







redis面试宝典之看这篇就够了
redis是经典面试问题,下面由我们解决面试官常问的八大问题来手撕面试官。
一、redis的类型有哪几种
二、redis的应用函数
三、redis应用场景
四、redis作为锁有哪几个方式
五、redis的优点(可以理解为问:redis为什么可以缓存使用)
六、redis的备份方式
七、redis使用的方式及其优缺点
八、redis缓存淘汰策略
九、对比 mecache
十、redist缓存击穿,穿透,雪崩
一、redis基本数据类型(常用五种)
- String-字符串(字符串类型最大存储512M)
- Hash-哈希表
- List-列表
- Set-集合
- Zset-有序集合
特殊数据结构类型(不常用三种)
- Geospatial-地理位置
- Hyperloglog-基数统计
- Bitmap-位图
二、redis常用应用函数
1.SET:设置指定key的值。
2.GET:获取指定key的值。
3.DEL:删除指定key。
4.EXISTS:判断指定key是否存在。
5.KEYS:获取所有符合给定模式的key。
6.TTL:获取指定key的剩余过期时间。
7.EXPIRE:设置指定key的过期时间。
8.INCR:将key的值增加1。
9.DECR:将key的值减少1。
10.HSET:设置指定哈希表中指定字段的值。
11.HGET:获取指定哈希表中指定字段的值。
12.HGETALL:获取指定哈希表中的所有字段和值。
13.LPUSH:将一个或多个值插入到列表头部。
14.RPUSH:将一个或多个值插入到列表尾部。
15.LPOP:移除并返回列表的第一个元素。
16.RPOP:移除并返回列表的最后一个元素。
17.SADD:向集合添加一个或多个成员。
18.SMEMBERS:返回集合中的所有成员。
三、redis的应用场景
1、作为缓存(比较简单常用)
2、分布式锁(着重学习)
四、redis锁的两种方式
1、redis(续命锁机制,实际操作可以引用jedis来实现)**
因为是单线程机制,setNX()函数设置获取锁,获得时间(20秒左右),避免宕机,线程挂了,不释放锁某些会长时间没完成的业务线程中,加入续命时间,避免未执行完而释放。在最后,释放锁。
2、使用Redisson实现(拥有可重入锁)
优点:
1、简单易用,为使用这提供一系列具有分布式特性的常用工具,降低设计和研发难度。
2、支持可重入,允许同一个线程多次获取一个锁
3、基于redis,性能良好
缺点:
1、依赖于redis,必须依赖可靠的redis服务
2、实行复杂度,尽管redisson简化了分布式锁的使用,但是实行分布式锁并保证高可用、高性能和一致性是非常复杂的,需要考虑到并发竞争,锁续约,死锁的等问题。
五、redis 的优点
1、存储在内存中,读取速度快
2、支持丰富的数据类型,list hashmap,set,zset,Sting,,不常用的三种
3、支持事务,操作具有原子性
4、比较灵活,可以作为缓存,也可以设置key的过期时间
六、备份方式(默认RDB)
1、 RDB方式
优点
- 冷备份方便。RDB定期生成快照方便,只需要一个文件dump.rdb ,对比,如果AOF想要这个效果需要定期copy出来,需要自己额外定时去弄
- 读写性能高。性能最大化
- 性能最大化。通过fork子进程来完成写操作,让主进程继续处理命令,RDB 一定时间才备份一次,AOF 快速写入,消耗一定资源
- 数据恢复快速。 RDB是直接导入,当数据集大时,比aof的启动效率高
- 安全性。容灾性好,可以保存到安全的硬盘
缺点
-
数据安全相对低,容易丢失数据,因为是间隔一段时间的持久化,持久化之间的故障会发生数据丢失,,该部分缺失,所以不严谨
-
影响性能,如果每次生成文件太大,会影响性能
综上所述:一般RDB间隔不能太长,否则每次生成RDB文件太大,或者延时产生问题
2、AOF(默认情况下关闭aof)
优点
-
数据更安全。持久化设置appendfysnc,实时操作记录到aof,一般间隔一秒就会急性一个同步操作,把缓存数据写进磁盘,那怕挂了也只是丢失1秒的数据。
-
写入性能高。以append-only 模式写入 ,没有任何磁盘消耗,写入性能高 ,而且不容易破损,就算尾部数据破损也容易修复。
-
日志文件不影响读写。rewrite log (重写),也不影响读写,因为会对指令进行压缩,创建成 一份需要恢复数据的日志,新的操作产生,直接覆盖旧的,某些文件没被rewite 之前,可以删除某些无关的误操作
-
误操作可以快速恢复。
缺点
-
快照文件大,aof文件比rdb大,而且恢复速度慢
-
假如想一条数据都不丢失可以按照每写入一条数据,同步一次,但是redis QPS大受影响
-
Aof 相对RDB,更容易出bug
-
冷备份的时候恢复更慢,数据集大的时候,比rdb启动效率低
3、备份总结
为了充分结合二者特点,实际可以用RDB+AOF方式进行备份 !
