







介绍
相当于一本书中的目录,优化查询(select,update,delete)
索引类型
BTREE
RTREE
HASH
FTEXT
BTREE
b-tree
数据结构,是一棵平衡树.根节点,枝节点,叶子节点
适合范围查找(mysql大多数都是范围查找),查找每个值的高度都一样.
每个节点都是一个16kb的页.
b+tree
在叶子节点加入了双向指针.
在查询的数据在叶子节点部分十多个数据页的数据时,可以通过叶子节点的指针,跳到下一个数据页,可以减少数据页的读取(减少IO).
优化一条SQL(1.sql语句优化,2减少IO)
MySQL如何应用btree?
聚簇索引
innodb中必有主键
mysql的数据进行数据行的插入的时候是按照聚簇索引进行的.
组织和存储表的数据行.聚簇索引组织存储表.
簇:区64个数据页.
1.构建前提
PK
UK not null
rowID
2. 构建细节
分配物理上连续的一簇空间.连续空间IO效率高一点.
这一个区内就会逻辑上连续的数据在物理存储上也是连续的
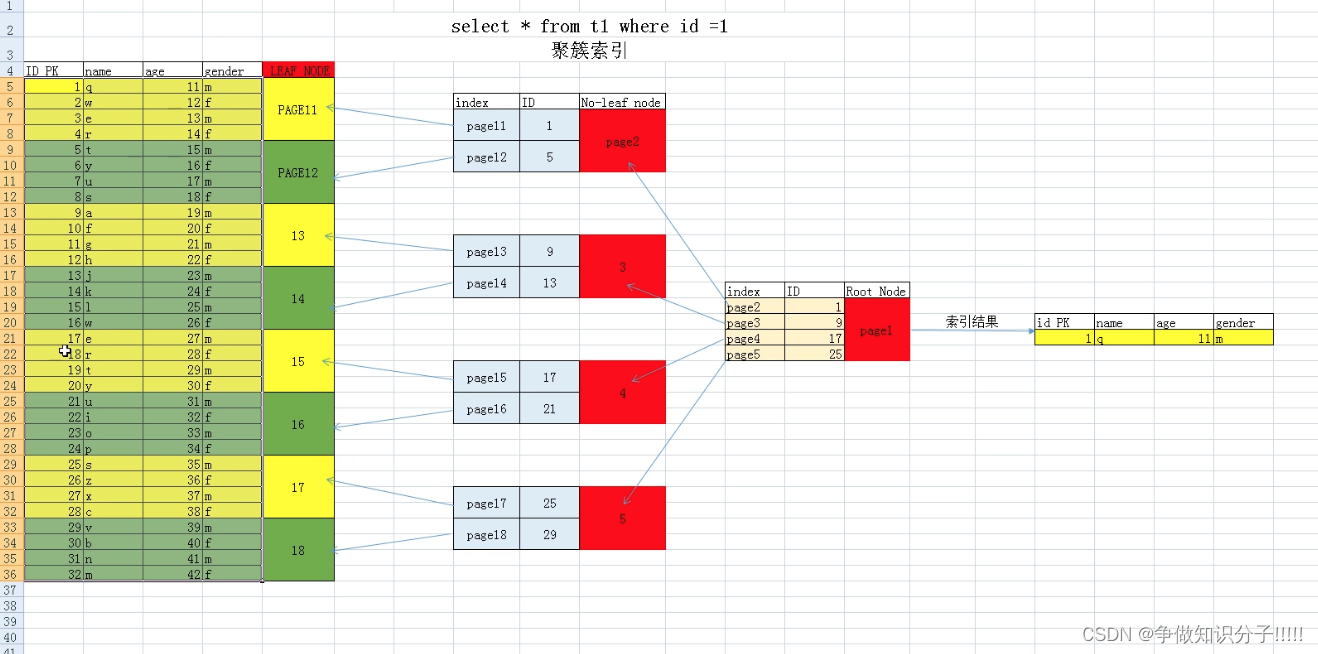
如图,数据的存储是在64个连续的数据页上的.
进行查询时:(1)进行聚簇索引—根节点—枝节点—叶子节点----得到数据页(mysql最小的IO单位是page)—拿到内存—SQL层将数据拆开拿到结果.
