







“ doris采用列式存储格式、索引类型丰富、join支持能力强。”
Doris 由百度大数据部研发 ( 之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris ),在百度内部,有超过200个产品线在使用,部署机器超过1000台。Doris 主要解决 PB 级别的数据量(如果高于 PB 级别,不推荐使用 Doris 解决,可以考虑用 Hive 等工具),解决结构化数据,查询时间一般在秒级或毫秒级
01
—
Doris技术架构
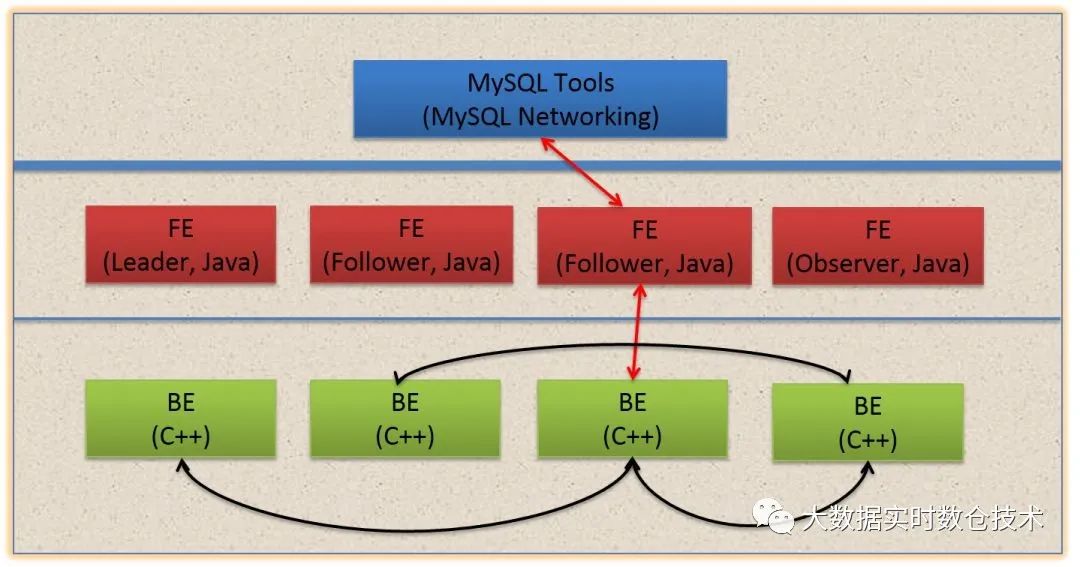
doris的技术架构如下图:
-
FE
-
1、FE主要有有三个角色,一个是leader,一个是follower,还有一个observer。leader跟follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。右边observer只是用来扩展查询节点,就是说如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加observer的节点。observer不参与任何的写入,只参与读取。
-
2、存储、维护集群元数据
-
3、接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果
-
-
BE
-
1、数据的可靠性由BE保证,BE会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
-
02
—
创建表核心技术点
在创建一张doris表前,需要考虑数据模型、分区和分桶、Engine和索引的选择。
1、数据模型选择
1.1、duplicate
在某些多维分析场景下,数据既没有主键,也没有聚合需求。比如:前端页面的埋点数据。
创建表示例:
CREATE TABLE dwd_traffic_events(day DATE,user_id SMALLINT,event_name varchar(20),event_value varchar(20))ENGINE=olapDUPLICATE KEY(day, user_id)PARTITION BY range(day)(PARTITION p20211222 VALUES LESS THAN ("20211223"),PARTITION p20211223 VALUES LESS THAN ("20211224"))DISTRIBUTED BY HASH(user_id) BUCKETS 10PROPERTIES("replication_num" = "1","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-3","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "10");
1.2、uniq
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。比如:用户表。
创建表示例:
CREATE TABLE dim_user(day DATE,id SMALLINT,name varchar(20),sex SMALLINT,age SMALLINT)ENGINE=olapUNIQUE KEY(day, id)PARTITION BY range(day)(PARTITION p20211222 VALUES LESS THAN ("20211223"),PARTITION p20211223 VALUES LESS THAN ("20211224"))DISTRIBUTED BY HASH(id) BUCKETS 10PROPERTIES("replication_num" = "1","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-3","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "10");
1.3、aggregate
通过聚合视图提前进行数据聚合,不存储明细。比如:数仓dws层的汇总表。
CREATE TABLE dws_traffic_event_stats(event_day DATE,sex SMALLINT,age_range SMALLINT,pv BIGINT SUM DEFAULT '0')ENGINE=olapAGGREGATE KEY(event_day, sex, age_range)PARTITION BY range(event_day)(PARTITION p20211222 VALUES LESS THAN ("20211223"),PARTITION p20211223 VALUES LESS THAN ("20211224"))DISTRIBUTED BY HASH(sex) BUCKETS 2PROPERTIES("replication_num" = "1","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-3","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "10");
1.4、rollup
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。在 Doris 中,我们将用户通过建表语句创建出来的表称为 Base 表(Base Table)。Base 表中保存着按用户建表语句指定的方式存储的基础数据。在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据。
