
for i in range(len(network_shape)-1): #减1是因为有4层神经元,就有4-1层权重矩阵 (w以及b)
layer=Layer(network_shape[i],network_shape[i+1])
self.layers.append(layer) #append表示将layer放入到·layers中
#前馈运算函数
def network_forward(self, inputs): #定义层的运算
outputs=[inputs]
for i in range (len(self.layers)):
layer_sum = self.layers[i].layer_forward(outputs[i])
if i < len(self.layers)-1:
layer_output=activation_ReLU(layer_sum)
layer_output=normalize(layer_output) #标准化
else:
layer_output=activation_softmax(layer_sum)
outputs.append(layer_output)
print(outputs)
return outputs
def main():
data= ts.creat_data(100)
print (data)
ts.plot_data(data,"Right classification")
inputs=data[:,(0,1)] #data数据共有三列,第三列为标签。故第三列不进入神经网络计算 即 取前两列
print(inputs)
network=Network(NETWORK_SHAPE)
outputs= network.network_forward(inputs)
classification=classify(outputs[-1])
print(classification)
data[:,2]=classification
print((data))
ts.plot_data(data,"Before traning")
#----------TEST-----------
def test ():
pass
#-----------yunxing-------------
main()*注释:此代码中的test1 即为分类任务与数据代码名称
07、反向传播算法
00、基础知识
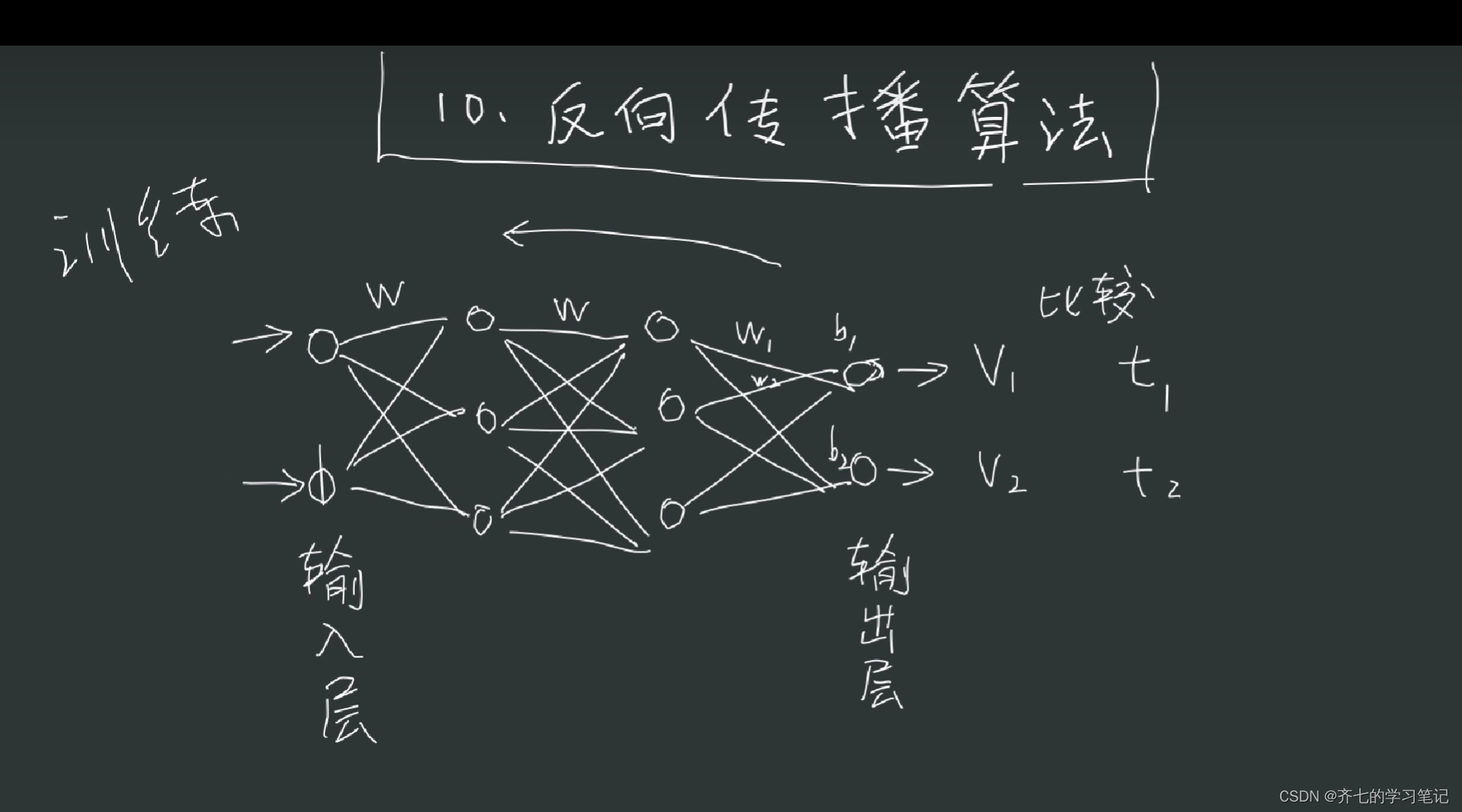



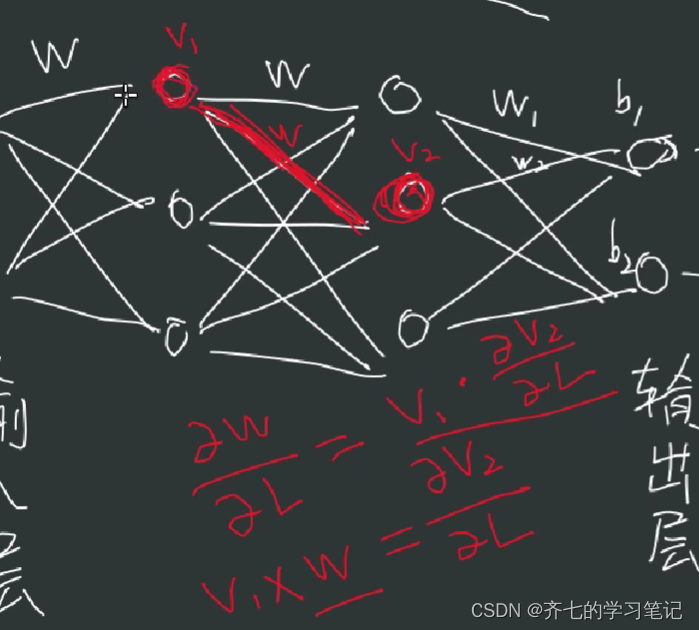
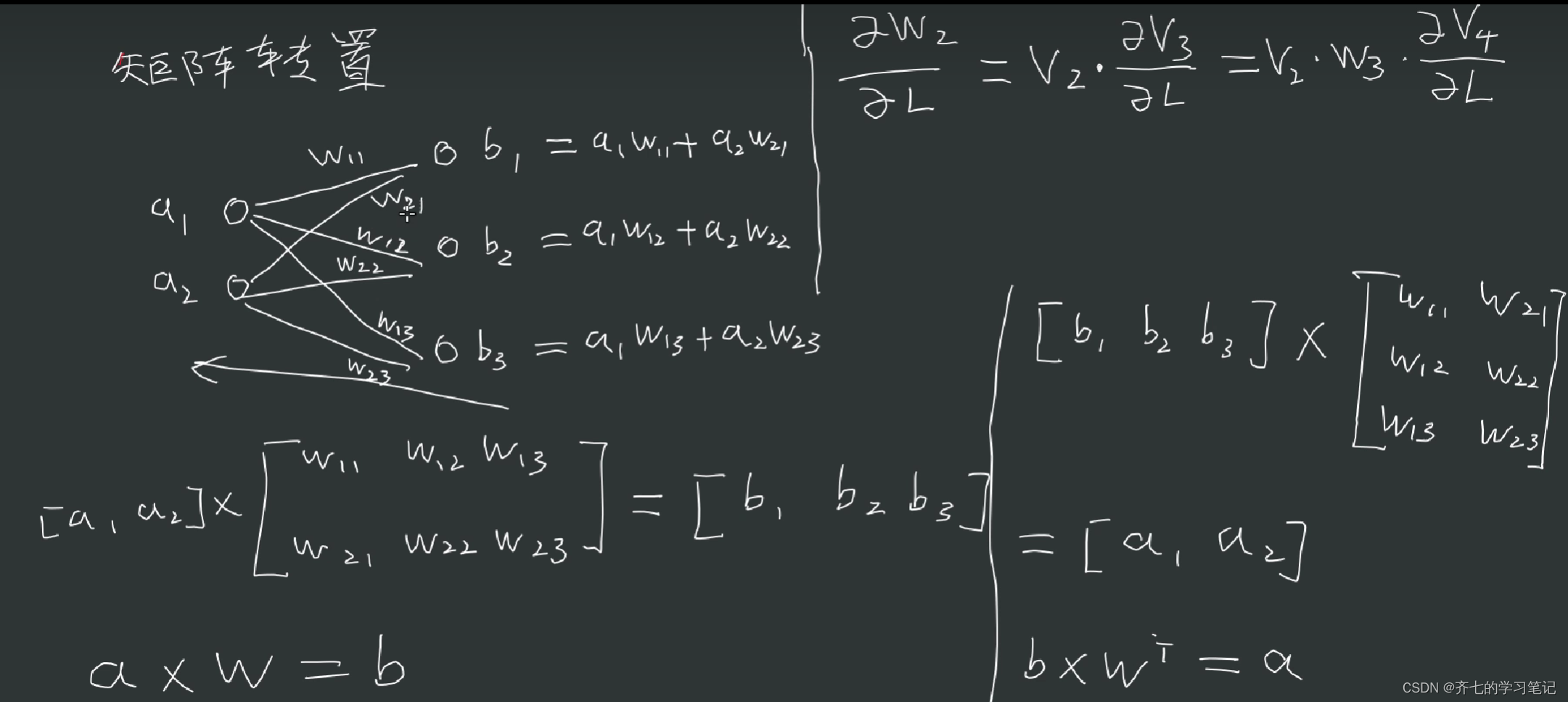
02、损失函数

import numpy as np
import test1 as ts
