






七猫公司简介
七猫是一家深耕文化娱乐行业的互联网企业,总部坐落在上海市前滩中心。七猫旗下原创文学网站七猫中文网于2017年5月正式上线,专注为原创作者提供创作指导、版权运营等全方位一体化服务。七猫拳头产品七猫免费小说App于2018年8月正式上线,专注为用户提供正版、免费、优质的网络文学内容阅读服务。现平台用户超6亿,规模位列数字阅读行业前列。

七猫大数据架构介绍
七猫的数仓团队主要是承接七猫各条业务线的离线数据开发、实时数据开发、指标建设、数据治理等工作。我加入七猫大约两年时间,加入后第一件事就是引入StarRocks。现在七猫有五套StarRocks集群在生产环境投入了使用。据不完全统计,数据治理前离线数据加实时数据,总数据量大约在20PB左右。那我们是如何维护和管理这些数据的呢?下面会通过一张简化版的数据架构图来介绍。
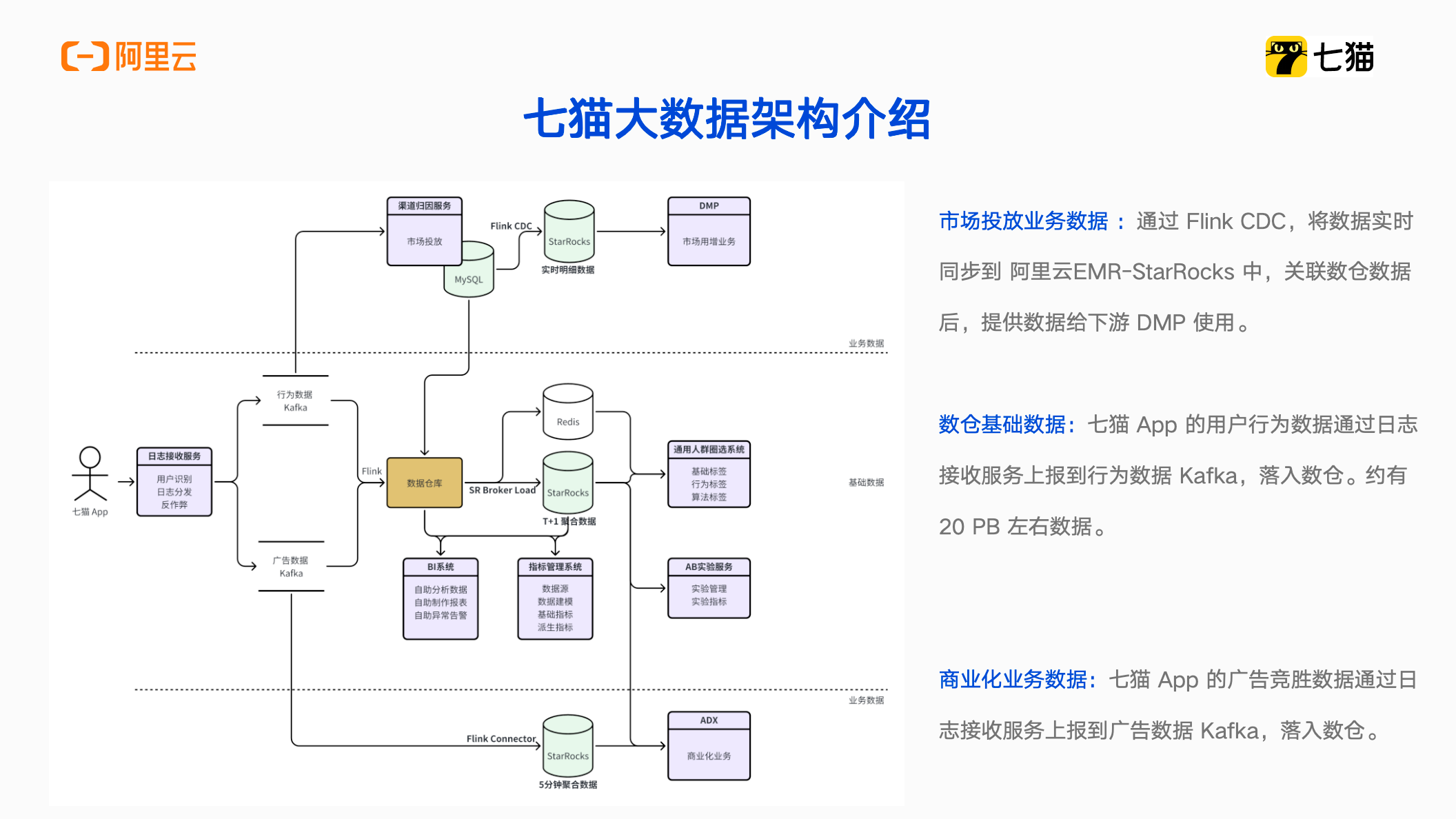
如上图所示,最左边是数据来源,这些数据源可以理解为用户在七猫APP上的用户行为数据,包括曝光、点击、阅读时长、点赞、评论、浏览广告等。这些数据会通过日志埋点的形式上报到日志接收系统。日志接收系统会将用户行为数据和广告数据进行分流,分别存在两个Kafka里面。大数据通过 Flink 实时消费两个 Kafka 的数据并实时写入到 Hive 数据表中。