









mysql
1、简介
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
2、什么是数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理
3、RDBMS关系型数据库特点
<1>数据以表格的形式存储
<2>每行表示一条记录(一条信息)
<3>每列表示记录所对应的属性
<4>许多的行和类组成一张数据表
<5>若干的表单组成database
4、安装MySQL
MySQL 8.0.26 图形化安装教程 (windows 64位)_gblfy的博客-CSDN博客
5、使用命令创建数据库
通过结构化查询语句**SQL**
<1>连接数据库
mysql -u root -p密码
<2>查看数据库
show databases
<3>切换数据库
use 数据库名称
<4>创建数据库
create database 数据库名
<5>删除数据库
drop database 数据库名
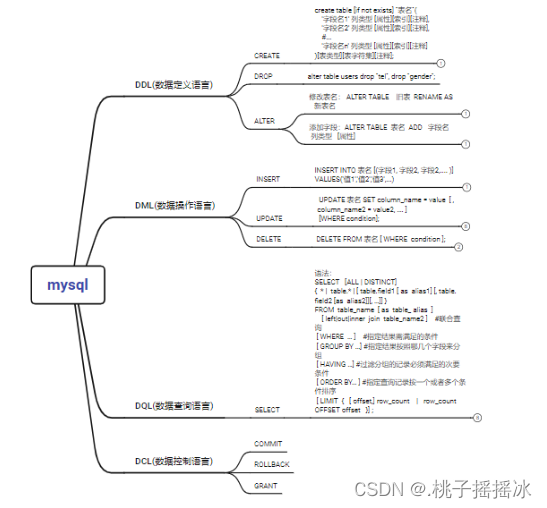
6、通过结构化查询语句SQL操作关系型数据库
| 名称 | 解释 | 命令 |
|---|---|---|
| DDL(数据定义语言) | 定义和管理数据对象 | CREATE DROP ALTER |
| DML(数据操作语言) | 用于操作数据库对象中所包含的数据 | INSERT UPDATE DELETE |
| DQL(数据查询语言) | 用于查询数据库数据 | SELECT |
| DCL(数据控制语言) | 用来管理数据库的语言,包括管理权限及数据更改 | COMMIT ROLLBACK GRANT |
<1>DDL
创建数据表
create table [if not exists] `表名`(
'字段名1' 列类型 [属性][索引][注释],
'字段名2' 列类型 [属性][索引][注释],
#...
'字段名n' 列类型 [属性][索引][注释]
)[表类型][表字符集][注释];
栗子:
CREATE TABLE IF NOT EXISTS `users`(
`uid` VARCHAR(200) PRIMARY KEY NOT NULL COMMENT '用户id',
`username` VARCHAR(200) UNIQUE NOT NULL COMMENT '用户名',
`gender` INT NOT NULL DEFAULT 1
) ENGINE=INNODB DEFAULT CHARSET=utf8;
列类型 :包括varchar(长度)、int 、float、date/datetime;
数据字段属性:
unsigned(无符号的,声明该数据列不允许复数)
zerofill:(0填充的,不足位数的用0来填充)
Auto_InCrement:(自动增长的,每添加一条数据,自动在上一个记录数上加1(默认),通常用于设置主键,且为整数类型)
可定义起始值和步长:
当前表设置步长(AUTO_INCREMENT=100) : 只影响当前表
SET @@auto_increment_increment=5 ; 影响所有使用自增的表(全局)
NULL 和 NOT NULL :
默认为NULL , 即没有插入该列的数值
如果设置为NOT NULL , 则该列必须有值
DEFAULT :
默认的
用于设置默认值
例如,性别字段,默认为"男" , 否则为 “女” ; 若无指定该列的值 , 则默认值为"男"的值
primary key:
用于设置主键
unique:
用于设置唯一性,不能重复,但是可以为空
ENGINE=innodb DEFAULT CHARSET=utf8:SQL引擎及其约束和字符编码
显示表结构: desc 表名;

删除表
修改表名: ALTER TABLE 旧表名 RENAME AS 新表名
alter table users rename as userss
添加字段:ALTER TABLE 表名 ADD 字段名 列类型 [ 属性 ]
ALTER TABLE users ADD `password` VARCHAR(200) COMMENT '密码';
--一次性添加多个字段
ALTER TABLE users ADD `tel` VARCHAR(200), ADD `address` VARCHAR(200);
删除字段:ALTER TABLE 表名 DROP 字段名
alter table users drop `tel`, drop `gender`;
<2>DML
insert:插入数据
INSERT INTO 表名 [(字段1, 字段2, 字段2,.... )] VALUES('值1','值2','值3',...)