NETWORK_SHAPE=[2,3,4,5,2] #神经网络形状 第一层2个神经元,第二层3个神经元,第三层4个神经元,第四层2个神经元
#标准化函数
def normalize(array):
max_number=np.max(np.absolute(array),axis=1,keepdims=True) #找每一行最大值(绝对值)
scale_rate=np.where(max_number==0,1,1/max_number)
norm=array*scale_rate
return norm
#激活函数
def activation_ReLU(inputs):
return np.maximum(0,inputs)
#分类函数
def classify(probabilities):
classification=np.rint(probabilities[:,1]) #取出的值进行“四舍五入”
return classification
#softmax激活函数 每行相加等于1 概率 ///放在最后一层的激活函数
def activation_softmax(inputs):
max_values=np.max(inputs,axis=1,keepdims=True) #挑选每一行最大值
slided_inputs=inputs -max_values #减去最大值
exp_values=np.exp(slided_inputs) #对slided_inputs求指数
norm_base=np.sum(exp_values,axis=1,keepdims=True) #每一行数求和
norm_values=exp_values/norm_base #标准化
return norm_values
#损失函数
def precise_loss_function(predicted,real):
real_matrix=np.zeros((len(real),2))
print(real)
real_matrix[:,1]=real
real_matrix[:,0]=1-real
print(real_matrix)
product=np.sum(predicted*real_matrix , axis=1)
return 1-product
#定义一个层类
class Layer: #定义类,用class
def __init__(self,n_inputs,n_neurons):
self.weights=np.random.randn(n_inputs, n_neurons)
self.biases=np.random.randn(n_neurons)
def layer_forward(self,inputs): #定义向前运算函数——解决层的运算
self.output=np.dot(inputs, self.weights)+self.biases
return self.output