小结:不要仅仅使用RDB,因为那样会导致你丢失很多数据。也不要仅仅使用AOF,因为那样有两个问题,第一,RDB做冷备恢复速度更快; 第二,RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug。
综合使用AOF和RDB两种持久化机制,用AOF来保证数据不丢失,作为数据恢复的第一选择; 用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复。
注意事项:如果单纯用作缓存,可以禁止RDB和AOF操作
七、redis的多种使用方式
1、单体使用
架构简单,部署方便。高性价比。
缺点:不保证数据的可用性,进程重启后,数据会丢失,即使有备用节点解决高可用性,无法做到缓存预热的问题。而且高性能受限制于单核cpu的处理能力(redis是单线程机制),cpu是主要瓶颈,所以只适合操作简单的场景。可用memcached替换。
2、主从多体
高可靠性,采用双机主备架构,能够在主库出现故障时进行主备切换,从库提升为主库保证服务平稳运行。开启数据持久化和配置合理的备份策略,可以有效解决数据误操作和数据丢失的风险。(读写分离策略:从节点可以扩展主库节点的读能力,有效对大并发量的读操作)
缺点:
1、故障恢复复杂,如果没有RedisHA(需要开发),当主库节点出现故障,需要手动从节点晋升为主节点,同时需要通知业务方变更配置,并且需要让其他从库点去复制新主库节点,整个操作过程需要人为干预,比较繁琐。
2、主库写能力受限单机的限制(可以考虑分片优化)
3、主库存储能力受限制单机的限制(可以考虑PiKa)
4、原生的复制在早期版本比较突出,比如redis复制中断后,从库向主库发送同步请求,如果同步不成功,则会进行全量同步,主库执行全量备份的同事可能会造成毫秒级别或者秒级的卡顿,又由于cow机制,极端情况会导致主存内存溢出,程序宕机或者退出。主库节点生成备份文件导致服务器磁盘IO和CPU资源消耗,发送数GB大小的文件导致服务器的出口带宽暴增个,阻塞请求,所以建议升级到最新版本。
3、哨兵模式
哨兵模式集群部署简单,是基于主从模式的,具备主从的优点,而且通过哨兵的竞选机制,可以自动切换,系统更鉴权,可用性更高(自动版切换的主从复制)
缺点:1、是一种中心化的集群实现模式,模式复杂,始终只有一个redis主机来接收和处理请求,写操作受单机瓶颈影响。
2、所有节点都保存全量数据,浪费内存空间,没有实现分布式存储,数据量过大时,影响master的性能
3、redis主机宕机之后,会出现短时间无法写操作。因为在选举借宿之前,无法得知哪个是主从,所以会开启保护机制,禁止写操作。
主从模式或哨兵模式每个节点存储的数据都是全量的数据,数据量过大时,就需要对存储的数据进行分片后存储到多个redis实例上。此时就要用到Redis Sharding技术。
分片技术比较复杂而且种类多。
4、集群模式
完全去中心化,实现了redis的分布式存储,就是不同节点上存储不同的数据,解决单机redis容量有限的问题。
缺点:
1、结构比较复杂
2、key事务操作只支持key在同一节点上
3、key作为数据分区最小维度,无法将一个很大的键值对象,hah,list等映射到不同节点上
八、redis内存淘汰策略
三种删除策略+默认策略
1、定时删除(主动清理)
- 优点:节约内存,到期删除,立刻释放不需要的
- 缺点:CPU压力大,删除操作会占用时间。可能同一时间过期的key较多的话,导致cpu紧张,影响数据读写。
- 适用场景:强cpu,内存小 的情况。
2、惰性删除(被动清理)
数据到达时间先不删除,等下次访问的时候再删,然后返回不存在。
- 优点:节约cpu资源
- 缺点:容易出现长期占用内存的数据
- 适用场景:大内存,弱CPU的情况
3、定期删除(内存不足时触发主动清理)
每隔一段时间「随机」从数据库中取出 一定数量的 key 进行检查,并删除其中的过期key。
通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用(处理“定时删除”的缺点),从而处理“惰性删除的缺点”。
- 优点:限制删除操作执行时间和频率,减少对cpu的印象,同事也能删除部分过期key,减少无效占用
