







JS高级使用2.0——JS中闭包的理解
创作场景
一道面试题把我打败了,其实我就是想弄懂那道面试题怎么个事儿,虽然写完这篇博客也有可能弄不懂吧,请看:
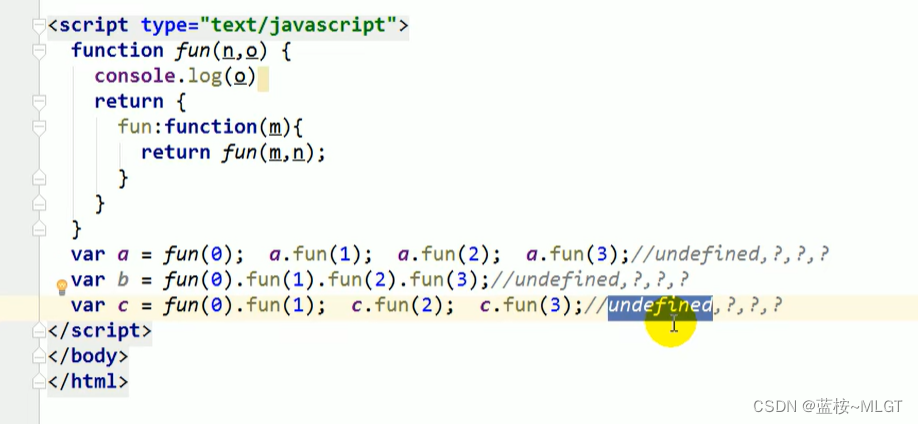
这是某谷课程的上面的一道面试题,说实话有点东西的,整得我又回头看了一遍课程,以此记录一下。
阅读前提
需要对js有一定理解和熟悉,因为实在是有点抽象,这里我引用一句话,说不定大家有点兴趣:手上没炮和有炮不用是两码事,我们可以不用闭包,但是我们不能不懂。(其实吧,我们开发中一直在用,就是不知道这东西叫闭包)
了解闭包前需要知道的三个知识点
1.0 函数的作用域
函数的作用域可以简单理解为一块空间,也就是函数执行所需要的内存,一般函数执行肯定要操作变量,变量就是优先在这个函数的作用域寻找的,如果找不到就会向父级找,这几乎是所有语言都具有的特性(衍生一下:班主任解决不了的问题找谁,教导主任啊,难不成找班长啊)。
var name = "window";
function fn() {
var name = "fn";
console.log(name) // 必然是输出fn
}
fn()
注意哈,函数中定义的变量,只能在函数中或者函数的子函数,也就是下级作用域使用,不能以下犯上,这个规则官方点就叫作用域链。
2.0 函数的执行机制
说执行机制前先介绍两个概念,一个是变量提升,一个是函数提升。这两个概念就是说在我们代码执行之前,有一个过程叫预解析,会提前申明一些东西。
console.log("-----------------变量提升-----------------")
var a = 3;
function funA() {
console.log("变量提升funA", a)
var a = 4;
}
funA()
请问输出的是3还是4呢?答案是undefined。
这就是变量提升的概念,代码在执行前会优先将函数外的所有变量进行提升,也就是提前定义,但是不赋值,在执行过程中进行赋值,在这个例子中,执行funA时,因为函数中有一个赋值语句var a = 4,在函数开始执行前,也会进行变量提升,实际上就是下面这段代码。