快速锁定数据范围.------非常适合于范围查找
叶子节点(leaf): 在录入数据时,会按照聚簇索引逻辑顺序,存储到物理上连续的多个数据页,从而构成了叶子节点.并且存储相邻叶子节点的双向指针.(存储了整表数据)
枝节点(no_leaf): 选取叶子节点的ID的范围+指针.
根节点: no_leaf节点的ID范围+指针
3.优化效果
通过ID列作为查询条件,会起到优化效果.
辅助索引
当要查询name字段时,将name设置为辅助索引,此时会拿出id列和name列,按照name进行排序,根据name构成一棵辅助索引树.根据name查找到对应的数据页,数据页中的id.拿到id进行回表,进行聚簇索引.
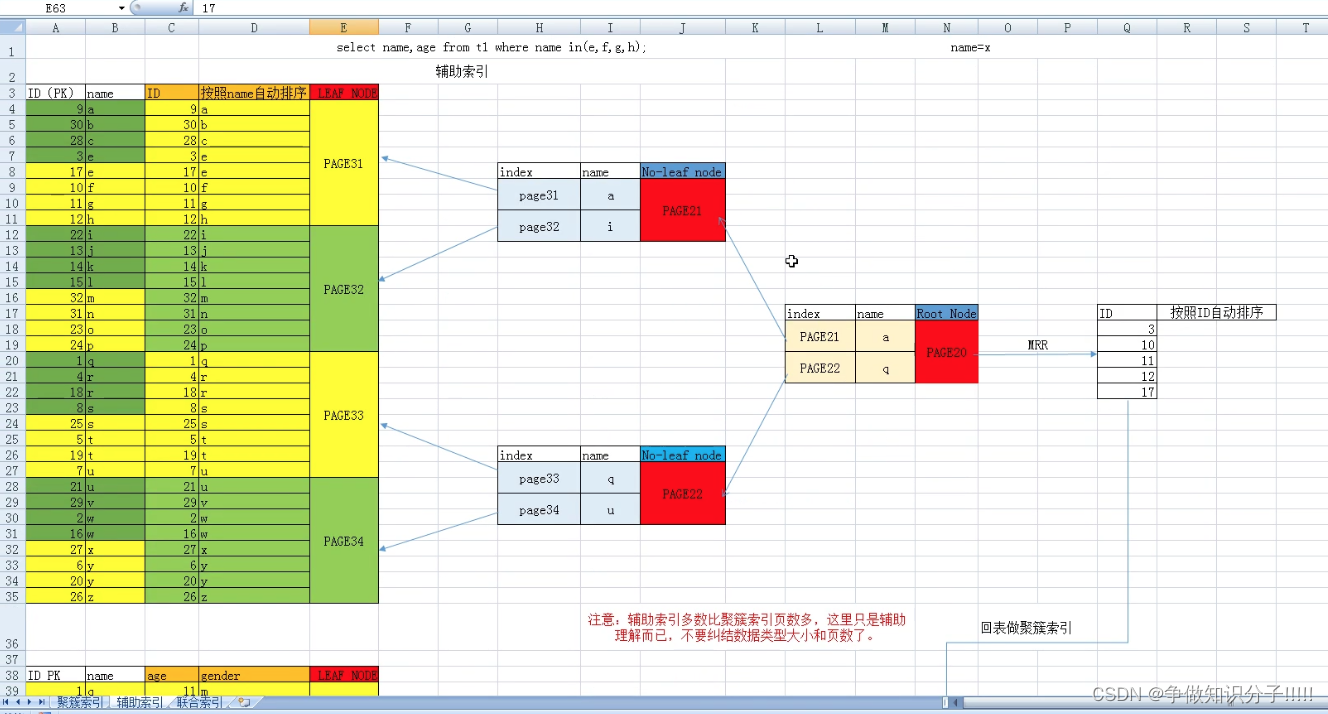
回表:
根据得到的id进行聚簇索引.
开发中,建表必然有主键聚簇索引.辅助索引需要人为创建
1.如何生成:
叶子节点:将索引列值+ID值取出,按照索引排序(默认从小到大)均匀的存储到连续的数据页上.
非叶子节点:保存了叶子节点索引列范围+指针
根节点:保存非叶子节点的范围+指针
2. 如何进行查询优化
3. 当按照索引列作为查询条件时.
(1)扫描辅助索引,找到叶子节点,从而获取到条件值对应的ID
(2)根据ID回到聚簇索引扫描得到叶子节点.