在 Hive 里进行一系列 ETL 操作之后,数据会流入到 StarRocks 和 Redis ,为下游的业务提供直接的数据服务,其中 Redis 主要应对的是高并发的场景。基于 StarRocks 和 Redis,下游开发各种系统,比如统一的 BI 系统、指标管理系统,AB实验系统、通用人群圈选系统等。后面将为大家重点介绍通用人群圈选系统的工作流程和设计思路。
中间部分是七猫大数据数仓的基础数据。上下两个分支分别是市场投放业务数据以及商业化业务数据。这两条业务线的数据特点是数据量非常大,实时性要求高,每秒钟可能产生几百万条数据。分别通过 Flink CDC 以及 Flink Connector 每五分钟聚合写入到 StarRocks 里,关联数仓的其它用户行为数据,为下游提供数据服务,满足业务看数和用数的需求。
除了市场投放以及商业化业务数据之外,还有其他八条业务线。所有的业务线都有用数看数的需求,要同时应对各个业务线的数据需求,必须要依靠工具的力量来提升数据的交付效率。所以我们将各条业务线的数据需求,抽象成公共的数据能力,统一的提供服务。几个比较典型的业务场景,如数据地图、自助指标分析,数据治理、AB实验等。对应地在数据资产管理平台里会提供元数据服务,统一指标库、成本核算等数据能力。