var b = 3;
function funB() {
var b;
console.log("变量提升funB", b)
b = 4;
}
funB()
上面说了,如果函数中没有变量才会去上级找,现在有,所以就直接输出undefined喽。
其实函数提升和变量提升是一样的,如果是申明了一个函数,在执行前就已经挂载到window对象了,只是没有执行,但并不是没有定义。
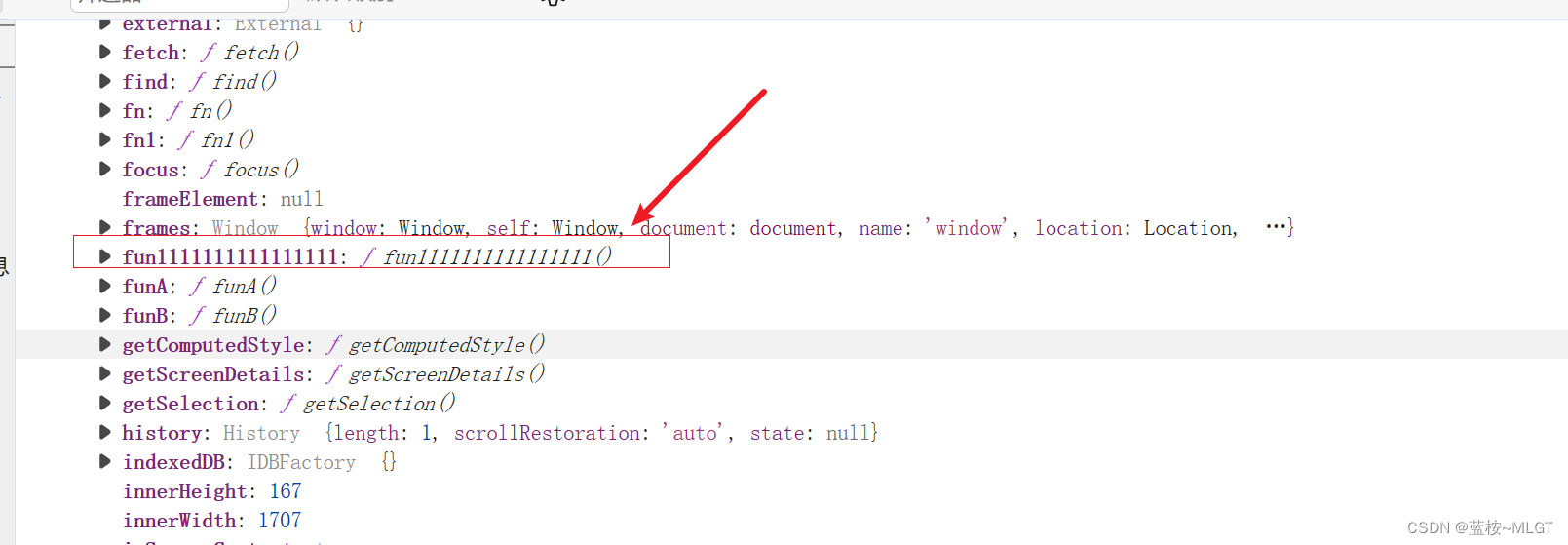
console.log("-----------------函数提升-----------------")
console.log("window", window)
fun1111111111111111()
function fun1111111111111111() {
console.log("Hello World")
}
这种代码经常写吧,无论函数定义在执行前后都可以调用,因为执行前就在window中了。
OK,回归到我们的函数执行机制。
函数的特性是,执行结束后,会释放那一段内存,包括内存中使用的变量,其实这就是函数的执行机制,放到内存中就是说,有一个栈空间,函数先压入到栈里面,执行完立马就释放了。但是有一种函数不会立即释放,就是我们今天要说的,闭包。
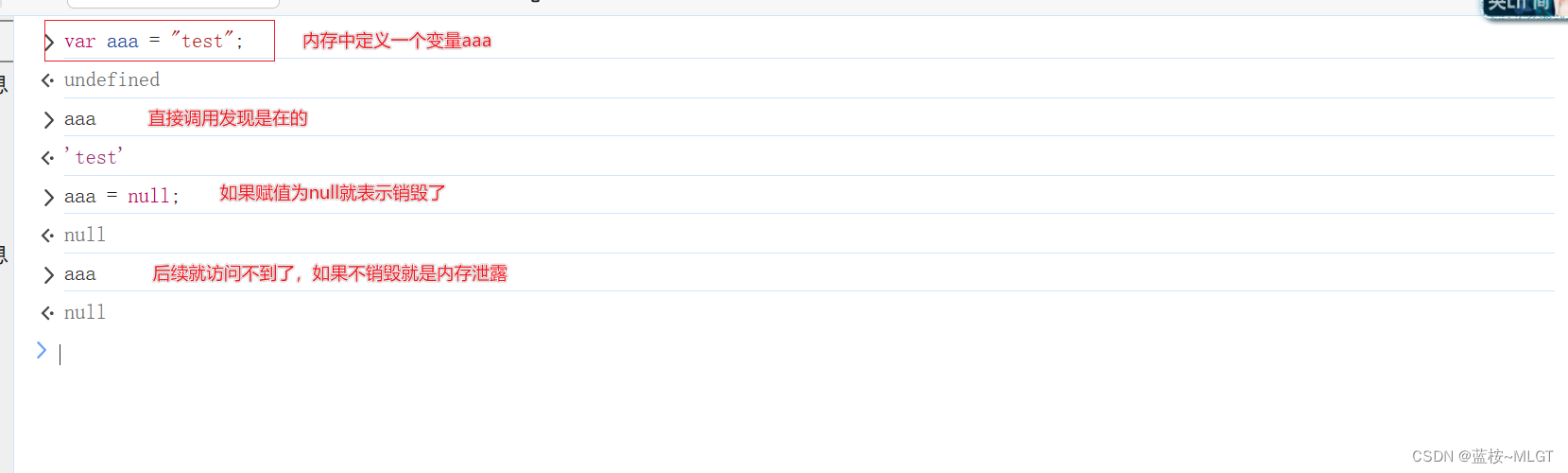
3.0 内存泄露
很简单,我们使用的变量没有及时销毁,一直存在于内存中,久而久之就造成了内存过大甚至奔溃,这就是内存泄露。
闭包的理解
1. 闭包的定义
闭包有两种看法,大多数人也是官方介绍的定义是:
闭包是有权限访问其他函数作用域的局部变量的一个函数!
当然也有一部分人认为是被引用的函数或者对象,本文还是针对上面的进行介绍。
2. 闭包产生的条件
- 函数嵌套
- 内部函数引用了外部函数的变量或函数
3. 闭包是怎么产生的
当一个嵌套的内部函数引用了外部或者是父的函数或者变量,就产生了闭包。
根据例子介绍一下