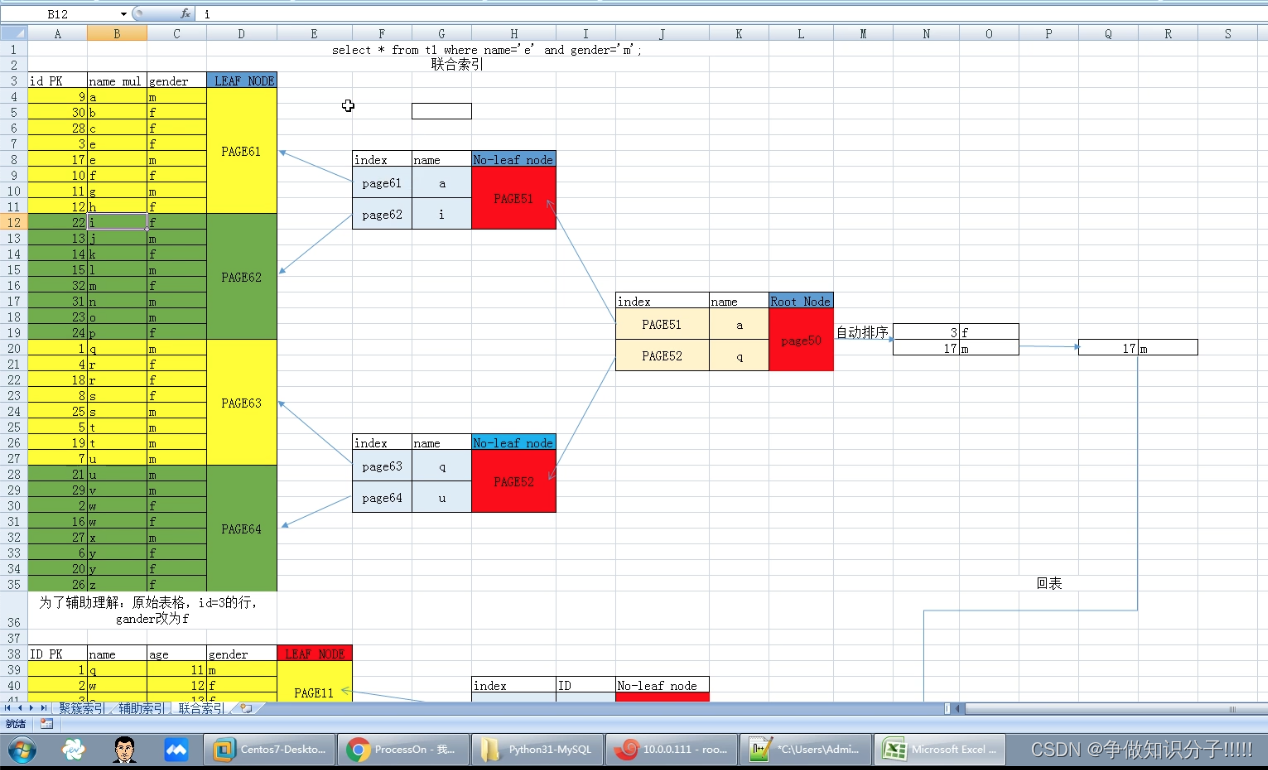
联合索引(辅助索引)
select * from t1 where name=‘x’ and gender=‘F’;
联合索引结构:
将name和gender作为副主索引idx(name,gender)进行排序.将最左列作为范围条件进行构建树.第二个条件(SQL层)在取到数据页之后才进行过滤.
联合索引的最左原则:
(1)使用基数大的列作为最左列
(2)查询条件中必须包含最左列条件.
前缀索引:将字段的前x个作为索引
索引树高度
三层高度可以支撑两千万的数据
最高不要超过4层.
影响因素:
(1)数据量
分区表,定期归档数据,分库分表.
(2)索引列值长度
前缀索引
(3)主键过长,辅助索引树高度会受影响
数字自增
(4)数据类型选择用varchar不要用char
合适的简短的
关于回表
介绍
扫描完辅助索引后,再回到聚簇索引扫描的过程.
带来什么影响?
回表的次数,如果辅助索引得到的id很多,需要回表很多次
IOPS:每秒最多可以发生的IO次数
IO吞吐
随机IO:辅助索引到聚簇索引进行的是随机的
如何减少
不回表.
