









前言
本文是根据python官方教程中标准库模块的介绍,自己查询资料并整理,编写代码示例做出的学习笔记。
根据模块知识,一次讲解单个或者多个模块的内容。
质量控制
质量控制(Quality Control, QC),主要关注于提高代码质量、确保数据准确性和程序稳定性。
数据质量
数据质量是指数据满足其预定用途所要求的准确性、完整性、一致性、及时性和有效性的程度。良好的数据质量是数据分析、决策支持以及模型训练等过程成功的基础。把控数据质量主要包括以下几个方面:
数据质量的要素:
- 准确性:数据是否正确无误,没有错误或偏差。
- 完整性:数据集中是否存在缺失值或丢失的信息。
- 一致性:数据内部及跨数据集之间是否存在矛盾或不匹配。
- 时效性:数据是否是最新的,能否反映当前状况。
- 有效性:数据是否符合预期的格式和范围,如日期格式正确、数值在合理范围内。
- 唯一性:记录是否有重复。
- 可追溯性:数据的来源和变更历史是否清晰可查。
如何把控数据质量:
- 数据验证规则:定义一套数据验证规则,比如字段格式、范围限制、唯一性约束等,并在数据输入时或定期进行检查。
- 数据清洗:使用Python中的Pandas等库进行数据清洗,包括处理缺失值、去除重复数据、纠正错误数据等。
