









**
背景
**
docker有一点好处就是,一次完成,处处运行,所以此次并非直接在centos系统上直接运行hadoop,而是在docker容器(container)里进行安装。
(1)
首先写好dockerfile文件,然后使用docker build命令进行创建镜像,这时候出来的镜像内部只有centos基础环境与hadoop和jdk的安装包和一些基础的用户组配置
dockerfile文件:
(ps:moudle应为module,拼写出错)
#选择centos7.7.1908作为基础镜像
FROM centos:centos7.7.1908
#镜像维护者信息
MAINTAINER "gzq<ziwanguo@gmail.com>"
#描述信息
LABEL name="Hadoop-Single"
#构建容器时需要运行的命令
#安装openssh-server、openssh-clients、sudo、vim和net-tools软件包
RUN yum -y install openssh-server openssh-clients sudo vim net-tools
#生成相应的主机密钥文件
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key
RUN ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key
#创建自定义组和用户、设置密码并授予root权限
RUN groupadd -g 1124 bigdata && useradd -m -u 1124 -g bigdata cdata01
RUN echo "cdata01:cdata@2020" | chpasswd
RUN echo "cdata01 ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
#创建模块和软件目录并修改权限
RUN mkdir /opt/software && mkdir /opt/moudle
#将宿主机的文件拷贝至镜像(ADD会自动解压)
ADD jdk-8u141-linux-x64.tar.gz /opt/moudle
ADD hadoop-2.7.5.tar.gz /opt/software
RUN chown -R cdata01:bigdata /opt/moudle && chown -R cdata01:bigdata /opt/software
#设置环境变量
ENV CENTOS_DEFAULT_HOME /root
ENV JAVA_HOME /opt/moudle/jdk1.8.0_141
ENV HADOOP_HOME /opt/software/hadoop-2.7.5
ENV JRE_HOME ${JAVA_HOME}/jre
ENV CLASSPATH ${JAVA_HOME}/lib:${JRE_HOME}/lib
ENV PATH ${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#终端默认登录进来的工作目录
WORKDIR $CENTOS_DEFAULT_HOME
#启动sshd服务并且暴露22端口
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
执行命令前,先把对应的hadoop和jdk的jar包放到相应的文件目录下
命令:
docker build -f xxx(写好的dockerfile) -t xxx(作者)/xxx(名称):xxx(想写的tag)
# 我的命令:
docker build -f hadoop-2.7.5-Dockerfile -t gzq/hadoop2.7.5:pseudo-1.0
(2)
创建自定义网络并以端口映射的形式进入容器并将相关的配置文件进行修改
启动docker时每次都会重新获取ip地址,这样可能会造成ip地址一直在变化的情况,为了统一ip地址,可以进行如下操做。
先通过docker network ls命令查看docker自带的network(其中bridge为默认模式),通过**docker network inspect xxx(NETWORK ID)**可以查看docker的默认网段:

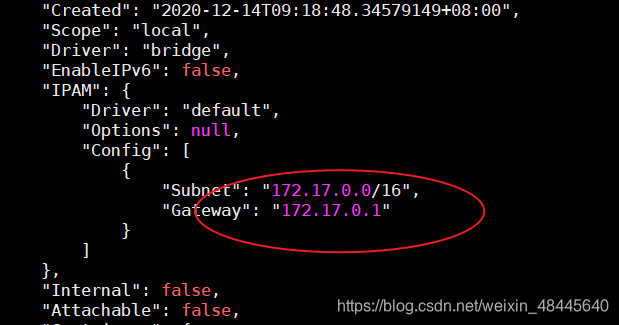
随后自己可以定义新的网段:
docker network create --subnet=172.22.0.0/24 mynetwork
开启镜像命令:
docker run -d(守护方式运行) --name xxx(想给该容器起的名字) --hostname xxx(想给centos起的主机名) --net xxx --ip(想用的固定ip) -P(dockerfile中设置暴露的端口号) -p xxx:xxx(端口映射,可以写多个,前面都要加上-p选项) 镜像id
#我的命令:
docker run -d --name hadooptest --hostname cdata01 -P -p 2181:2181 -p 16020:16020 -p 60020:60020 -p 60000:60000 -p 8020:8020 -p 50070:50070 -p 8088:8088 -p 19888:19888 -p 16000:16000 -p 16010:16010 镜像ID
进入镜像命令:
先docker ps -a 查看自己刚刚守护运行的container的ID号(容器镜像号)
docker exec -ti(t:终端,i:交互模式)xxx(容器镜像号)
重要:进入后将hbase,jdk,zookeeper所有的权限变成cdata01:bigdata用户组,执行完后,su cdata01到你管辖的用户下
chown -R cdata01:bigdata xxx(想递归的目录)
修改的文件:
1.hadoop
<1>.bash_profile(如果非root用户就写成自己的用户下的文件)(因为我在dockerfile里已经执行了该命令,所以就没必要修改这个文件了)
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
export JAVA_HOME=/home/cdata/deployment/jdk1.8.0_141
export PATH=:$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/home/cdata/deployment/hadoop-2.7.5
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
<2>core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://cdata01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/cdata01/data/tmp</value>
</property>
</configuration>
<3>hadoop-env.sh
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges.