- 缺点:清理效果没有定时删除好,也没有惰性删除少占用资源。操作执行时长和频率复杂,如果设置频繁,同样对cpu不友好,如果执行少,则又难及时处理过期的key。
3.1 redis定期删除过程(如时长10次/s)和频率(20,不可配置)
1、从过期字典中随机抽取 20 个 key;2、检查这 20 个 key 是否过期,并删除已过期的 key;3、如果本轮检查的已过期 key 的数量,超过 5 个(20/4),也就是「已过期 key 的数量」占比「随机抽取 key 的数量」大于 25%,则继续重复步骤 1;如果已过期的 key 比例小于 25%,则停止继续删除过期 key,然后等待下一轮再检查。可以看到,定期删除是一个循环的流程。那 Redis 为了保证定期删除不会出现循环过度,导致线程卡死现象,为此增加了定期删除循环流程的时间上限,默认不会超过 25ms。
难点: 合理设置删除操作的执行时长和执行效率
4、redis默认选择(定期删除+惰性删除)
- 定期抽取一部分key来进行检测并删除已过期的key,如果过期数小于25%,则停止抽取。
- 这个策略会存在部分过期但是没删除的,所以请求获取到过期key的时候,再处理,并返回空值告诉客户端该值已过期。
缺点:可能会有相当一部分key没被请求,但是也没被清理,则会占用空间。(所以需要采用内存淘汰机制算法)
4.1 、Redis八种逐出策略
-
LRU算法:筛选最近最少用的数据,淘汰使用次数少的
-
LFU算法:筛选最后一次使用的数据,淘汰最后一次时间离现在最久的数据
(删除策略针对的对象是有时效性的数据、逐出策略针对的是内存满的时候如何处理,怎样替换。)
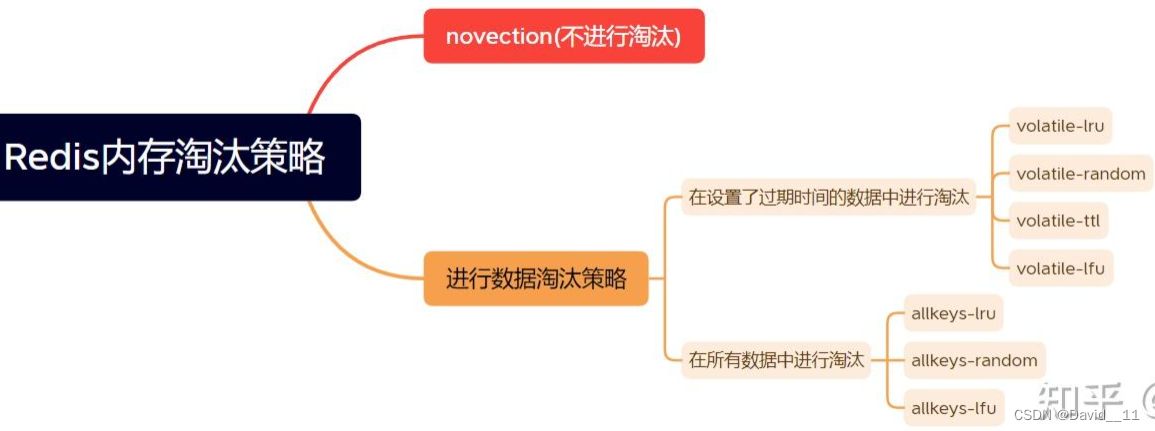
根据以上两种算法,配合过期数据或者所有数据的范围+不做淘汰的处理,得到8种方式
- noeviction:不进行淘汰。当内存满则不再提供服务。
- volatile-ttl:在设置过期时间的key,移除即将过期的key
- volatile-lru:在设置过期时间的key,移除最近最少使用次数的key
- volatile-lfu:在设置过期时间的key,移除离现在最久没用过的key
- volatile-random:在设置过期时间的key,随机移除key
- allkeys-random:在所有key中,随机移除key值
- allkeys-lfu:在所有key中,移除距离现在没用最久的key值
- allkeys-lru:在所有key中,移除最近最少使用次数的key值
4.2总结(redis默认LRU算法)**
- 建议使用allkey-lru,可以充分利用LRU的算法优势,把最近最常使用的保留。
- 如果冷热数据相差较大,用allkeys-lru 。
- 如果相差冷热程度不大,用allkeys-random。
九、redis 和mecache 对比
- redis可以持久化存到硬盘,memcache 只能存内存
- memcache支持类型较少,redis更丰富
- 底层协议不一样,redis有自己的vm机制,减少系统间调度的时间
- redis相对memcaced速度要快一点
- (线程方式对比)redis是单线程 ,利用队列技术将并发访问变成串行访问,消化传统数据库串行控制的开销;memcache支持多线程;
十、缓存穿透、击穿、雪崩
1、缓存穿透
原因:请求数据在缓存查询没有,数据库也没有。
解决:使用布隆过滤器进行筛选,或者在redis设置一个空字符串,让请求无法查询数据库而起到保护作用。
2、缓存击穿
原因:某热点数据同一时间大量失效,大量同一请求打到数据库缓。
解决:(1)可以提前预热热点数据;(2)热点数据永不过期;(3)加锁:缓存查询不到的数据,对请求资源加锁处理,查询成功后加入缓存。
3、缓存雪崩
原因:大量数据在同一时间失效,导致请求全部到数据库查询数据。
解决:给缓存设计随机过期时间避免同一时间大量过期。















 8585
8585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