function fn() { // 外部函数
var a = 520;
function sonFun() { // 嵌套函数
console.log(a) // 引用了外部函数的a变量
}
sonFun()
}
fn()
上面这个例子比较清晰的说明了一个闭包的产生,sonFun的内部函数引用了外部函数fn的变量a,按照我们的第一个定义,sonFun就是一个闭包。在浏览器中可以这么看:

有一点大家要注意,上图说明了一个问题,闭包在
外部函数开始执行的时候就已经产生了,不是说执行内部函数的时候,执行相当于是一个全新的上下文。
为什么说在外部函数开始执行的时候就产生闭包呢?还记得上面说的
函数提升的概念吗?函数在执行前,会将当前(不包含子函数)用到的变量和函数进行提前定义。

事实证明,这确实是一个简单的闭包。
闭包的特性
闭包的特性有两个,一个是我们刚说的内部函数可以引用外部函数的变量,一个是不会被垃圾回收机制回收。
特性一:内部函数可以引用外部函数的变量
有的人可能会想,纠结这个干嘛,开发中经常使用,谁都知道,但是吧,这确实是闭包的一个特性,因为函数在执行的时候正常来说只能引用全局的变量,不能引用其它函数的变量,是闭包带给了我们这个特性。
特性二:引用的变量不会被垃圾回收机制回收
在开始有一张图说的是变量什么时候被销毁,当变量赋值为null的时候就被销毁,那函数的特性是执行结束后会回收所有的内存,包括变量,但是闭包不一样,它不会被回收,一直存在于内存中,用一个例子说明一下。
console.log("-------------------------")
function fn1() {
var a = 1;
function fn2() {
a += 1
console.log(a)
}
return fn2
}
var f = fn1()
f()
f()

上面的例子是定义了一个外部函数,函数的返回值是一个闭包,按照正常来说,无论一个函数执行多少次,a的值就是2,因为每次执行都有一个新的上下文,但是这是闭包,闭包中引用的变量是不会被销毁的,所以执行两次结果就是2.