- 数据质量报告:定期生成数据质量报告,包括数据概况、缺失值统计、异常值检测等,以便监控数据质量变化。
- 自动化检查:利用脚本或工具自动化执行数据质量检查任务,提高效率并减少人为错误。
- 数据治理:建立数据治理框架,明确数据责任人,制定数据管理策略和流程,确保数据从源头到应用的每个环节都有质量控制。
- 用户反馈循环:鼓励数据使用者反馈数据问题,建立快速响应机制,及时修正数据错误。
- 持续监控:实施数据质量监控系统,对关键指标进行实时或定期监控,一旦发现数据质量问题立即报警并采取措施。
通过上述方法,可以在Python中有效地把控数据质量,确保数据分析和决策基于可靠的数据基础之上。
数据清洗
数据清洗是数据预处理的关键步骤,旨在识别并纠正数据集中的错误、不完整、不准确或无关的部分,以提升数据质量,确保后续分析或建模的准确性。
在Python中,数据清洗通常借助pandas库完成。
示例
- 打开文件,read_xxx()。常用的入参就是文件路径和编码,如过有用到其他参数的用法,临时再学就好了。
import pandas as pd
# 打开一个名为"test.csv"的文件,没有就新建一个,我就是新建的
df = pd.read_csv('test.csv', encoding='gbk')