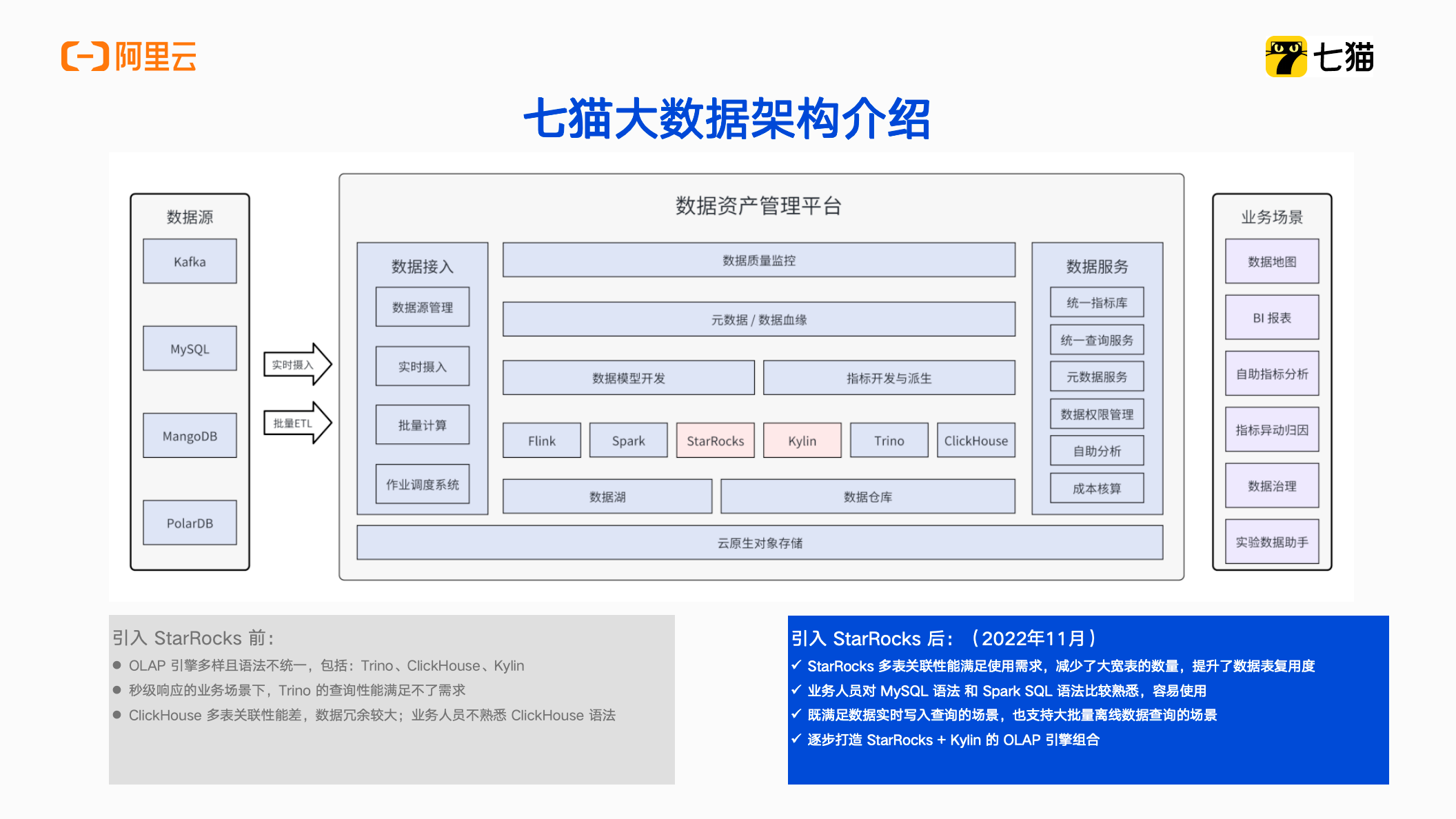
上图所示的模块,大部分都已经在生产环境使用了,只有小部分还在开发中。中间有一段是数据读写层。Flink 和 Spark 主要的功能是将数据写入到数仓中,然后 StarRocks、Kylin、Trino、ClickHouse 的主要功能是将数仓中的结果数据提供给业务线。由于历史原因,平台 OLAP 引擎多样且语法不统一,导致给数据开发和业务使用增加了门槛。所以在长期规划中,我们会逐步精简 OLAP 引擎,逐步打造基于 StarRocks + Kylin 的 OLAP 引擎,为业务数据提供统一支持。
阿里云EMR-StarRocks 在七猫的实践案例
通用人群圈选系统
通用人群圈选系统上线之前,我们数仓团队平均一周会接到2-3个用户圈选需求,系统上线之后则是平均2-3个月接到一个需求。为什么会出现这么大的变化呢?类比边缘计算的思路,边缘计算将云计算所需要完成的工作前置到终端来进行执行,从而减轻中心节点的负载和压力。同理,原先用户圈选需要由数仓同学才能够完成,现在则将这些工作前置到业务团队来完成。将圈选人群的工作下发到业务,业务同学只需要写一段 SQL 提交到系统,系统就会自动创建人群包。
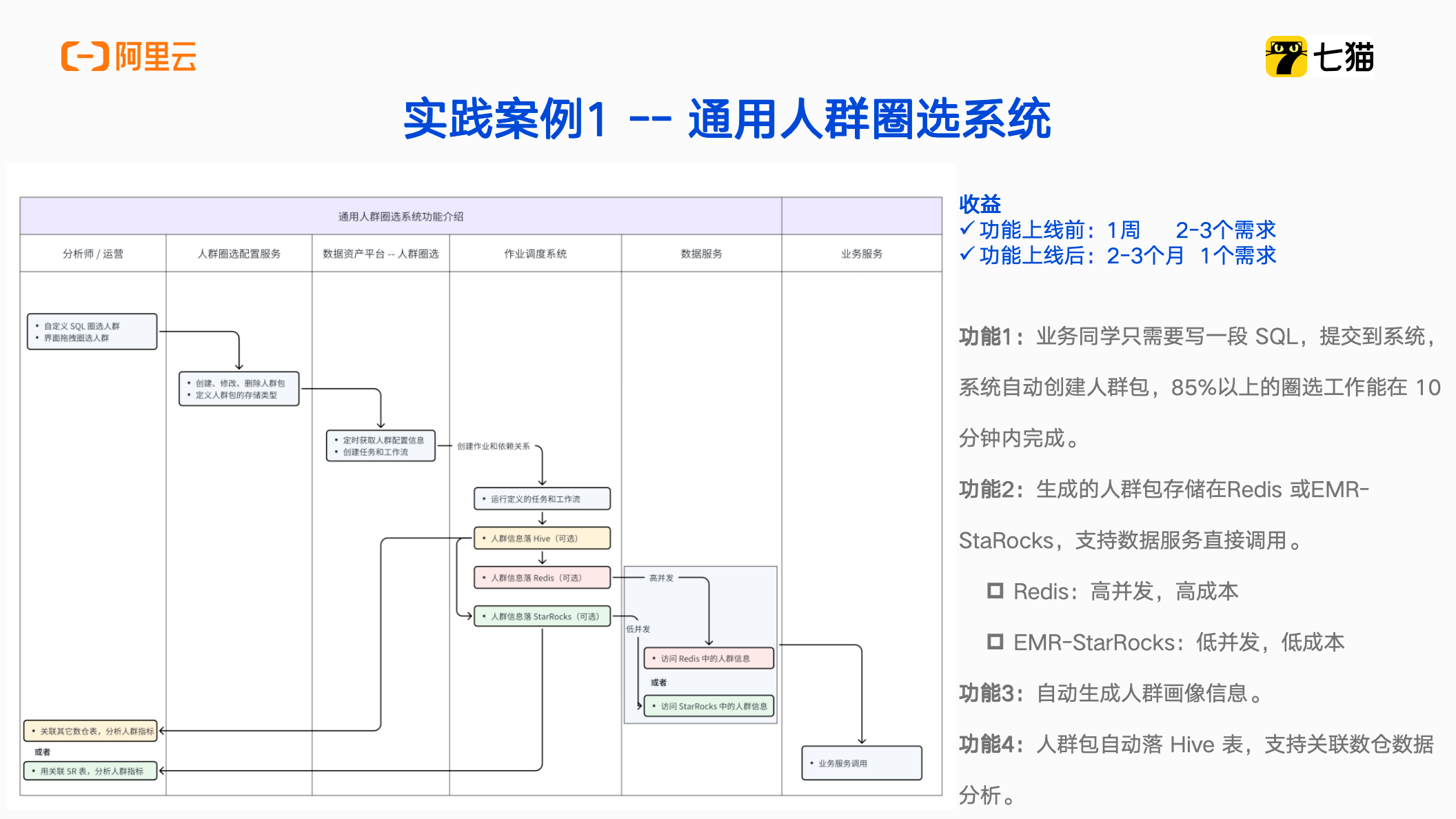