覆盖索引:
1.联合索引中包含大部分或者全部的查询条件(苛刻)
select id,name from t1 where name=‘x’,不需要回表查询其他的数据.
2.通过联合索引,尽可能覆盖到大部分的查询条件;(得到的id值越少回表的次数越少)
索引的命令管理
#索引的查询
desc t1;
show index from t1
# 创建索引
alter table t1 add index i_n(name);
alter table t1 add index i_abc(a,b,c); 联合索引
alter table t1 add index i_bigcol(bigcol(20)); 前缀索引
alter table t1 add unique key uni_tel(telnum); 唯一索引
# 删除索引
alter table t1 drop index i_n;
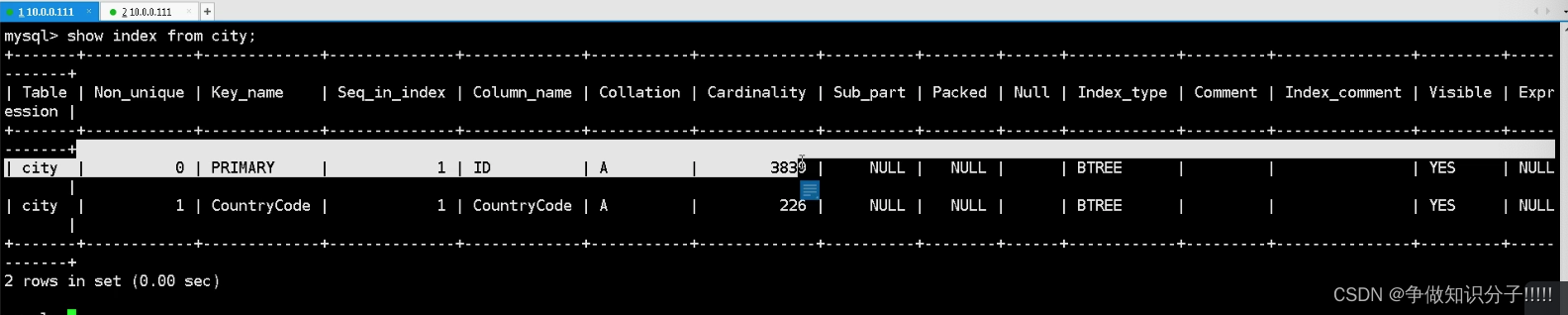
cardinality:基数
执行计划分析
1.是什么?
优化器优化后的执行计划
2.作用?
(1)上线新的查询业务之前
(2)分析慢语句
3.抓取执行计划
desc select * from t1 where k1='zz' limit 10;
或者
explain select * from t1 where k1='zz' limit 10
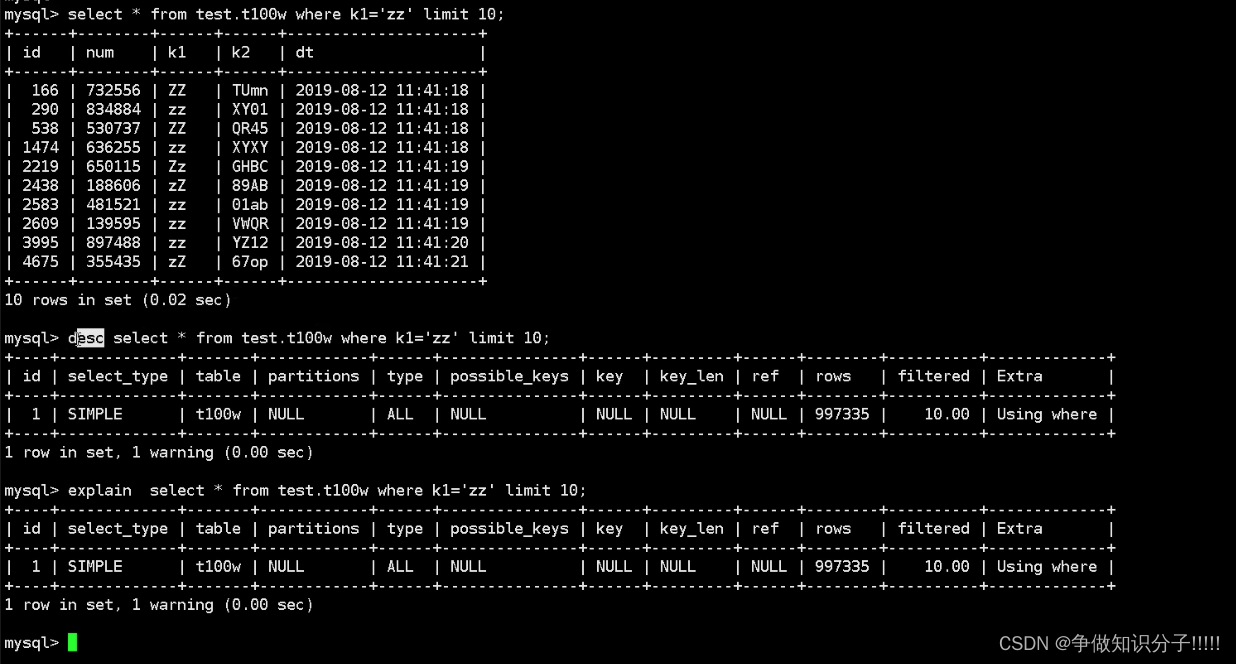
主要针对于索引进行优化.