pd模块中还有很多read开头的函数,自行尝试。
-
head(n=5)函数:获取指定行数信息
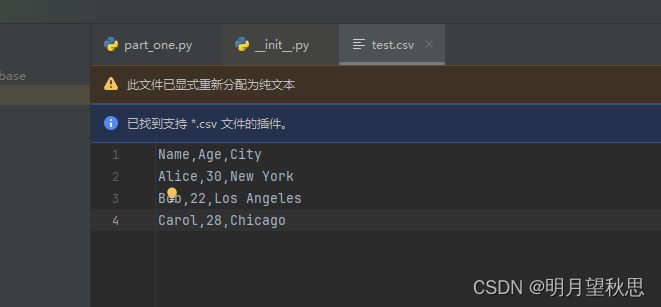
这个函数可以获取你拿到的数据的指定行数的部分,默认值是五。# 读取一下文件的信息,打印1行试试 print(df.head(1))这是打印出的数据

这是文件内容,注意我们的是csv文件,从Alice开始的才算是正式的数据
再换成打印3行试试,因为我们数据就3行
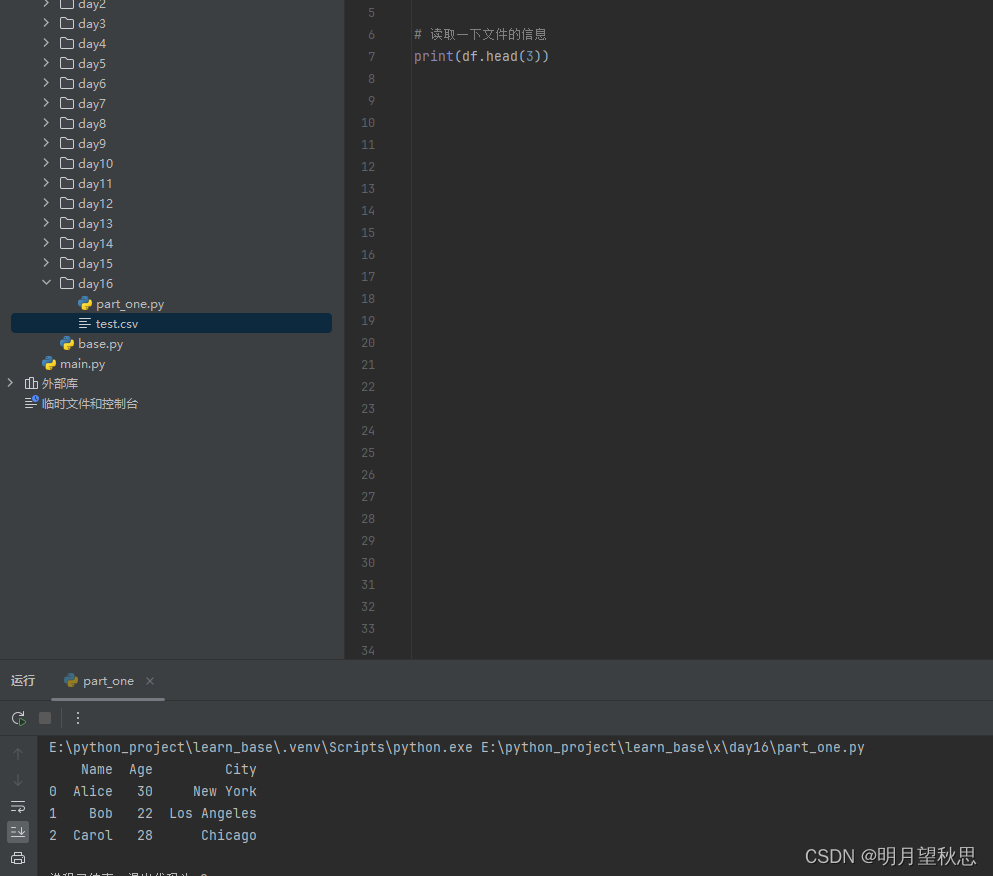
可以看到,数据全部打印了,前面有012,这个很好理解,我不多解释了。 -
info()函数:获取数据信息
函数用于展示DataFrame(简单理解为就是我们打开的数据)的结构、类型和内存使用情况。使用起来很简单,直接调用就好了。
参数说明
- verbose:默认为None,如果设置为True或False,将覆盖pd.options.display.max_info_columns的设置,控制是否打印所有列的详细信息。如果DataFrame的列数超过max_info_columns,默认行为是仅显示前后的部分列。