# This **MUST** be uncommented to enable secure HDFS if using privileged ports
# to provide authentication of data transfer protocol. This **MUST NOT** be
# defined if SASL is configured for authentication of data transfer protocol
# using non-privileged ports.
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
# Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
# Where log files are stored in the secure data environment.
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
###
# HDFS Mover specific parameters
###
# Specify the JVM options to be used when starting the HDFS Mover.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HADOOP_MOVER_OPTS=""
###
# Advanced Users Only!
###
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
export JAVA_HOME=/opt/moudle/jdk1.8.0_141
<4>hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cdata01:50090</value>
</property>
</configuration>
<5>mapred-env.sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
#export HADOOP_JOB_HISTORYSERVER_OPTS=
#export HADOOP_MAPRED_LOG_DIR="" # Where log files are stored. $HADOOP_MAPRED_HOME/logs by default.
#export HADOOP_JHS_LOGGER=INFO,RFA # Hadoop JobSummary logger.
#export HADOOP_MAPRED_PID_DIR= # The pid files are stored. /tmp by default.
#export HADOOP_MAPRED_IDENT_STRING= #A string representing this instance of hadoop. $USER by default
#export HADOOP_MAPRED_NICENESS= #The scheduling priority for daemons. Defaults to 0.
export JAVA_HOME=/home/cdata/deployment/jdk1.8.0_141
<6>mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
<7>slaves
cdata01
<8>yarn-env.sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# User for YARN daemons
export HADOOP_YARN_USER=${HADOOP_YARN_USER:-yarn}
# resolve links - $0 may be a softlink
export YARN_CONF_DIR="${YARN_CONF_DIR:-$HADOOP_YARN_HOME/conf}"
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi
if [ "$JAVA_HOME" = "" ]; then
echo "Error: JAVA_HOME is not set."
exit 1
fi
JAVA=$JAVA_HOME/bin/java
JAVA_HEAP_MAX=-Xmx1000m
# For setting YARN specific HEAP sizes please use this
# Parameter and set appropriately
# YARN_HEAPSIZE=1000
# check envvars which might override default args
if [ "$YARN_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_HEAPSIZE""m"