这里有一种说法,实际上的a被销毁的,但是销毁的是a的key,但是value还是在内存中(你可以摧毁我的肉体,但是摧毁不了我的灵魂),所以继续执行还是会累加的。
再和大家说一个浏览器debug小知识,如何快速定位一个内部函数是在哪里执行的。
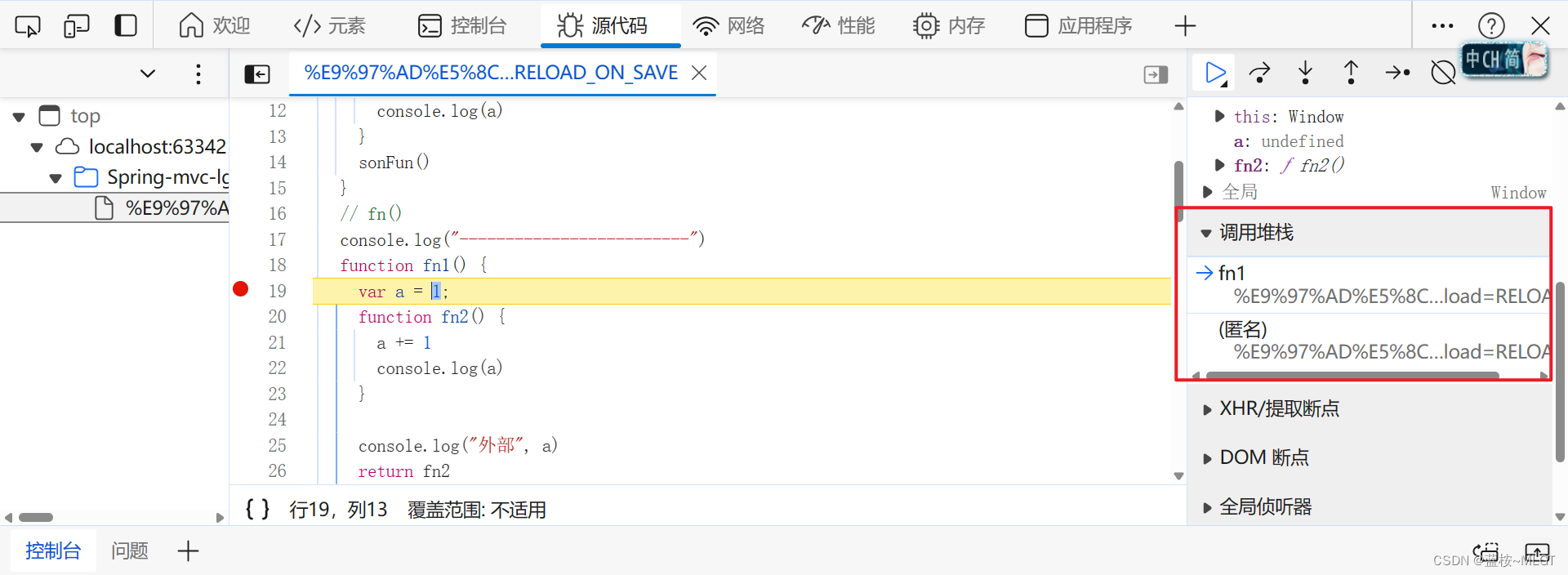
调试工具中有一个调用堆栈,这里就是函数的调用顺序,最下面就是你当前执行函数的调用函数,也就是第一个执行的函数,你可以理解为函数栈,一个一个往下压,最先执行的就在最下面。
面试题讲解(可跳过)
先说一下这个面试题,后面根据工作场景聊一聊闭包的实际使用。
1 function fun(n,o) {
2 console.log(o)
3 return {
4 fun: function(m){
5 return fun(m,n)
6 }
7 }
8 }
// 第一种
// 注意:首先执行了一次fun函数,参数为0,也就是对应变量n,所以第一次输出位undefined
// 但是返回了一个对象,对象中有一个函数,这个函数暂且看为闭包,闭包的参数此时已经确定为undefined
// 内部函数返回了一个函数的执行结果,也就是外部的fun,且不看返回了什么,此时第五行执行的函数
// 参数就已经确定为n了,n在第一次执行的时候为0,因为闭包引用了外部函数的变量,
// 虽然外部函数fun执行结束了,但是闭包依旧存在,也就是说第五行的参数n是存在的
var a = fun(0)
// 下面执行了三次函数,都是用a调用的,a还是最开始那个闭包,所以每次输出的结果都是0
// 但是每次执行都会产生一个新的闭包,因为执行的就是外部的函数
// 只是说这个闭包产生后我们没有用变量存储,也没有使用,所以产生后就消失了
// 注意:产生了新的闭包,只是我们没有存储和使用,这是重点!!!