- buf:默认为sys.stdout,指定输出信息的目标,可以是一个文件对象或者具有write()方法的任何对象。
- max_cols:控制在详细输出中显示的最大列数。如果DataFrame的列数超过这个值,且verbose未被显式设置,那么将显示简略的摘要而非所有列的详情。默认值来自pd.options.display.max_info_columns。
- memory_usage:控制是否显示DataFrame及其索引的内存使用情况。可以是布尔值(True/False),或者字符串"deep"。"deep"会更深入地计算内存使用,包括嵌套结构的内存。默认情况下,仅显示内存使用情况的摘要。
- null_counts:在pandas的新版本中,此参数已被移除,因为现在默认总是显示非空值的数量。
返回值
info()函数本身不返回任何值,而是直接打印输出到控制台或指定的缓冲区。输出内容通常包括:- DataFrame的总行数和列数。
- 每列的名称、非空值数量、数据类型。
- 索引的类型和非空值数量。
- 如果设置了memory_usage=True或memory_usage=‘deep’,还会显示DataFrame及其索引的内存使用量。
print(df.info())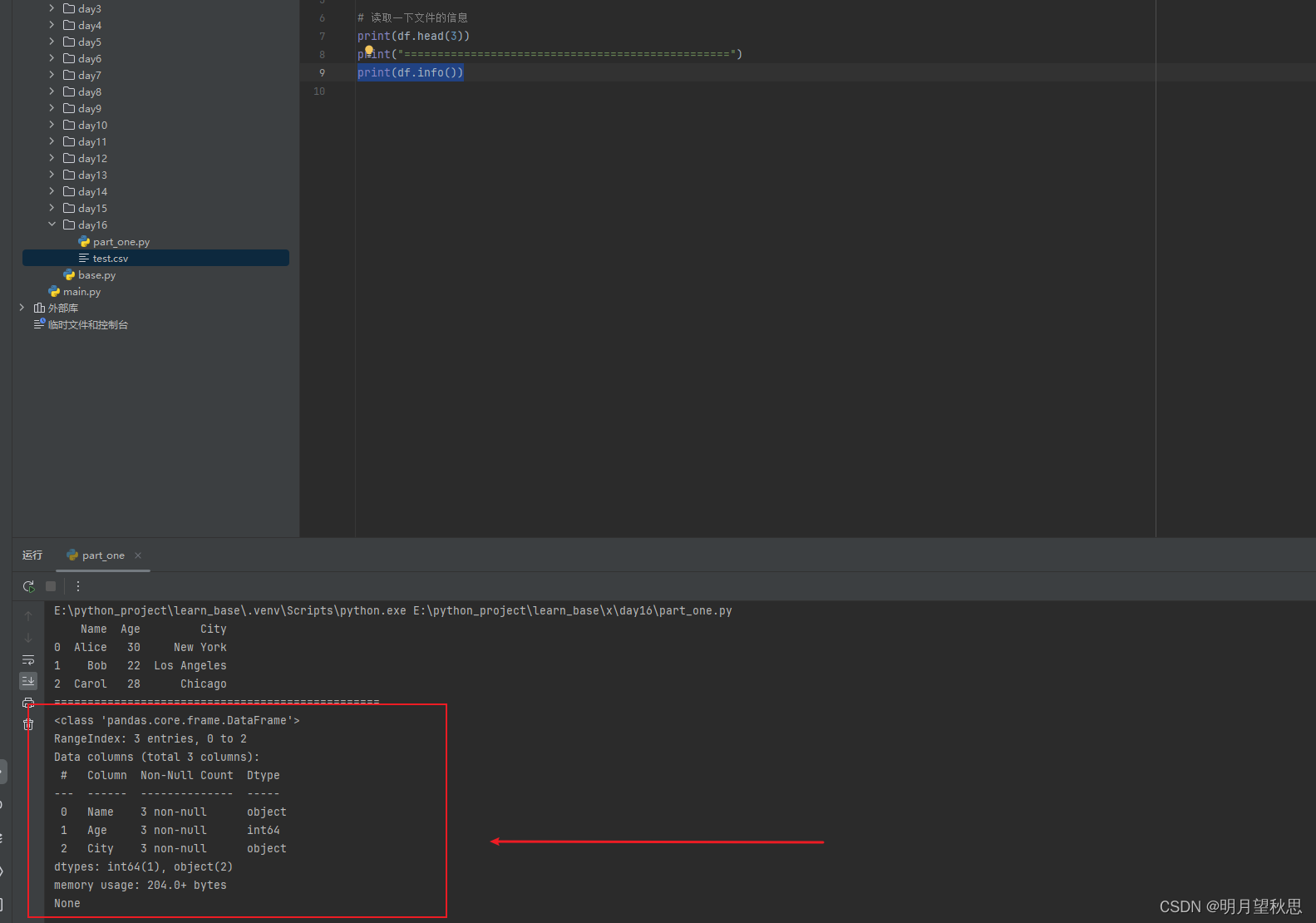