fi
# Resource Manager specific parameters
# Specify the max Heapsize for the ResourceManager using a numerical value
# in the scale of MB. For example, to specify an jvm option of -Xmx1000m, set
# the value to 1000.
# This value will be overridden by an Xmx setting specified in either YARN_OPTS
# and/or YARN_RESOURCEMANAGER_OPTS.
# If not specified, the default value will be picked from either YARN_HEAPMAX
# or JAVA_HEAP_MAX with YARN_HEAPMAX as the preferred option of the two.
#export YARN_RESOURCEMANAGER_HEAPSIZE=1000
# Specify the max Heapsize for the timeline server using a numerical value
# in the scale of MB. For example, to specify an jvm option of -Xmx1000m, set
# the value to 1000.
# This value will be overridden by an Xmx setting specified in either YARN_OPTS
# and/or YARN_TIMELINESERVER_OPTS.
# If not specified, the default value will be picked from either YARN_HEAPMAX
# or JAVA_HEAP_MAX with YARN_HEAPMAX as the preferred option of the two.
#export YARN_TIMELINESERVER_HEAPSIZE=1000
# Specify the JVM options to be used when starting the ResourceManager.
# These options will be appended to the options specified as YARN_OPTS
# and therefore may override any similar flags set in YARN_OPTS
#export YARN_RESOURCEMANAGER_OPTS=
# Node Manager specific parameters
# Specify the max Heapsize for the NodeManager using a numerical value
# in the scale of MB. For example, to specify an jvm option of -Xmx1000m, set
# the value to 1000.
# This value will be overridden by an Xmx setting specified in either YARN_OPTS
# and/or YARN_NODEMANAGER_OPTS.
# If not specified, the default value will be picked from either YARN_HEAPMAX
# or JAVA_HEAP_MAX with YARN_HEAPMAX as the preferred option of the two.
#export YARN_NODEMANAGER_HEAPSIZE=1000
# Specify the JVM options to be used when starting the NodeManager.
# These options will be appended to the options specified as YARN_OPTS
# and therefore may override any similar flags set in YARN_OPTS
#export YARN_NODEMANAGER_OPTS=
# so that filenames w/ spaces are handled correctly in loops below
IFS=
# default log directory & file
if [ "$YARN_LOG_DIR" = "" ]; then
YARN_LOG_DIR="$HADOOP_YARN_HOME/logs"
fi
if [ "$YARN_LOGFILE" = "" ]; then
YARN_LOGFILE='yarn.log'
fi
# default policy file for service-level authorization
if [ "$YARN_POLICYFILE" = "" ]; then
YARN_POLICYFILE="hadoop-policy.xml"
fi
# restore ordinary behaviour
unset IFS
YARN_OPTS="$YARN_OPTS -Dhadoop.log.dir=$YARN_LOG_DIR"
YARN_OPTS="$YARN_OPTS -Dyarn.log.dir=$YARN_LOG_DIR"
YARN_OPTS="$YARN_OPTS -Dhadoop.log.file=$YARN_LOGFILE"
YARN_OPTS="$YARN_OPTS -Dyarn.log.file=$YARN_LOGFILE"
YARN_OPTS="$YARN_OPTS -Dyarn.home.dir=$YARN_COMMON_HOME"
YARN_OPTS="$YARN_OPTS -Dyarn.id.str=$YARN_IDENT_STRING"
YARN_OPTS="$YARN_OPTS -Dhadoop.root.logger=${YARN_ROOT_LOGGER:-INFO,console}"
YARN_OPTS="$YARN_OPTS -Dyarn.root.logger=${YARN_ROOT_LOGGER:-INFO,console}"
if [ "x$JAVA_LIBRARY_PATH" != "x" ]; then
YARN_OPTS="$YARN_OPTS -Djava.library.path=$JAVA_LIBRARY_PATH"
fi
YARN_OPTS="$YARN_OPTS -Dyarn.policy.file=$YARN_POLICYFILE"
export JAVA_HOME=/opt/moudle/jdk1.8.0_141
<9>yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager</name>
<value>cdata01</value>
</property>
</configuration>
2.zookeeper
创建好zookeeper和zkData目录,否则开启时会报错
zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/cdata01/data/zookeeper/zkData
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
3.hbase
<1>hbase-env.sh
#
#/**
# * Licensed to the Apache Software Foundation (ASF) under one
# * or more contributor license agreements. See the NOTICE file
# * distributed with this work for additional information
# * regarding copyright ownership. The ASF licenses this file
# * to you under the Apache License, Version 2.0 (the
# * "License"); you may not use this file except in compliance
# * with the License. You may obtain a copy of the License at
# *
# * http://www.apache.org/licenses/LICENSE-2.0
# *
# * Unless required by applicable law or agreed to in writing, software
# * distributed under the License is distributed on an "AS IS" BASIS,
# * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# * See the License for the specific language governing permissions and