4.分析执行计划
(1)type:
ALL: 全表扫描
没查询条件,查询条件没建索引,
INDEX: 全索引扫描(全索引树都扫描,查询条件太大)
以下业务上可以容忍:
RANGE: 索引范围扫描(where id<10; where ch like ‘CH%’)<,>,<=,>=,like, in(可以优化), or
使用in时这个查询是范围查询,就会筛选出过多的数据再进行过滤
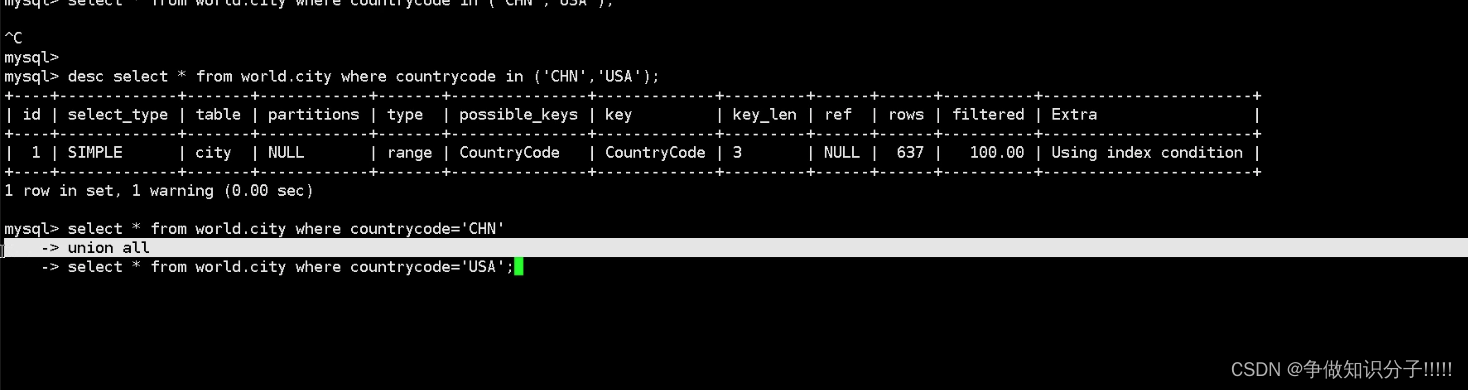
修改之后:
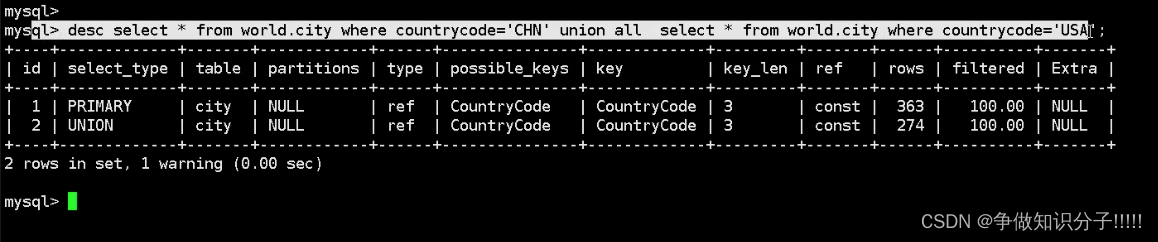
REF : 辅助索引等值
EQ_REF: 非驱动表的关联条件是主键或唯一键等值查询
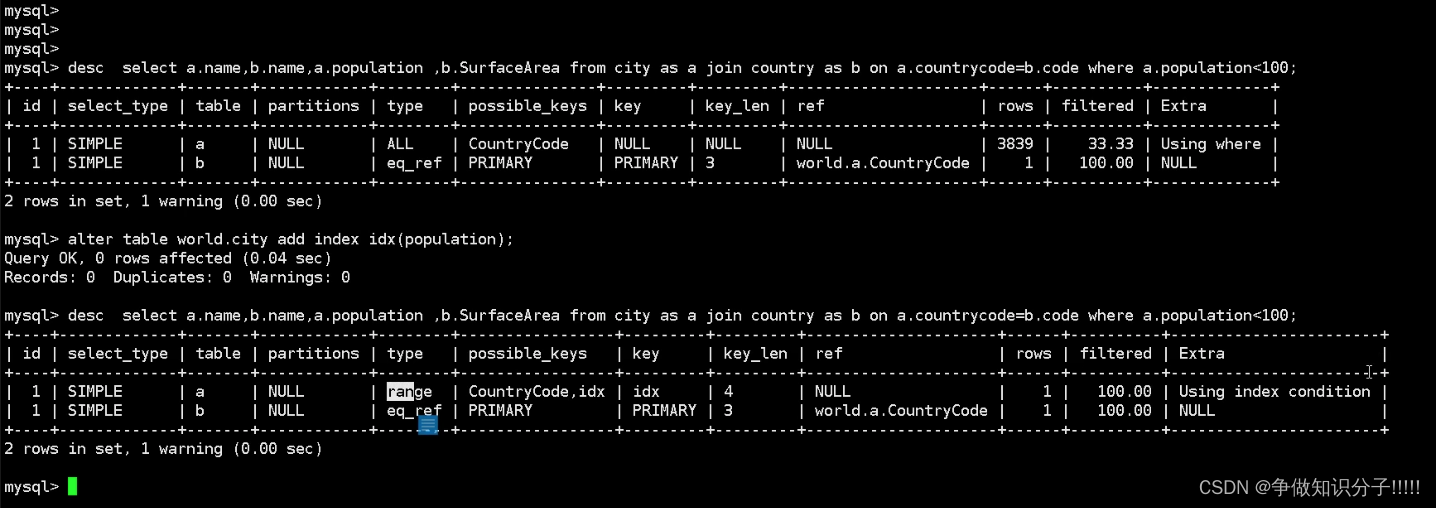
CONST(SYSTEM): 主键或唯一键等值查询
(2)key_len:索引的覆盖程度.
在查询条件中,所有列能够应用到的索引最大预留长度加和.
idx(a,b,c)
explain select * from t1 where a= b= and c= ;
key_len = a+b+c
影响列的最大预留长度的因素:
a. not null
没有not null,最大预留长度 +1
b.字符集
utf8mb4 4
utf8 3
c. 数据类型影响
varchar —>1-1字节存储字符长度 +2

查询条件用到哪个就加哪个
越长越好,回表次数越少.
idx(a,b,c)索引,哪些查询条件可以完全覆盖,哪些是部分,哪些是完全不覆盖.
a. 完全
where a= and b= and c= ;顺序调整也可以覆盖到.
where a = and b= and c>
where a= order by b,c,d;(key_len没算,但也用到了,不需再额外排序)
b.部分覆盖
c.不覆盖
查询中不带有最左列的查询.