稍微解释一下:- 类信息:<class ‘pandas.core.frame.DataFrame’> 表明df是一个pandas的DataFrame对象。
- 索引范围:RangeIndex: 3 entries, 0 to 2 表示DataFrame有3行数据,索引是从0到2的整数序列。
- 数据列详情:
- 列出了每一列的名称(Column)、非空值的数量(Non-Null Count)以及数据类型(Dtype)。
- 列1 (Name):3个非空值,数据类型为object(通常表示字符串)。
- 列2 (Age):3个非空值,数据类型为int64(整数)。
- 列3 (City):3个非空值,数据类型为object(通常表示字符串)。
- 数据类型汇总:dtypes: int64(1), object(2) 总结了DataFrame中各数据类型的列数。这里说明有1列是int64类型,2列是object类型。
- 内存使用:memory usage: 204.0+ bytes 表示该DataFrame占用的大约内存大小。注意这里的“+”表明计算可能不是完全精确的,特别是当使用memory_usage='deep’时,但对于估计内存消耗很有帮助。
- 结尾的None:这是因为df.info()函数实际上没有返回值(返回None),它直接将信息输出到控制台。当你在Python脚本或交互式环境中 调用print(df.info())时,最终的None是由print函数打印出来的,表示df.info()执行完毕并没有返回任何可供打印的实际内容。
-
isnull()函数:获取缺失值对象
print(df.isnull)这个函数会返回一个和原来数据结构相同但是为布尔值的对象,通过这个对象,我们可以对数据中的缺失值进行操作。
简单修改一下原来的数据。
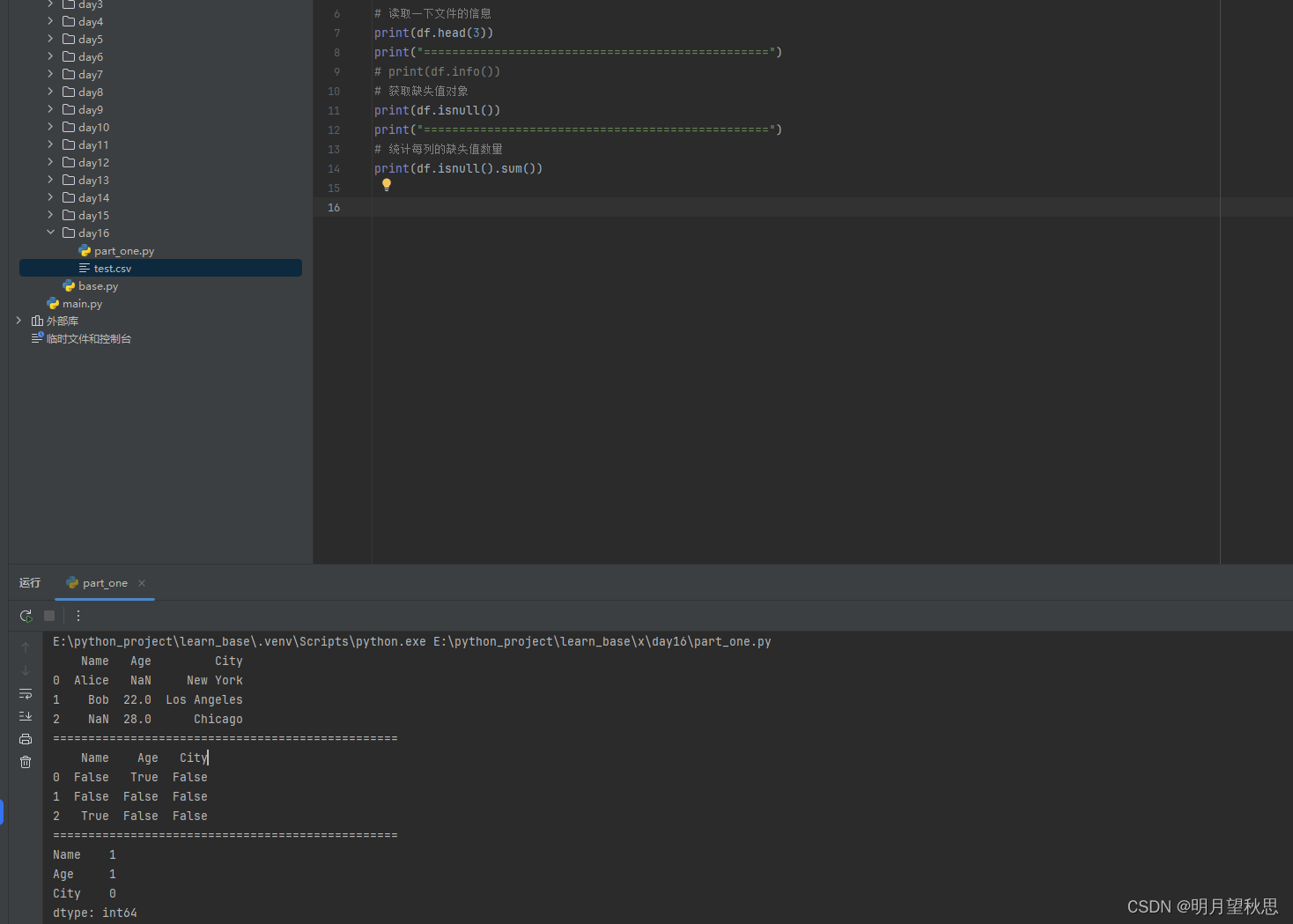
通过isnull函数,我们可以明确看到哪一行哪一列有缺失值,通过sum函数,我们可以明确知道的哪一列缺失了几个值。
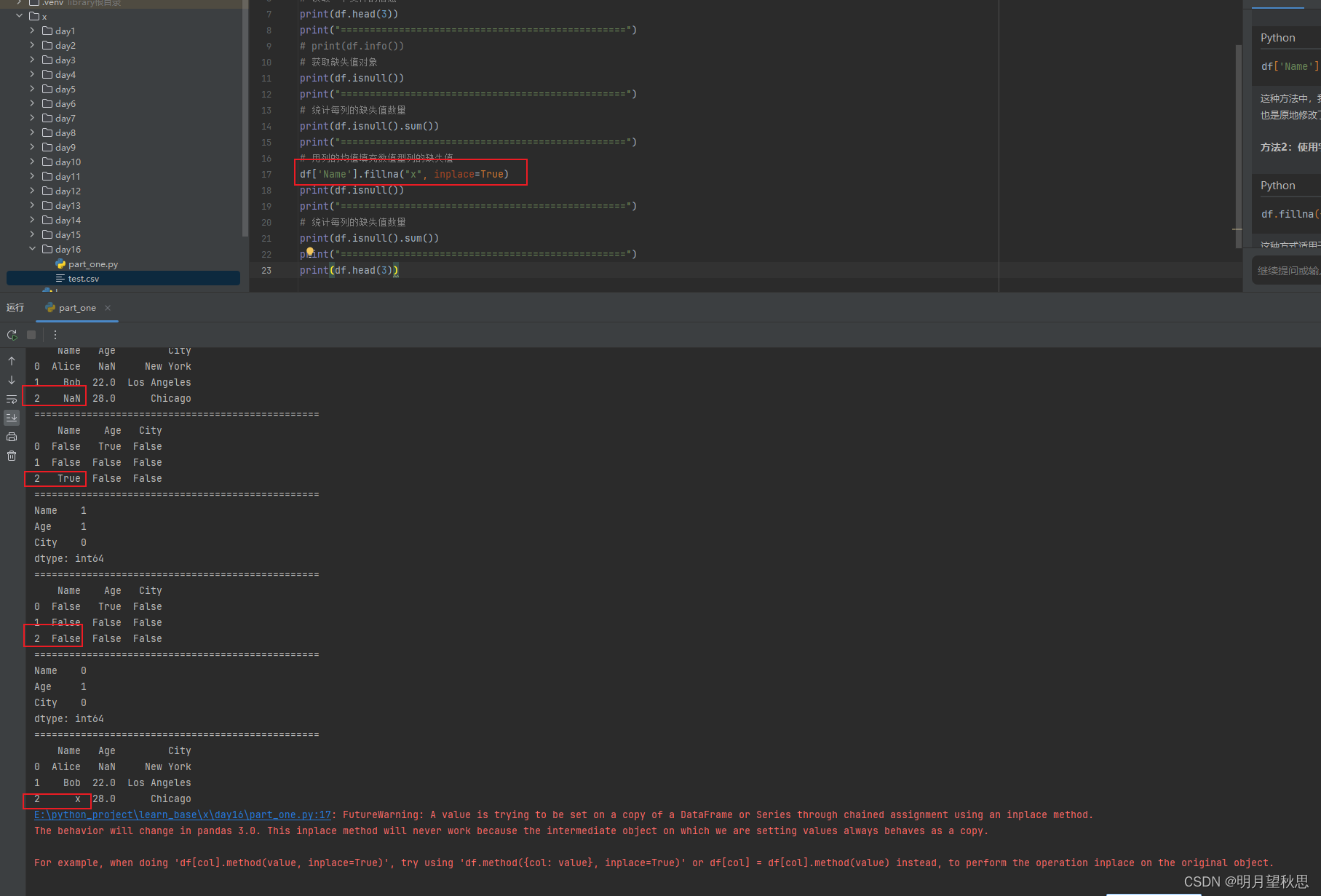
通过前后几次的输出对比,可以明显发现我们已经将name一列的缺失值补充上去,并且为我们设置的值x。
最后输出框中出现一堆红色的告警,提示的是关于链式赋值(chained assignment)和 inplace 操作的问题。pandas 3.0版本中,这种通过链式赋值进行的inplace操作可能不再有效,因为中间对象可能被视为原对象的一个副本,而不是原对象本身。