用户圈选系统的实现原理如上图所示,起点是分析师/运营通过自定义的 SQL 创建人群包,将人群配置信息注册到圈选系统上,数据资产管理平台的人群圈选的模块会定期读取配置信息,然后调用作业调度系统的API,自动生成圈选作业并定时调度,同时还会解决上下游依赖问题。
第一版用户圈选系统人群信息数据主要落在Redis,通过数据服务给到业务服务使用。因为业务服务针对不同人群有不同的策略及实验,同时考虑到离线数据分析部分的人群信息,也会自动落一份数据到 Hive 里,帮助分析师或者算法同学关联数仓的用户行为指标来进行分析。这部分可以了解人群建好一段时间之后的人群表现,并通过数据关联进行分析。由于 Redis 的使用成本比较高,遂引入了 StarRocks 。StarRocks 可以存储的数据量也比较大,相对 Redis 来说,整体使用成本比较低。作业调度系统中,StarRocks、Redis、Hive 都是可选的引擎,由业务同学自己决定。可以看到在整个流程中,数仓同学几乎没有露脸,实现业务同学玩转系统初衷。碰到疑难问题,再由数仓同学介入解决,节省了人力成本以支持更多业务需求。
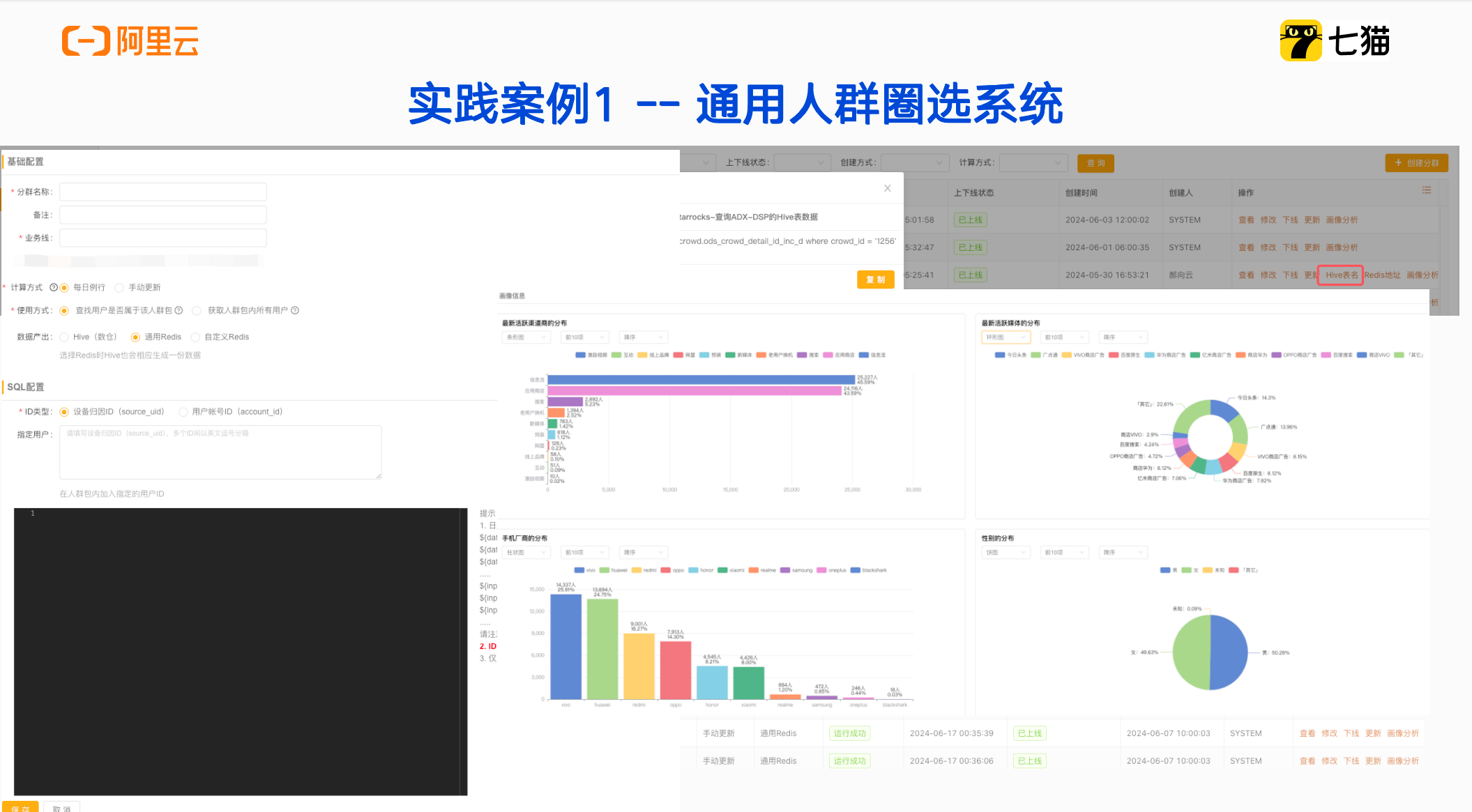
通用人群圈选系统截图
指标异动自动下钻探查
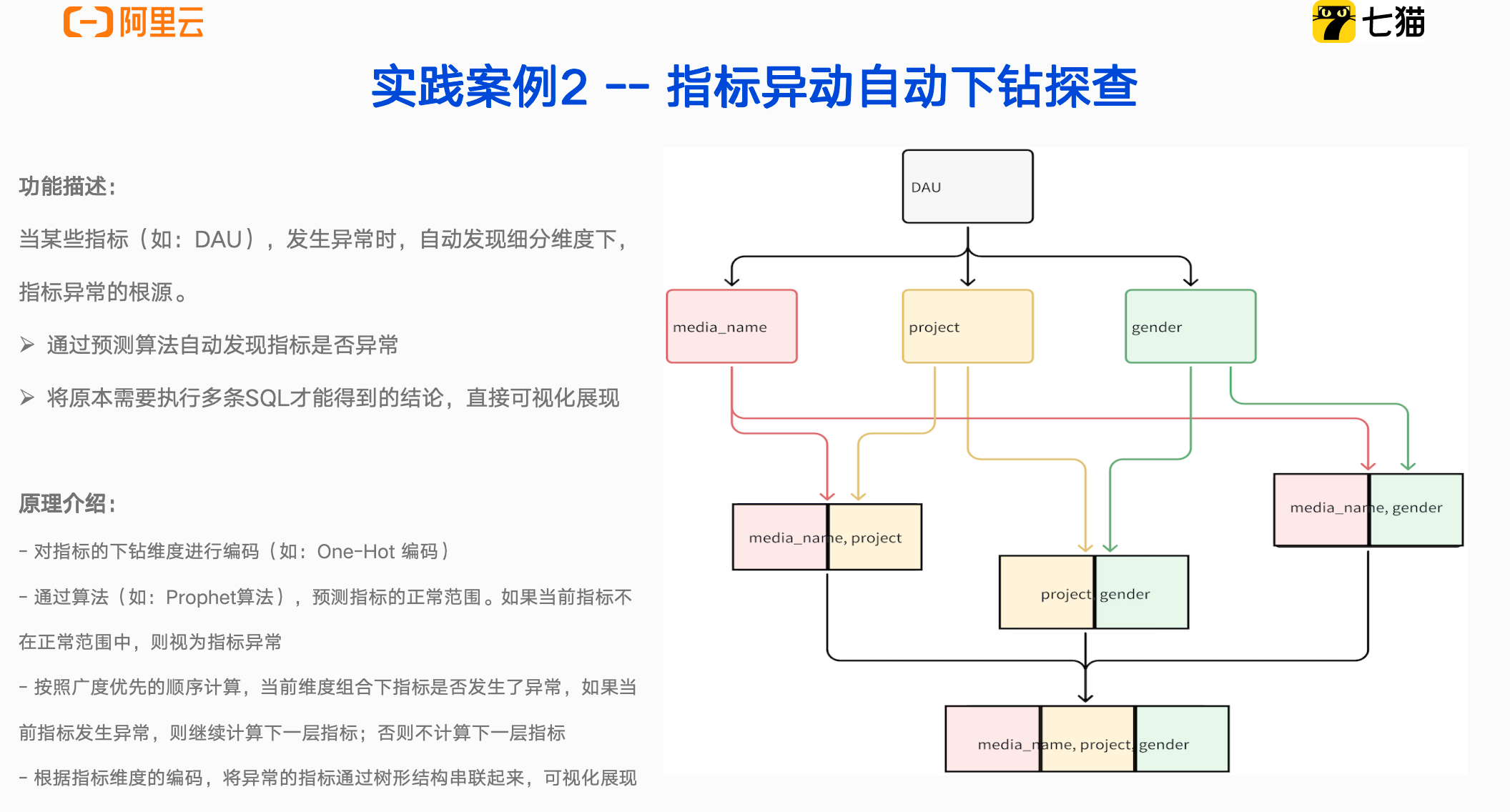