base table可以是前三种数据模型中任意一种。
对 base table dws_traffic_event_stats创建一个 rollup_sex(sex, pv), 则以下 SQL Doris 会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
select sex, sum(pv) from dws_traffic_event_stats group by sex;
2、分区和分桶
DORIS 支持2种数据划分方式,和hive的分区分桶一致。第一层是 Partition,支持 Range 和 List 的划分方式。第二层是 Bucket(Tablet),仅支持 Hash 的划分方式。
3、Engine
olap为doris默认的引擎。在 Doris 中,只有这个 ENGINE 类型是由 Doris 负责数据管理和存储的。其他 ENGINE 类型,如 mysql、broker、es 等等,本质上只是对外部其他数据库或系统中的表的映射,以保证 Doris 可以读取这些数据。而 Doris 本身并不创建、管理和存储任何非 olap ENGINE 类型的表和数据。
4、索引
doris目前存在的索引有Ordinal Index、Short Key Index、ZoneMap Index、BloomFilter、BitmapIndex。开发需要关心的索引有Short Key Index、BloomFilter和BitmapIndex。Ordinal Index和ZoneMap Index对于每列来说是一定存在的,且无需开发者关心。
4.1、Short Key Index
根据前缀列值检索到行号。Short Key Index采用了创建表字段的前36 个字节,作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。
(1)以下表结构的前缀索引为 user_id(8Byte) + age(4Bytes) + message(prefix 24 Bytes)。
| ColumnName | Type |
| user_id | BIGINT |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATATIME |
(2)以下表结构的前缀索引为 user_name(20 Bytes)。即使没有达到 36 个字节,因为遇到 VARCHAR,所以直接截断,不再往后继续。
| Column | Type |
| user_name | VARCHAR(20) |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
SELECT * FROM table WHERE user_id=1829239 and age=20;该查询的效率会远高于如下查询:
SELECT * FROM table WHERE age=20;所以在建表时,正确的选择列顺序,能够极大地提高查询效率。
4.2、BloomFilter
当一些字段不能利用Short Key Index并且字段存在区分度比较大时,Doris提供了BloomFilter索引,可以减少扫描数据量。使用时需要在PROPERTIES中指定bloom_filter_columns要使用BloomFilter索引的字段。
4.3、BitmapIndex
在数据查询时,对于区分度不大,列的基数比较小的数据列,可以采用位图索引进行优化。比如,性别,婚姻,地理信息等。
CREATE INDEX index_name ON table1 (site_id) USING BITMAP COMMENT 'balabala';索引实现原理,可以参考:【Doris全面解析】存储层设计介绍1——存储结构设计解析 (qq.com)
5、Join
doris提供了4种join实现机制,可以在执行sql过程中自动选择使用哪种join机制。
5.1、Short Key Index
将小表发送到大表所在的每台机器,然后进行hash join操作。当一个表扫描出的数据量较少时,计算broadcast join的cost,通过计算比较hash partition的cost,来选择cost最小的方式。
5.2、BloomFilter
当两张表扫描出的数据都很大时,一般采用hash partition join。它遍历表中的所有数据,计算key的哈希值,然后对集群数取模,选到哪台机器,就将数据发送到这台机器进行hash join操作。
5.3、BitmapIndex
两个表在创建的时候就指定了数据分布保持一致,那么当两个表的join key与分桶的key一致时,就会采用colocate join算法。由于两个表的数据分布是一样的,那么hash join操作就相当于在本地,不涉及到数据的传输,极大提高查询性能。
5.4、bucket shuffle join
当join key是分桶key,并且只涉及到一个分区时,就会优先采用bucket shuffle join算法。由于分桶本身就代表了数据的一种切分方式,所以可以利用这一特点,只需将右表对左表的分桶数hash取模,这样只需网络传输一份右表数据,极大减少了数据的网络传输。
参考链接:
1、【Doris全面解析】存储层设计介绍1——存储结构设计解析 (qq.com)
2、 https://www.cnblogs.com/yyystar/p/15571114.html
















 2514
2514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