#定义一个网络类
class Network:
def __init__(self,network_shape): #定义层
self.shape=network_shape
self.layers=[ ]
for i in range(len(network_shape)-1): #减1是因为有4层神经元,就有4-1层权重矩阵 (w以及b)
layer=Layer(network_shape[i],network_shape[i+1])
self.layers.append(layer) #append表示将layer放入到·layers中
#前馈运算函数
def network_forward(self, inputs): #定义层的运算
outputs=[inputs]
for i in range (len(self.layers)):
layer_sum = self.layers[i].layer_forward(outputs[i])
if i < len(self.layers)-1:
layer_output=activation_ReLU(layer_sum)
layer_output=normalize(layer_output) #标准化
else:
layer_output=activation_softmax(layer_sum)
outputs.append(layer_output)
print(outputs)
return outputs
def main():
data= ts.creat_data(5)
print (data)
ts.plot_data(data,"Right classification")
inputs=data[:,(0,1)] #data数据共有三列,第三列为标签。故第三列不进入神经网络计算 即 取前两列
tatgets=data[:,2 ] #标准答案
print(inputs)
network=Network(NETWORK_SHAPE)
outputs= network.network_forward(inputs)
classification=classify(outputs[-1])
print(classification)
data[:,2]=classification
print((data))
loss= precise_loss_function(outputs[-1],tatgets)
print(loss)
ts.plot_data(data,"Before traning")
#----------TEST-----------
def test ():
pass
#-----------yunxing-------------
main()
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