指标异动自动下钻探查是我们七猫数仓团队自研的功能,目前处于孵化阶段。由于还没有前端同学参与,界面稍显简陋,但因为功能强大,迫不及待跟大家分享。指标异动自动下钻探查功能,可以自动发现细分维度下,指标异常的根源,快速定位指标异动原因。

上图所示的所有节点都是指标,出现在这棵指标树上的都是异常指标。当指标出现异常如 DAU 上涨/下跌时,可以根据节点和节点之间的连接关系,一层一层下钻,找到最细维度组合下的指标异常,然后定位到负责该指标的业务同学,了解业务是否有变更,导致 DAU 波动。通过指标异动自动下钻探查功能,原本可能耗时半天的繁琐SQL查询,可以压缩至5分钟内获得洞察。
实现指标异动自动下钻探查功能,主要有两个关键技术点。第一个是如何判断指标是否异常;第二个是如何将异常指标连接展现。
异常指标判定:我们会通过预测算法,基于历史数据预测指标的正常范围。如果当前指标不在正常范围中,则视为指标异常。例如,通过分析过去数月的DAU趋势,确定当前DAU是否显著偏移预测区间。
异常指标串联展现:对指标的下钻维度进度编码,高效构建指标间的层级关系,实现从单一指标到多维度组合的逐级下钻分析,将异常的指标通过树形结构串联起来,然后进行可视化展现。
730 天微聚合数据灵活下钻分析