为了避免这个警告并确保代码在未来版本的pandas中也能正常工作,您可以按照警告的建议采用以下两种方式之一:df.method({col: value}, inplace=True)或者df[col] = df[col].method(value)。换成我们的代码就是
# 方法1 df.fillna({'Name': "x"}, inplace=True) # 方法2 df['Name'] = df['Name'].fillna("x") -
dropna()函数:删除有缺失值的行
# 直接删除含有缺失值的行 df.dropna(inplace=True)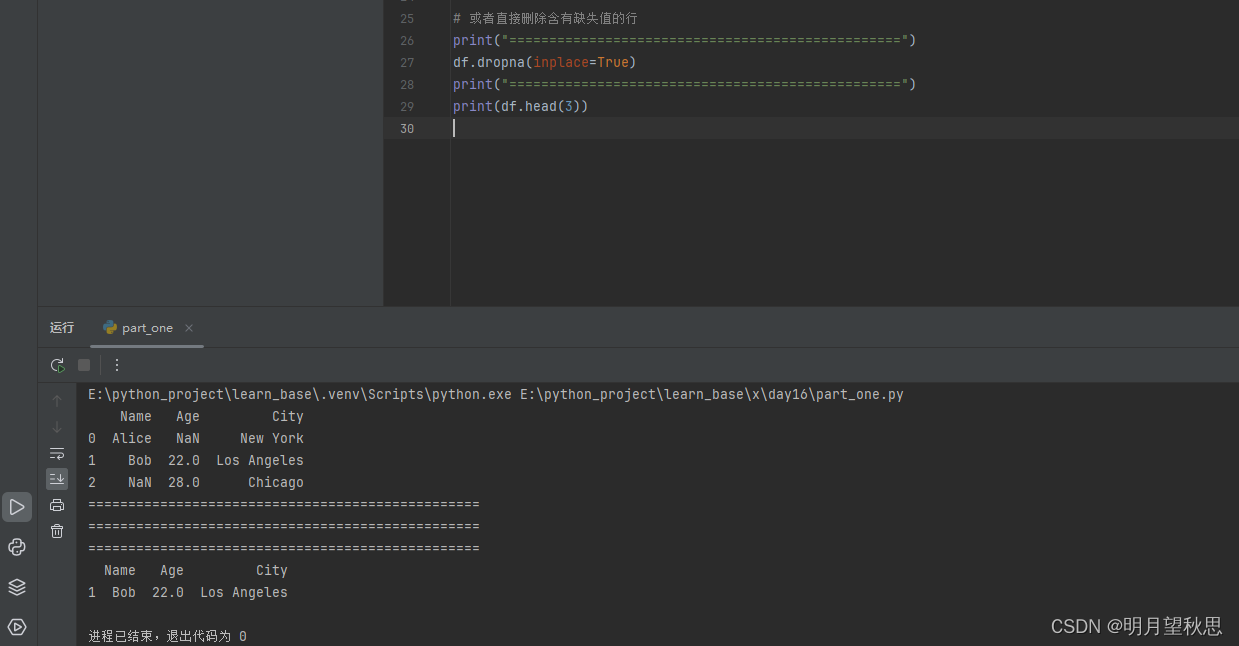
-
drop_duplicates()函数:删除重复数据
df.drop_duplicates(inplace=True)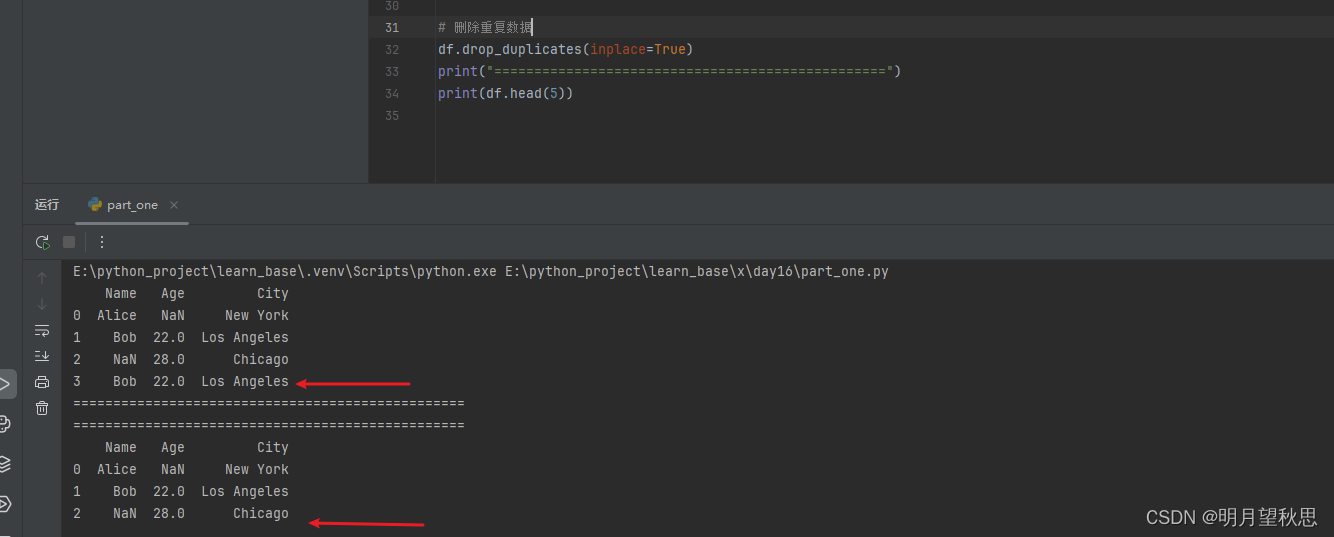
-
astype()函数:类型转换
# 将某列转换为整型 df['column_name'] = df['column_name'].astype(int)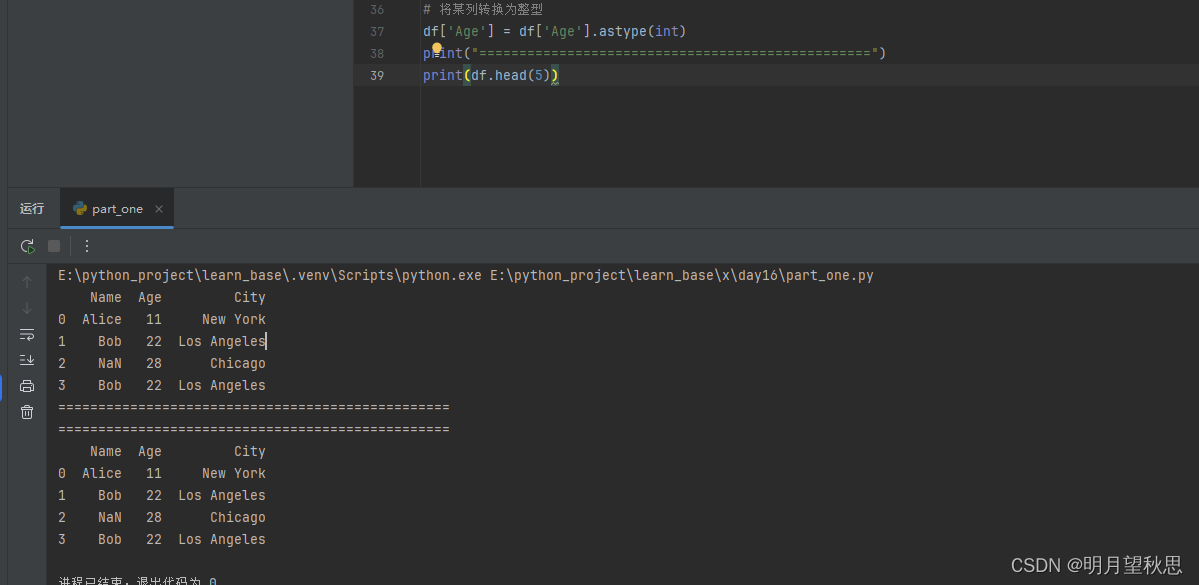
注意如果列有缺失值,可能会导致转换失败,别问我怎么知道的。 -