a.fun(1)
a.fun(2)
a.fun(3)
// 第二种---------------------------------------------------------------------------
var b = fun(0).fun(1).fun(2).fun(3)
// 这个和上面的执行流程不一样的在哪,每次执行函数后产生的闭包我使用了
// 当fun(0)执行结束,输出undefined,返回的闭包中参数n是0,闭包就是上面的a
// 那么用新的闭包(是一个对象,对象中有一个函数fun)继续调用函数,参数为1
// 所以新的闭包中参数n对应的值就变为了1,所以输出1,以此类推
// 第三种---------------------------------------------------------------------------
var c = fun(0).fun(1)
c.fun(2)
c.fun(3)
// 第一行好理解,和第一个例子一样,输出undefined和0,
// 重点是执行结束后将结果保存到了c变量中,c变量中对应的参数n的值是1
// 用c调用之后的fun函数,参数值是不会变得,因为闭包没有变,闭包中的值没有销毁,虽然新的闭包一直在产生
简单唠一唠这个面试题,其实找到规律后确实不难,这是一道比较难得面试题,如果有想要钻研的伙伴可以看看,只要理解其实不难,不用担心这道题的我说的不对,这是某谷的老师讲的,我也只是听完后总结了一下,只能说很有收获,算是彻底弄懂了闭包是什么。
闭包的实际应用
1. 自执行函数(常用)
函数一般在定义结束后需要手动触发,平常写法就是定义完写一行调用它,而自执行函数不需要我们再写一行调用的步骤(但还是得调用,只不过用闭包实现了),这是开发中非常常用的手段。
!(function () {
var test = "Hello World"
function fn() {
console.log(test)
}
fn()
// 这里只是例子,真实情况会定义很多函数然后返回
})()
这种写法可以在页面加载时自动执行里面的内容,那么有的人就说了,我定义一个init函数,调用一下不就成了吗?nonono
其一:
不够优雅。
其二:
避免命名冲突,也就是不会污染全局的命名空间。
比如我去维护别人的代码,代码量很大,他在全局定义了一个findUser函数,参数是userID,然后我有个类似的需求,只不过是通过postId(岗位Id)寻找员工,定义的函数也叫findUser,只不过参数不同,这样不就命名冲突了吗?