insert into users(uid,username,password) values('u1001','admin','123456');
INSERT INTO users VALUES('u1002','ls','123456','','');
--可同时插入多条数据,values 后用英文逗号隔开
INSERT INTO users VALUES('u1003','ls','123456','',''),('u1004','ww','123456','','');
update:更新数据
UPDATE 表名 SET column_name = value [ ,column_name2 = value2, …. ]
[WHERE condition];
-- 修改uid='u1001'的password为654321
update users set password ='654321' where uid='u1001';
-- 修改uid='u1001'的password为123456和tel为18954271245
update users set password ='1234566',tel='18954271245' where uid='u1001';
-- 修改users表中所有数据的address为无
update users set address = '无' where 1=1
-- 修改users表中username不等于admin的数据,将 address修改为null
update users set address = null where username <> 'admin'
-- 修改users表中age>18的用户的address为陕西
update users set address='陕西' where age > 18
-- 修改users表中age>18并且小于40 的用户的address为山西
UPDATE users SET address='山西' WHERE age between 18 and 40;
UPDATE users SET address='山西运煤到西山' WHERE age >=18 and age <=40
-- 修改users表中username为admin 或ls的地址为四川
UPDATE users u SET u.address='四川' WHERE u.username = 'admin' or u.username= 'ls'
UPDATE users u SET u.address='四川' WHERE u.username in('admin','ls')
-- 修改users表中username包含ls的用户的address为深圳 (模糊匹配)
update users u set u.address='深圳' where u.username like '%ls%'
-- 修改users表中username不为admin和ls的地址为浙江
UPDATE users u SET u.address='四川' WHERE u.username <> 'admin' and u.username <> 'ls'
UPDATE users u SET u.address='浙江' WHERE u.username not IN('admin','ls')
delete 删除数据
DELETE FROM 表名 [ WHERE condition ];
-- 删除users表中uid等于u1005的用户
DELETE FROM users WHERE uid = 'u1005'
--用于清空表中的所有数据,速度更快
TRUNCATE table_name
truncate users;
<3>DQL
数据库中表的设计遵循的设计规范:
<1>三大范式:
1.第一范式(1NF)
原子性:强调的是列的原子性,即数据库中每一列的字段都是单一属性,不可再分,并且都是基本数据类型
不符合第一范式的解决方法:将一个字段分割成多个字段
2.第二范式(2NF)
依赖性:在满足1NF的基础上再满足依赖性的两个约束:一张表必须有一个主键;非主键类必须完全依赖于主键
不符合第二范式的解决方法:将一张表拆分成多张表
3.第三范式(3NF)
在满足2NF的基础上,另外再满足一个条件:非主键列必须直接依赖于主键,不能存在传递依赖
不符合第三范式的解决方法:表的拆分
4.关联关系:
1>1----1(1对1) 最佳情况
2>1----n(1对多) 拆分完成后,将关联关系放在多方上
3>n----m(多对多) 需要建立一张关联表
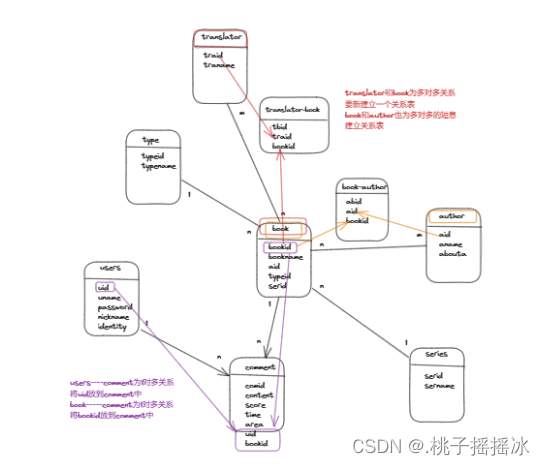
根据数据关联,创建的douban数据库