最近半年,七猫在提升用户标签的覆盖度和准确度方向做了很多工作,覆盖度和准确度提升的同时,也导致历史数据分析的连续性和准确性受到了干扰。如某用户从原识别为女性调整为男性,直接对比更新前后的数据可能导致误读,如看似女性用户阅读时长骤减而男性用户时长激增的现象,实则是归类调整的结果,并非真实行为变化。这对依赖于此类数据进行算法优化和业务决策的团队构成了严峻挑战,尤其是在面对大规模标签更新时,问题复杂度呈指数级增长,传统处理方式难以为继。
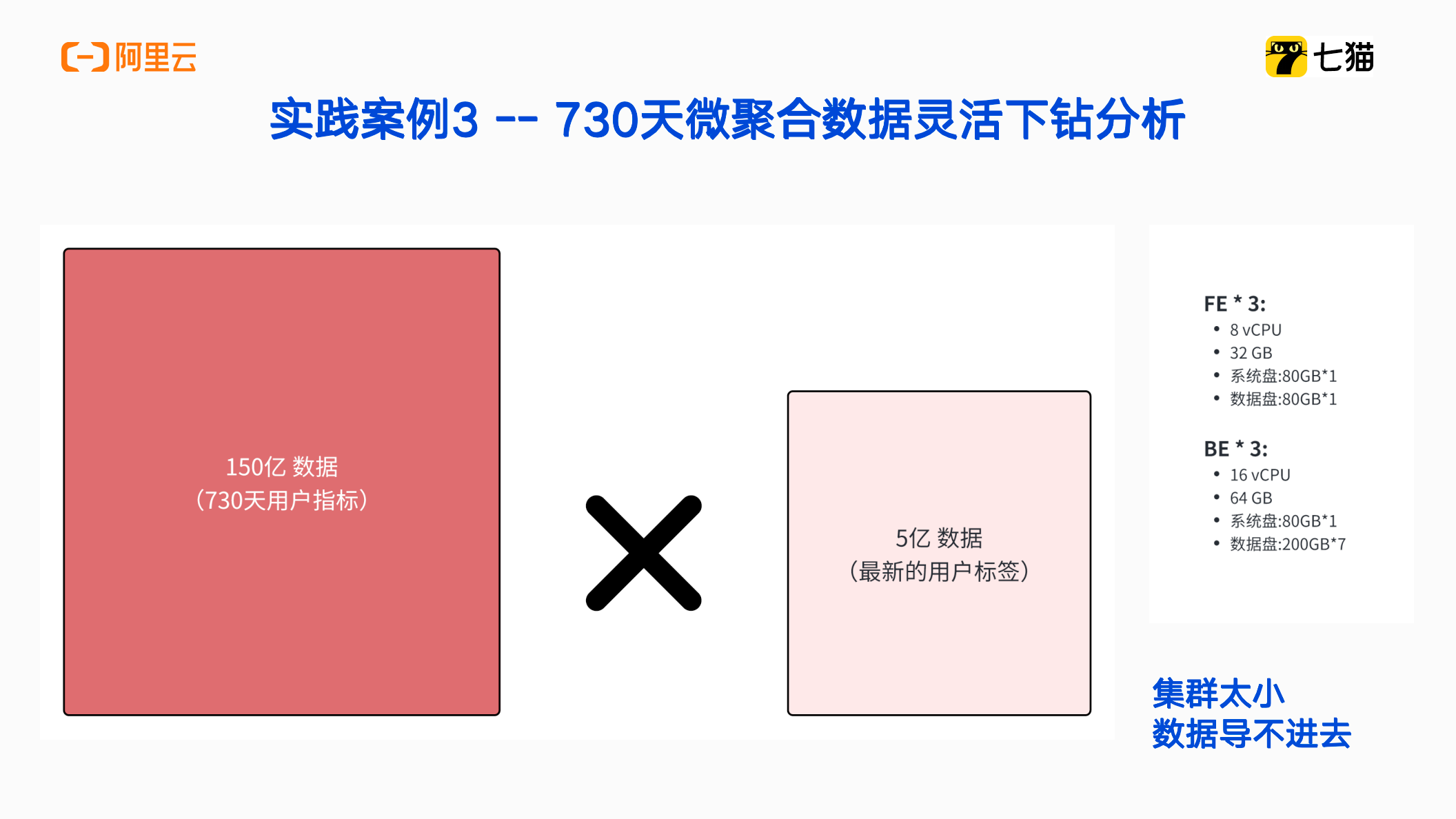
为应对这一难题,团队集思广益,提出了一项创新策略:每日采用最新用户标签重新计算过去730天的数据,以确保分析的一致性和时效性。然而,涉及约5亿用户、150亿指标数据,执行此策略面临的数据处理规模十分庞大,涉及的查询性能必然很差。此外,由于集群规模小,数据量庞大,数据甚至无法导入,增加节点,增大集群规模又会面临很高的成本问题。探索如采用bitmap编码优化存储与查询效率的方式,也因实施复杂度和沟通成本高而未能采纳。
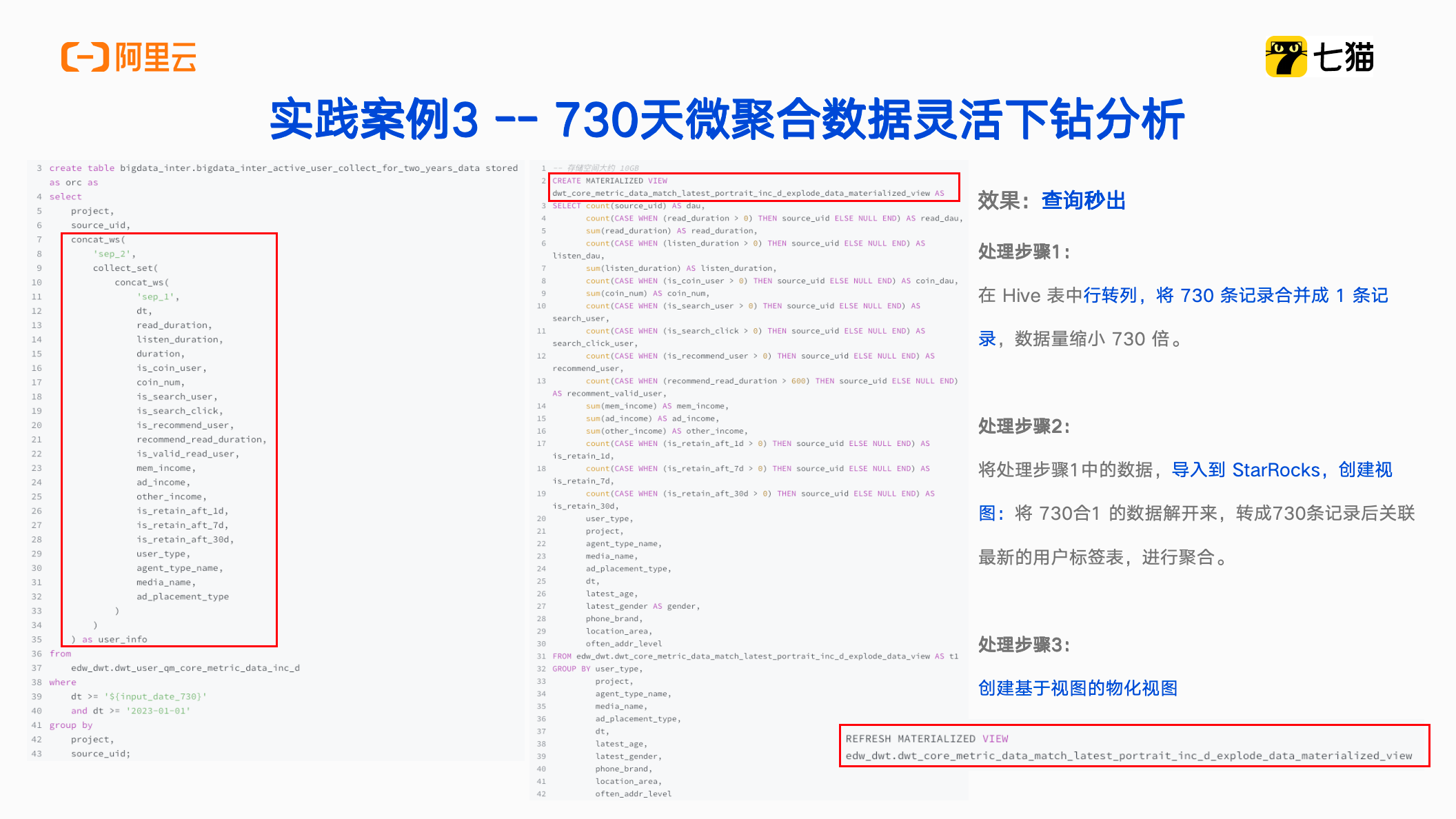
最终,通过一个StarRocks使用小技巧解决了这个问题,第一步是在 Hive 表中通过行转列,将730条记录合并成1条,再将缩小了730倍的数据导入到 StarRocks 中创建视图,导入之后将数据与最新的标签数据进行 join,再将指标按照业务要求的维度进行分组,最后创建基于视图的物化视图。