不要小瞧这个作用,开发中函数的命名都是很规范的,相同的函数名非常常见,一不小心就会有变量和函数命名冲突的现象,毕竟js可没有Java的方法重载。
其三:
模块化,增加代码的可读性,代码更加容易维护
模块化是开发中比较常见的,将各个功能模块化,使用和维护都很方便。
(function($, w) {
// 用于jQuery的扩展,比如定义一些常用的方法挂载到$上,后面就可以直接$.fun使用
})(jQuery, window);
这是一种传参的写法,如果需要参数可以丢在里面。
2. 节流和防抖函数(常用)
节流函数
节流函数通俗讲就是在一定时间内限制函数的执行次数,当一个函数频繁执行的时候,不限制可能会造成意想不到的bug,同时也会浪费内存。
通常用于onscroll、onresize、touchmove、mousemove等,也就是监听你的鼠标移动位置,移动到指位置就执行什么操作,或者说页面滚动到一定位置执行什么操作,如果不加节流函数,可能你几秒钟函数就会执行上千次,假如函数操作比较复杂,还可能造成页面奔溃。
介绍两种方式实现节流函数。
- 用时间戳实现
function throttle(func, wait){
let previous = 0;
return function() {
var now = Date.now()
var context = this
// ES5写法:var args = []; args.push.apply(null, arguments)
var args = [...arguments] // ES6数组解构知识点:复制数组
// 如果当前时间减去上一次执行时间大于我们执行函数的时间间隔再执行
if(now - previous > wait){
func.apply(context, args);
// 闭包,记录本次执行时间戳
// 这么写就是不用将上次执行的时间作为参数传给函数了
// 就算多次调用闭包不会消失,上一次执行时间不会消失,这就是闭包的常用方式
previous = now;
}
}
}
比较推荐这种实现方式,定时器实现不太好。
- 定时器实现
function throttle(func, wait){
let timer = null;
return function(){
var context = this
// ES5写法:var args = []; args.push.apply(null, arguments)
var args = [...arguments] // ES6数组解构知识点:复制数组
// 如果当前时间减去上一次执行时间大于我们执行函数的时间间隔再执行
if(timer) return;
timer = setTimeout(function(){
func.apply(context, args);
timer = null;
}, wait)
}
}
解释定时器实现弊端:因为js是单线程执行的,定时器严格意义上并不是在多少秒后执行,会有一定误差,同时如果在期间遇到优先级更高的函数,可能会阻断定时器的执行(定时器属于回调函数,优先级较低),像Java这种多线程语言,定时任务是严格按照时间执行的,不会存在误差。
防抖函数
防抖函数是当一个函数正在执行,但还没有执行结束时,又再一次执行了该函数,就会造成抖动现象。
实际中就是当我在监听一个元素的移动,当移动到指定位置或范围时将其位置锁定并保存到数据库,并且在函数中有很多判断,比如你移动的位置不能超过什么位置,如果超过要给出提示(但是并不会妨碍用户的移动)。
假设有一个场景:用户先移动到了规定的范围外,又快速移动到了规定的位置,这时候你提示出位置错误,但实际是我在指定的位置,这就是因为你监听的移动函数一直在执行,当用户移动到范围外时函数并没有阻止,而是正常执行了。正确应该是,等用户移动完了,不动了在执行函数的判断。
可能在工作中这种场景比较少见,不过这也是一个重要的知识点,不然还是影响用户体验的,严重的可能导致数据错误。
// 使用闭包的防抖函数,不用担心作用域
function debounce(fn, delay) {
var timer;
return function () {
var _this = this; // 取debounce執行作用域的this
var args = arguments;
if (timer) {
clearTimeout(timer);
}
timer = setTimeout(function () {
fn.apply(_this, args); // 用apply指向調用debounce的對象,相當於_this.fn(args);
}, delay);
};
}
// 不使用闭包,timer需要定义为全局变量
var timer;
function debounce(fn, delay) {
clearTimeout(timer);
timer = setTimeout(function(){
fn();
}, delay);
}
3. 函数柯里化(不常用,但是一种很重要的思想)
柯里化(Currying),又学了一个新单词,是一个函数的高阶技术,很多编程语言都有使用,作用就是将一个参数比较复杂的函数进行单个参数的拆分,使其变成一个可以简单调用的函数。
举例:
// curry(f) 定义一个函数柯里化的转换器,只针对下面的sum函数
// 下面依旧是闭包的实现,调用curry后最终执行的函数还是f,只是进行了拆分和简化
function curry(f) {
return function(a) {
return function(b) {
return f(a, b);
};
};
}
// 用法,sum可以称为主函数
function sum(a, b) {
return a + b;
}
// curriedSum可称为偏函数
let curriedSum = curry(sum);