# * limitations under the License.
# */
# Set environment variables here.
# This script sets variables multiple times over the course of starting an hbase process,
# so try to keep things idempotent unless you want to take an even deeper look
# into the startup scripts (bin/hbase, etc.)
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/opt/moudle/jdk1.8.0_141
# Extra Java CLASSPATH elements. Optional.
# export HBASE_CLASSPATH=
# The maximum amount of heap to use. Default is left to JVM default.
# export HBASE_HEAPSIZE=1G
# Uncomment below if you intend to use off heap cache. For example, to allocate 8G of
# offheap, set the value to "8G".
# export HBASE_OFFHEAPSIZE=1G
# Extra Java runtime options.
# Below are what we set by default. May only work with SUN JVM.
# For more on why as well as other possible settings,
# see http://wiki.apache.org/hadoop/PerformanceTuning
export HBASE_OPTS="-XX:+UseConcMarkSweepGC"
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
# Uncomment one of the below three options to enable java garbage collection logging for the server-side processes.
# This enables basic gc logging to the .out file.
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
# This enables basic gc logging to its own file.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>"
# This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M"
# Uncomment one of the below three options to enable java garbage collection logging for the client processes.
# This enables basic gc logging to the .out file.
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
# This enables basic gc logging to its own file.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>"
# This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M"
# See the package documentation for org.apache.hadoop.hbase.io.hfile for other configurations
# needed setting up off-heap block caching.
# Uncomment and adjust to enable JMX exporting
# See jmxremote.password and jmxremote.access in $JRE_HOME/lib/management to configure remote password access.
# More details at: http://java.sun.com/javase/6/docs/technotes/guides/management/agent.html
# NOTE: HBase provides an alternative JMX implementation to fix the random ports issue, please see JMX
# section in HBase Reference Guide for instructions.
# export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10101"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10102"
# export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10103"
# export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10104"
# export HBASE_REST_OPTS="$HBASE_REST_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10105"
# File naming hosts on which HRegionServers will run. $HBASE_HOME/conf/regionservers by default.
# export HBASE_REGIONSERVERS=${HBASE_HOME}/conf/regionservers
# Uncomment and adjust to keep all the Region Server pages mapped to be memory resident
#HBASE_REGIONSERVER_MLOCK=true
#HBASE_REGIONSERVER_UID="hbase"
# File naming hosts on which backup HMaster will run. $HBASE_HOME/conf/backup-masters by default.
# export HBASE_BACKUP_MASTERS=${HBASE_HOME}/conf/backup-masters
# Extra ssh options. Empty by default.
# export HBASE_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HBASE_CONF_DIR"
# Where log files are stored. $HBASE_HOME/logs by default.
# export HBASE_LOG_DIR=${HBASE_HOME}/logs
# Enable remote JDWP debugging of major HBase processes. Meant for Core Developers
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8070"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8071"