(3)Extra
using filesort----->查询中 order_by group_by distinct
用了额外的排序.可以对排序的字段建联合索引
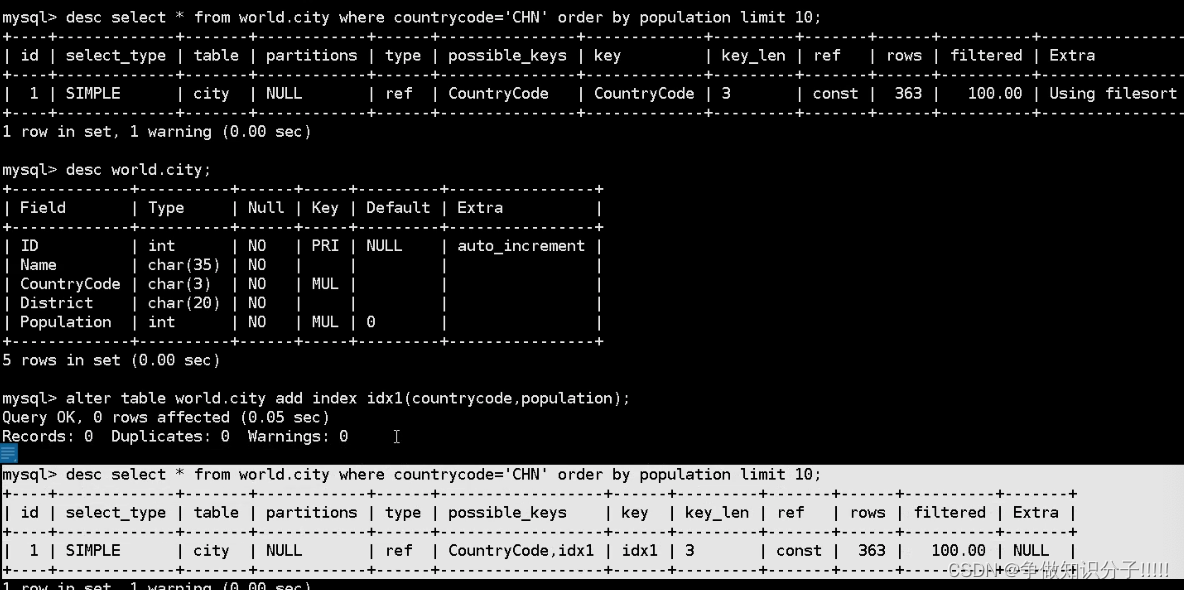
如何查询冗余和无用索引
index(a,b,c) a,ab,abc
大量索引的维护开销.
数据库中有两个表可以查询到从来没有使用过得索引.
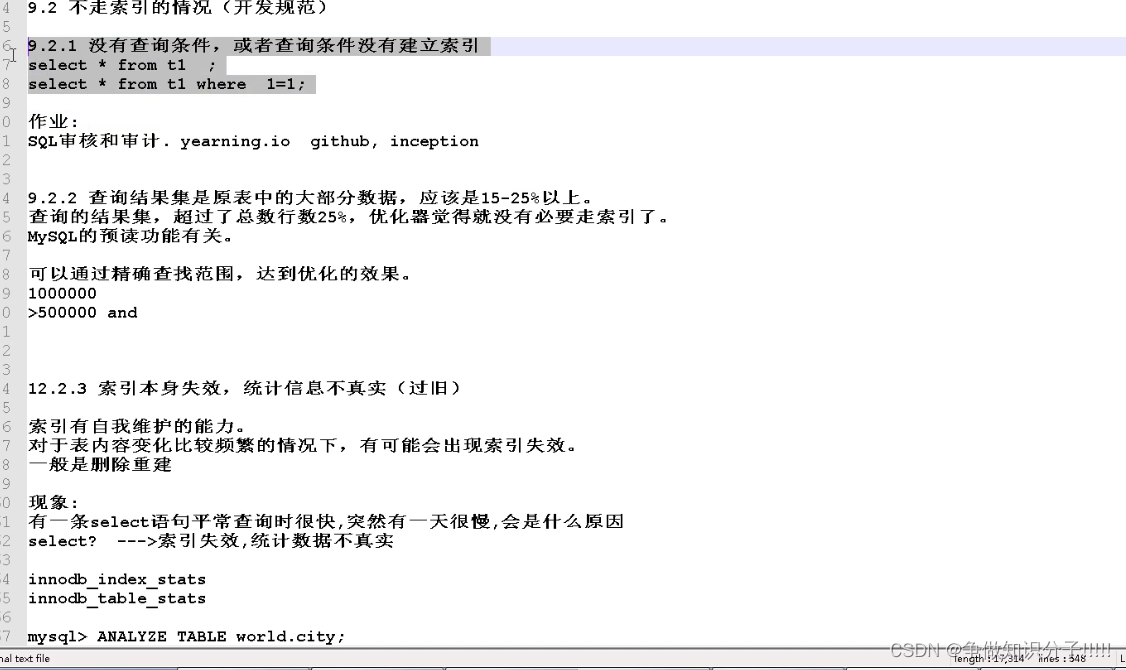
索引应用规范

下:














 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