文本数据清洗:
.str# 去除空格 df['text_column'] = df['text_column'].str.strip() # 大小写 df['text_column'] = df['text_column'].str.lower()这个就不单独运行了,看函数名就知道啥作用
-
replace()函数:替换特定值
df['column_name'].replace('old_value', 'new_value', inplace=True)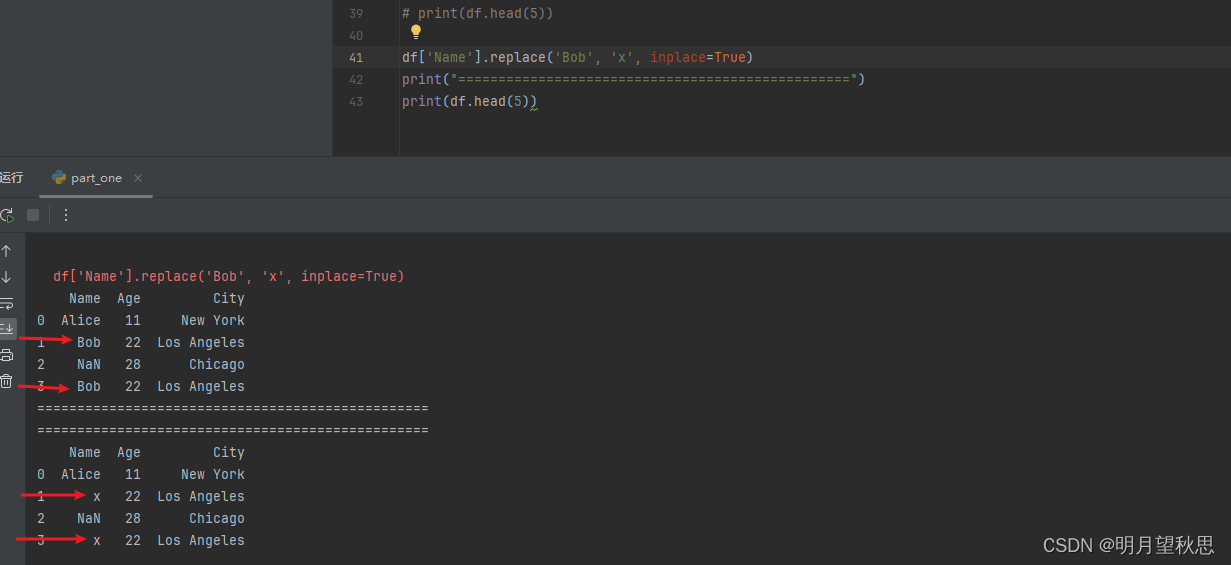
数据清洗的方法还有很多,想写完不太可能,写一些常用的简单的认知一下即可。
结尾
数据质量不止数据清洗这一项,还有其他很多项,但是基本都是配合着一起来的。这里只是初步认知,不需要讲那么多。大概都了解了,就进到项目那一块去,等你写出一个项目,比如一个小游戏后,成就感足以让你继续向下努力学习了,这里太深入讲只会浪费热情,耐心。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