每天只要 Refresh 物化视图,就能够达到指标查询加速的效果,实现查询秒出。经过一段时间的运行验证,系统稳定性良好,业务部门反馈积极,用户标签更新带来的问题成功解决。
未来展望
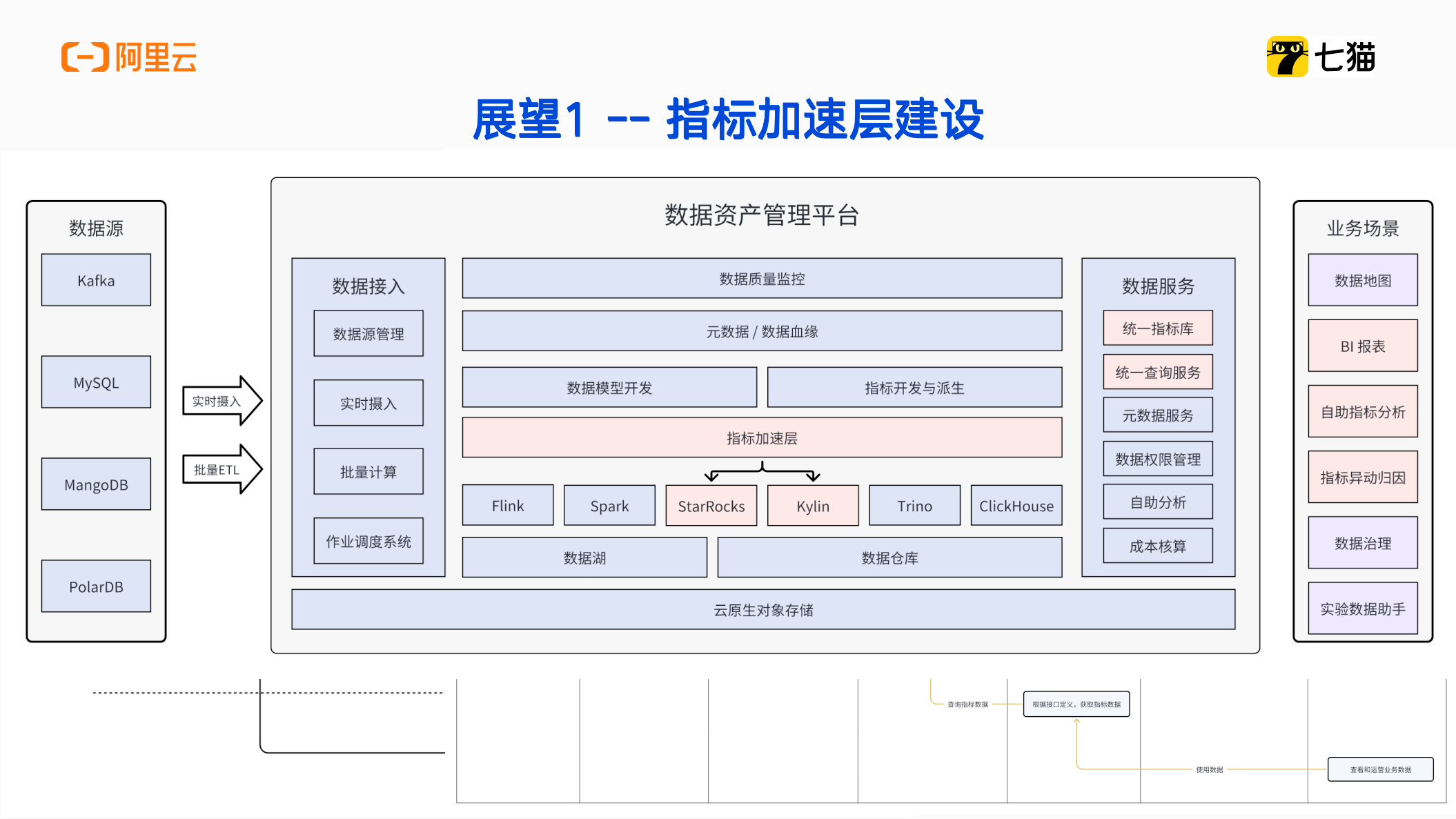
指标加速层建设
目前我们数仓团队在 Hive 里构建数据模型和指标后,还需人工同步数据至 StarRocks,手段在 BI 系统中创建数据集,以及手动在指标管理系统内进行登记注册。后续我们计划在数据资产管理平台建设指标加速层,核心 OLAP 引擎选用 StarRocks+ Kylin,数据开发人员仅需在指标管理系统中精准定义模型和指标,即可自动生成 BI 系统数据集,同时自动完成 StarRocks 与 Redis 中的数据加速处理。
埋点全链路数据治理
2024年3月我们启动了数据治理专项,截止到5月份,在数据量持续增长的情况下,完成了降本 70万元/月 的目标。主要涉及到的工作内容如下:
1、数据开发和治理规范
-
开发数据治理工具:自动识别需要治理的数据表和资源利用率低的任务,告警到个人。
-
开发黑名单功能:对长时间没有优化的数据表和任务,自动 Kill 。
2、存储治理
-