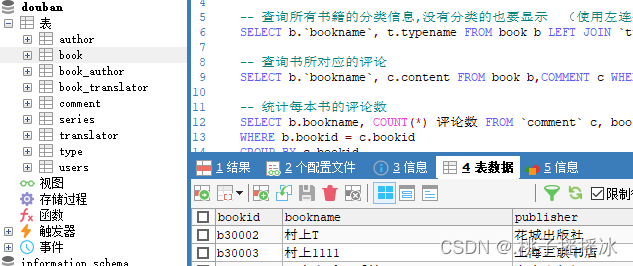
<2>查询语句
- 使用的关键字 select
- 简单的单表查询或多表查询和嵌套查询
- 数据库语言中最核心、最重要的语句
- 使用频率最高的语言
1>单表查询
-- 查询所有书籍的分类信息
SELECT * FROM classify;
-- 查询所有书籍的分类信息名称
SELECT cname FROM classify;
-- 给表起别名
SELECT c.`cname` FROM classify c;
-- 给列起别名
SELECT c.`cname` AS 'classifyName' FROM classify c;
-- 查询价格大于40元的所有书籍,显示书名和isbn
SELECT b.`bookname`, b.`isbn` FROM books b WHERE b.`price` > 40;
-- 查询有多少本书存在评论信息
SELECT DISTINCT(c.`booid`) FROM COMMENT c;
注意:
通过 as 可以给表和列起别名,其中as可以省略不写
distince关键字的作用是去除重复的数据
2>表达式
-- 表达式
select 1+1;
-- 由于纸的价格上涨,需要给每本书进行涨价10%,保留两位小数 [运算表达式]
select b.`bookname`,b.`price`, round(b.`price`*(1.1),2) newprice from books b;
-- 涨价完成后,更新到数据库中。(练习)
-- 统计书本的数量 [函数]
select count(b.`bid`) `sum` from books b;
-- sum函数 求和 max 最大值 min 最小值 AVG 求平均值 round 四舍五入
3>多表查询
-- 查询所有书籍的分类信息
SELECT b.`bookname`, t.typename FROM book b, `type` t WHERE b.`typeid` = t.typeid
-- 查询所有书籍的分类信息,没有分类的也要显示 (使用左连接或右连接)
SELECT b.`bookname`, t.typename FROM book b LEFT JOIN `type` t ON b.`typeid` = t.typeid
-- 查询书所对应的评论
SELECT b.`bookname`, c.content FROM book b,COMMENT c WHERE b.`bookid` = c.bookid
-- 统计每本书的评论数
SELECT b.bookname, COUNT(*) 评论数 FROM `comment` c, book b
WHERE b.bookid = c.bookid
GROUP BY c.bookid
-- 统计每个用户的评论个数
SELECT u.uname, COUNT(*) 评论数 FROM users u, `comment` c
WHERE c.uid = u.uid
GROUP BY c.uid
-- 书的价格上涨10%,并更新数据
SELECT b.`bookname`,b.`price` * (1.1) FROM book b`book_translator``book_translator`
UPDATE book b SET b.`price` = b.`price` * (1.1)
SELECT b.bookname, b.`price` FROM book b
4>limit限制
-- 显示前3条分类信息
SELECT * FROM classify LIMIT 3;
-- 显示第2条到第5条的分类信息
SELECT * FROM classify LIMIT 1,4;
5>分组聚合
group by–指定结果按照哪几个字段来分组
having—>过滤分组的记录必须满足的条件
-- 统计每本书评论的数量大于等于2条
SELECT b.bookname, COUNT(*) `sum` FROM `comment` c, book b
WHERE b.bookid = c.bookid
GROUP BY c.bookid
HAVING SUM >= 2
-- 统计评分大于等于4的书的评论数
SELECT b.`bookname`,b.`bookid`,COUNT(b.`bookid`) FROM book b,`comment` c
WHERE b.bookid = c.bookid AND c.score > 4
GROUP BY b.`bookid`















 42万+
42万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