alert( curriedSum(1)(2) ); // 3
上面的函数大多数人看来没什么用,因为js的函数调用机制,一般人都会将不常用的参数定义在最后,实际调用时不传也不会影响什么,倒是也有点柯里化的意思,那么接下来这个例子就可以说清楚函数柯里化真正的作用。
例1:封装一个日志函数,使用
普通函数拆分方法和函数柯里化两种方式
// 定义一个基础的日志函数
function log(date, type, message) {
console.log(date, type, message)
}
// 之前常用的函数拆分(变相柯里化)方式
function logDate(type, message) {
log(new Date(), type, message)
}
function logInfo(message) {
logDate("info", message)
}
// Sat May 04 2024 11:50:59 GMT+0800 (中国标准时间) 'info' '普通函数拆分日志函数'
logInfo("普通函数拆分日志函数")
// ---------------------------------------------
// 使用柯里化,我只能说很优雅
function curriedFun(fun) {
return function (date) {
return function (type) {
return function (message) {
return log(date, type, message)
}
}
}
}
var curriedLog = curriedFun(log)
var curriedLogDate = curriedLog(new Date())
var curriedLogInfo = curriedLogDate("info")
// Sat May 04 2024 11:50:59 GMT+0800 (中国标准时间) 'info' '普通函数拆分日志函数'
curriedLogInfo("柯里化日志函数")
弊端:
- 代码量大
- 可读性降低。
代码量解决:后续会封装一个函数柯里化的工具,极大减少代码量
可读性降低:
这个对于新手来说可读性不高,如果基础函数很复杂,参数很多,我们只需要其中几个参数,复制一个函数是常见的手段,但柯里化手段就可以避免复制。
优势:
- 延迟执行。
延迟执行可能有的人不太理解,假设一个场景,有一个主函数负责最后的计算,计算逻辑很复杂且不能对外公开,需要好几个参数,而这几个参数又需要从不同的地方收集而来,那么柯里化派上了用场,通过柯里化提供一个偏函数,让不同的方法按顺序收集参数并执行偏函数,将偏函数传递给下一位,这样最后一位就将执行的结果返回,是不是有点类似流水线,每次只执行一个小步骤,最后的组装交给核心的人。
当然这种适用于函数复杂且参数来自不同方法的执行结果的场景,有一定限制。
- 参数复用。
这个倒是好理解一点,上面的例子我们将date和type都进行了复用,这样在调用的时候就更加简单,这也是编程中重要的思想,让使用者更加的方便。
接下来介绍一下函数柯里化的工具:
function curry(func) {
// 这里的args是你之后调用时传入的参数,ES6写法,拆分数组
return function curried(...args) {
// func.length是你需要柯里化的函数的参数长度,和你调用时的参数进行比较
if (args.length >= func.length) {
// 如果调用时参数数量大于或者等于原函数参数数量,则直接使用apply执行函数
return func.apply(this, args);
} else {
// 相反则继续调用curried函数,继续柯里化
// args2指的是你下一步调用的新参数
return function(...args2) {
return curried.apply(this, args.concat(args2));
}
}
};
}
如何使用呢,拿上面的日志例子来说
log = curry(log)
var logDate = log(new Date())
logInfo = logDate ("info")
// logInfo等同于log(new Date(), "info", "日志内容")
logInfo("柯里化日志函数")
这样的好处就是,在不影响原函数执行逻辑的前提下,我们可以进行其它操作,这对修改别人的代码有奇效,我们柯里化一下函数,不影响之前的调用,我们还能做一写其它操作。
函数柯里化重点还是方便了我们程序猿,相对原始的调用肯定是稍微影响了一点执行效率,但影响可以说很小。
4.链式调用
这是一个很常见的方式,本质就是使用的闭包将前一个函数的执行结果进行保存,继续调用时还可以使用前一个函数的执行结果,用一个例子介绍一下。
function calculator() {
let result = 0;
function add(num) {
result += num;
// 这里的this实际就是后面链式调用的calculator对象,这个对象上有所有的方法
return this;
}
function subtract(num) {
result -= num;
return this;
}
function multiply(num) {
result *= num;
return this;
}
function divide(num) {
result /= num;
return this;
}
function getResult() {
return result;
}
function clear() {
result = 0;
return this;
}
return {
add,
subtract,
multiply,
divide,
getResult,