基于对象存储的归档能力,将访问频度低的分区数据进行分级归档(冷归档的存储成本大约是标准存储成本的 1/10)。
-
基于数据血缘能力,将出度和入度较小的数据表下线,用其它热度较高数据表代替。
3、计算资源治理
-
基于 Spark 集群的弹性扩缩容的能力,减少常驻 Spark 节点数。
-
通过 YARN 资源的监控,对 Spark 任务进行编排,减少弹性扩容的 Spark 节点数。

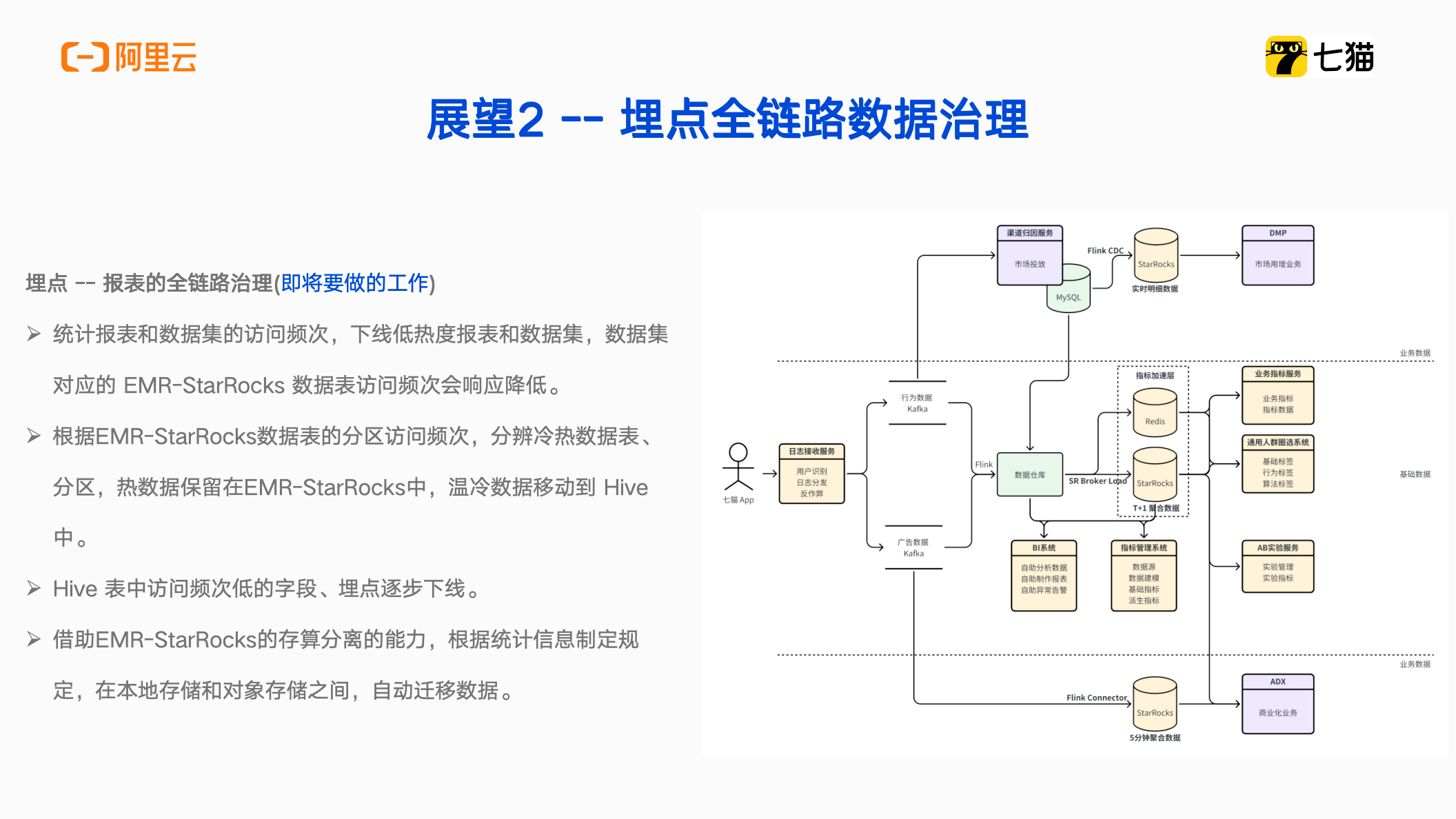
值得注意的是,目前的数据治理实践主要围绕数仓内的表与任务展开,尚未覆盖至 StarRocks 。所以接下来我们计划进行面向埋点的全链路数据治理:
-
统计报表和数据集的访问频次,下线低热度报表和数据集,数据集对应的 EMR StarRocks 数据表访问频次会响应降低;
-
根据 EMR StarRocks 数据表的分区访问频次,分辨冷热数据表、分区,热数据保留在EMR-StarRocks中,温冷数据移动到 Hive 中;
-
Hive 表中访问频次低的字段、埋点逐步下线;
-
借助EMR-StarRocks的存算分离的能力,根据统计信息制定规定,在本地存储和对象存储之间,自动迁移数据。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