# export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8072"
# export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8073"
# A string representing this instance of hbase. $USER by default.
# export HBASE_IDENT_STRING=$USER
# The scheduling priority for daemon processes. See 'man nice'.
# export HBASE_NICENESS=10
# The directory where pid files are stored. /tmp by default.
# export HBASE_PID_DIR=/var/hadoop/pids
# Seconds to sleep between slave commands. Unset by default. This
# can be useful in large clusters, where, e.g., slave rsyncs can
# otherwise arrive faster than the master can service them.
# export HBASE_SLAVE_SLEEP=0.1
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
# 不使用hbase自带的zookeeper
export HBASE_MANAGES_ZK=false
# The default log rolling policy is RFA, where the log file is rolled as per the size defined for the
# RFA appender. Please refer to the log4j.properties file to see more details on this appender.
# In case one needs to do log rolling on a date change, one should set the environment property
# HBASE_ROOT_LOGGER to "<DESIRED_LOG LEVEL>,DRFA".
# For example:
# HBASE_ROOT_LOGGER=INFO,DRFA
# The reason for changing default to RFA is to avoid the boundary case of filling out disk space as
# DRFA doesn't put any cap on the log size. Please refer to HBase-5655 for more context.
<2>hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://cdata01:8020/HBase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98 后的新变动,之前版本没有.port,默认端口为 60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>cdata01</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>cdata01</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/cdata01/data/zookeeper/zkData</value>