clear,
};
}
const calc = calculator();
const result = calc.add(5).subtract(2).divide(3).multiply(6).getResult();
console.log(result); // 输出:6
这是一个计算器的简单例子,可以很清晰的看到链式调用的好处,而ES6的Promise函数其实也是一样的道理,我们在vue常用的axios请求,执行结束后链式调用then和catch方法就是一个Promise对象上有这两个方法,而执行结果是最开始调用axios请求返回的对象,就是上面的result。
5.迭代器(不常见)
function createIterator(arr) {
let index = 0;
return {
next: function() {
if (index < arr.length) {
return {
value: arr[index++],
done: false
};
} else {
return {
done: true
};
}
}
};
}
const myIterator = createIterator([1, 2, 3]);
console.log(myIterator.next()); // { value: 1, done: false }
console.log(myIterator.next()); // { value: 2, done: false }
console.log(myIterator.next()); // { value: 3, done: false }
console.log(myIterator.next()); // { done: true }
这种迭代器是用闭包实现的,也就是变相的for循环,下标index是一直存在的,但目前经过资料查询没有发现这种用法的妙处和意义,所以只是介绍一下。
6.发布-订阅者模式(了解)
function createPubSub() {
// 存储事件及其对应的订阅者
const subscribers = {};
// 订阅事件
function subscribe(event, callback) {
// 如果事件不存在,则创建一个新的空数组
if (!subscribers[event]) {
subscribers[event] = [];
}
// 将回调函数添加到订阅者数组中
subscribers[event].push(callback);
}
// 发布事件
function publish(event, data) {
// 如果事件不存在,则直接返回
if (!subscribers[event]) {
return;
}
// 遍历订阅者数组,调用每个订阅者的回调函数
subscribers[event].forEach((callback) => {
callback(data);
});
}
// 返回订阅和发布函数
return {
subscribe,
publish,
};
}
// 使用示例
const pubSub = createPubSub();
// 订阅事件
pubSub.subscribe("event1", (data) => {
console.log("订阅者1收到事件1的数据:", data);
});
pubSub.subscribe("event2", (data) => {
console.log("订阅者2收到事件2的数据:", data);
});
// 发布事件
pubSub.publish("event1", "Hello");
// 输出: 订阅者1收到事件1的数据: Hello
pubSub.publish("event2", "World");
// 输出: 订阅者2收到事件2的数据: World
如果想要详细了解,可以看一下这篇文章。
闭包的内存回收
function createClosure() {
let value = 'Hello';
// 闭包函数
var closure = function() {
console.log(value);
};
// 解绑定闭包函数,并释放资源
var releaseClosure = function() {
value = null; // 解除外部变量的引用
closure = null; // 解除闭包函数的引用
releaseClosure = null; // 解除解绑函数的引用
};
// 返回闭包函数和解绑函数
return {
closure,
releaseClosure
};
}
// 创建闭包
var closureObj = createClosure();
// 调用闭包函数
closureObj.closure(); // 输出:Hello
// 解绑闭包并释放资源
closureObj.releaseClosure();
// 尝试调用闭包函数,此时已解绑,不再引用外部变量
closureObj.closure(); // 输出:null
备注:此6种用法参考文章https://zhuanlan.zhihu.com/p/686959137,在此基础上进行了加工,加工后相对更加详细。
闭包的最大弊端就是内存无法被回收,可能会造成内存泄露,这是一个较为标准的回收方法,核心就是将闭包使用的内部变量给赋值为null,这个之前说过,这样就可以被回收。也就是我们在之后使用的时候,尽可能的用上述方法,但是咱也不能说一定要这么写,没有最完美的代码,有时候我们也说不准到底在什么时候回收闭包的内存,一般来说不会影响那么大,只是说对于有些数据量大的方法,一定要记得回收。
关于闭包的介绍就到这,如果有问题我们及时交流。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









