






python超详细的基础爬虫
环境:python3
工具:pycharm
第三方库:requests,BeautifulSoup
python的环境部署在这里就不再赘述,第三方库的安装可以用pip下载,也可以在pycharm中install安装,个人比较喜欢用第二种方式
开始爬取(以豆瓣电影Top250为例)
开始之前先看看网站页面构成

我们可以看到电影名字在class='hd’下的div标签下的a标签下的class='title’的span标签中,但是注意到这里相同类型的标签有两个,分别是中文名与原名,我们先爬取下来看看结果吧
先导入第三方库
import requests
from bs4 import BeautifulSoup
先看看调试的代码吧,打印出来看看是不是想要的电影名
url="https://movie.douban.com/top250" #目标url地址
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'} #请求头
soup=requests.get(url=url,headers=headers).text #获取到网页内容
soup_one= BeautifulSoup(soup, "html.parser") #解析网页,固定格式
move_title=soup_one.find('span',class_="title") #定位标签
print(move_title.string)
 编码格式错误,pycharm默认编码格式是utf8,那不行就换gbk,只需要在代码开头指定一下编码格式就好了
编码格式错误,pycharm默认编码格式是utf8,那不行就换gbk,只需要在代码开头指定一下编码格式就好了
#coding:utf8
import requests
from bs4 import BeautifulSoup
def top250():
url="https://movie.douban.com/top250" #目标url地址
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'} #请求头
soup=requests.get(url=url,headers=headers).text #获取到网页内容
soup_one= BeautifulSoup(soup, "html.parser") #解析网页,固定格式
move_title=soup_one.find('span',class_="title") #定位标签
print(move_title.string)
top250()
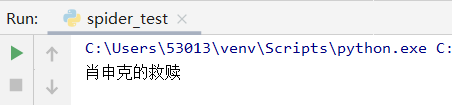
打印出来就是我们想要的标题了,find方法只会找到第一个满足条件的标签,我们再把第一页的电影名爬取出来看看,用find_all方法。因为我们定位的标签中会有电影的原名,所以打印出来时总会报编码错误,我们就把结果写入本地文件看看
#coding:utf8
import requests
from bs4 import BeautifulSoup
def top250():
url="https://movie.douban.com/top250" #目标url地址
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'} #请求头
soup=requests.get(url=url,headers=headers).text #获取到网页内容
soup_one= BeautifulSoup(soup, "html.parser") #解析网页,固定格式
move_title=soup_one.find_all('span',class_="title") #定位标签
with open("./movemane_list.txt", 'a', encoding='utf8') as f:
for i in move_title:
f.write(str(i.string)+'\n')
top250()

这里的爬取结果就是电影中文翻译名与原名,这里我们只要电影中文名就好了,所以我们换个位置看看有没有电影中文名的
 我们搜索一下发现这个img标签中有电影封面的图片地址,同时也包含电影名
我们搜索一下发现这个img标签中有电影封面的图片地址,同时也包含电影名
那我们爬取下来看看呢
move_title=soup_one.find_all('img')
 确实是我们要的结果,可是最后两个不是我们想要的,那我们就不直接去定位img标签,通过img的父标签定位看看
确实是我们要的结果,可是最后两个不是我们想要的,那我们就不直接去定位img标签,通过img的父标签定位看看
move_title=soup_one.find_all('div',class_='pic') #定位标签
with open("./movemane_list.txt", 'a', encoding='utf8') as f:
for i in move_title:
f.write(str(i.a.img)+'\n')
如果一个标签x包含子标签y,那我们可以通过x.y的标签名来定位到这个标签
 现在结果就是我们想看到的了
现在结果就是我们想看到的了
可是我们要的是Top250所有的电影名称,这时候我们就需要找出每一页url地址的规律来一页一页的循环爬取
https://movie.douban.com/top250?start=25&filter= 这是第二页的url地址
https://movie.douban.com/top250?start=50&filter= 这是第三页的url地址
不难看出每页显示25个电影,一共十页
#coding:utf8
import requests
from bs4 import BeautifulSoup
def top250():
for i in range(0,10):
url="https://movie.douban.com/top250?start=%s"%(i*25) #目标url地址
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'} #请求头
soup=requests.get(url=url,headers=headers).text #获取到网页内容
soup_one= BeautifulSoup(soup, "html.parser") #解析网页,固定格式
move_title=soup_one.find_all('div',class_='pic') #定位标签
with open("./movemane_list.txt", 'a', encoding='utf8') as f:
for i in move_title:
title=str(i.a.img).split('alt="')[1].split('"')[0]
f.write(title+'\n')
top250()
以上是全部代码
有不对的地方欢迎留言指正
喜欢我的小伙伴可以关注我哦,我会不定期分享爬虫学习心得















 1338
1338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