</property>
</configuration>
<3>regionservers
cdata01
(3)
开启hdfs和yarn服务
第一次启动先格式化:
hdfs namenode -format
分别启动hdfs和yarn
start-dfs.sh
start-yarn.sh
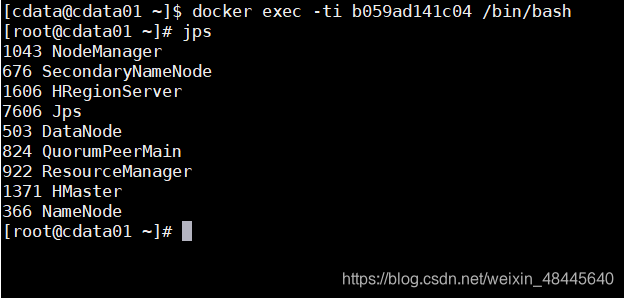
通过jps查看是否启动成功
(4)
开启zookeeper服务
通过命令:
zkServer.sh start
(5)
开启hbase服务:
start-hbase.sh
(6)
退出镜像打包容器即可:
此时保持镜像正常运行,退出后,进行打包:
docker commit -a"(xxx作者名)" -m "xxx(描述)" xxx(通过docker ps查出你要打包的容器ID) xxx(镜像名称)
随后进行最后的上传操作:
首先要有阿里云的账号(通过支付宝扫码登陆即可)
网址:https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fcr.console.aliyun.com%2Frepository%2Fcn-hangzhou%2Fpseduo-hadoop%2Fhadoop-2.7.5%2Fdetails&lang=zh
进去后创建自己的容器:

随后按照阿里云的方法进行操作即可:
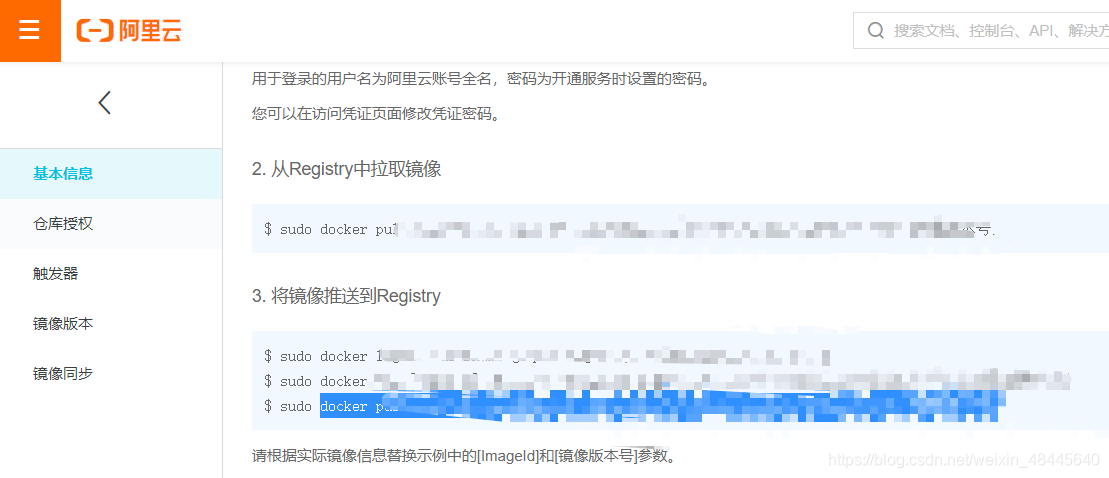
打包成功:

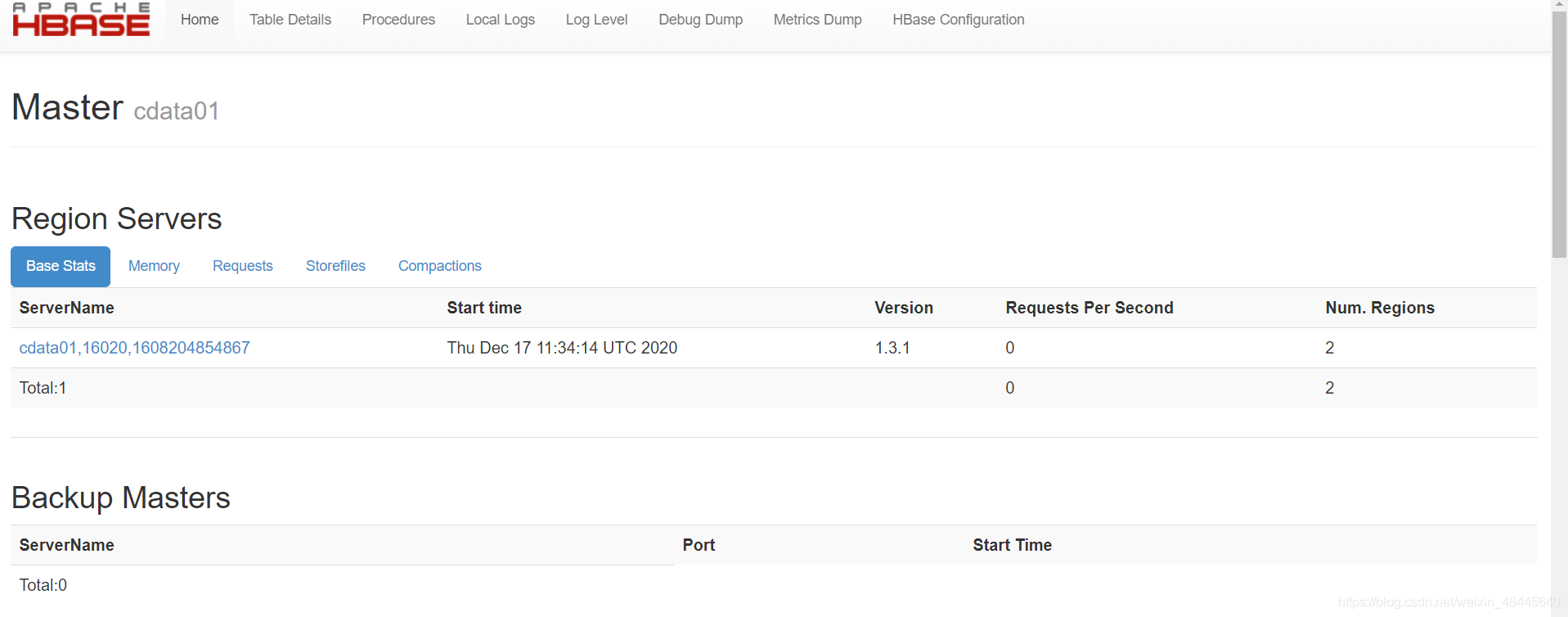
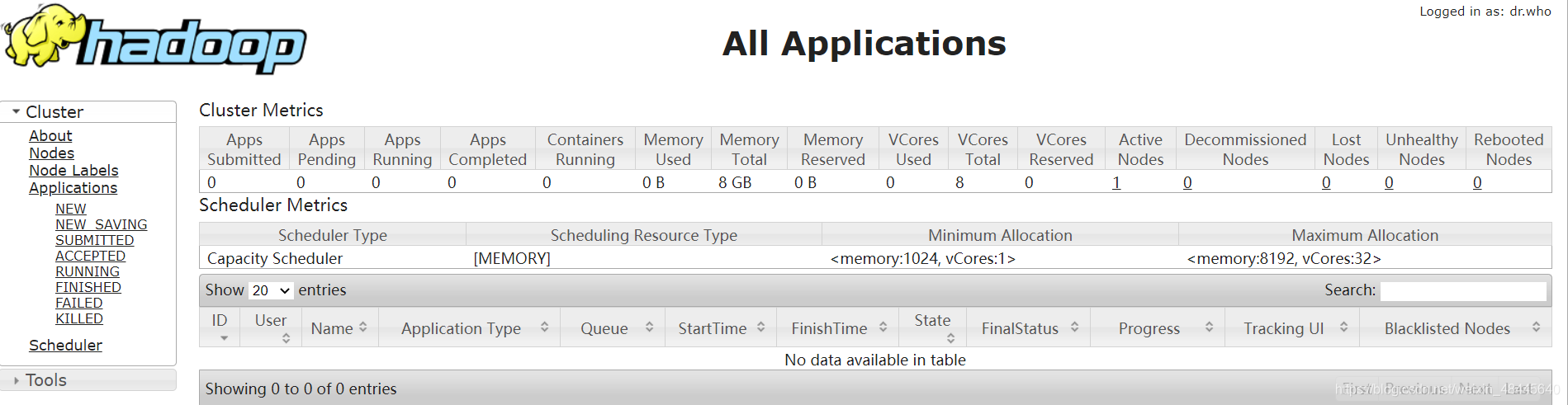
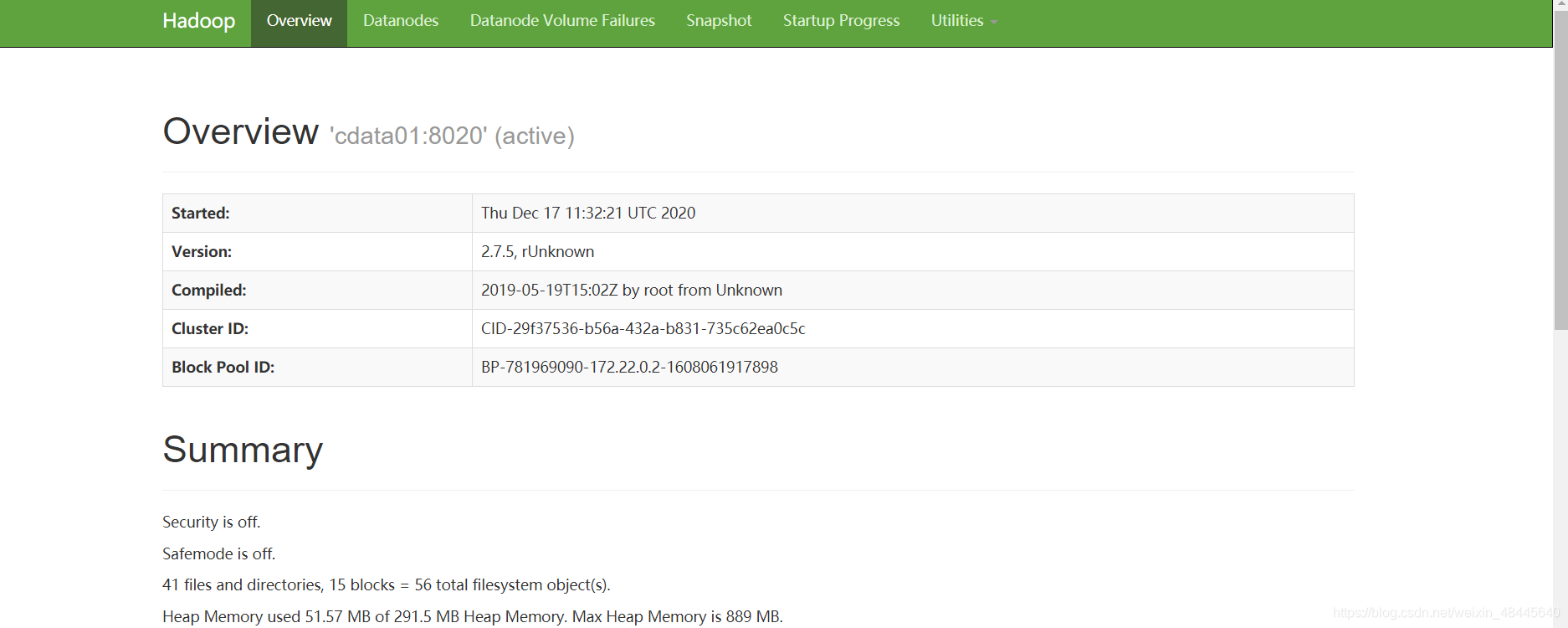
最终容器内的效果图:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











