







AI 自动提取
PlatonAI 的目标是开发一套高效采集并阅读理解复杂网站的 AI,完整精确输出数据和知识。目前我们开源了“高效采集”这一部分,“阅读理解”这一部分是个长期且艰巨的任务,我们发布了一个“阅读理解网页结构并完整精确输出数据”的预览版,这个版本在不久的未来也会开源。
PlatonAI 的算法能够 100% 无人干预将网页变成数据 – 不需要配规则,甚至也不需要机器学习训练,它是无监督机器学习驱动的,像人一样去阅读理解互联网。
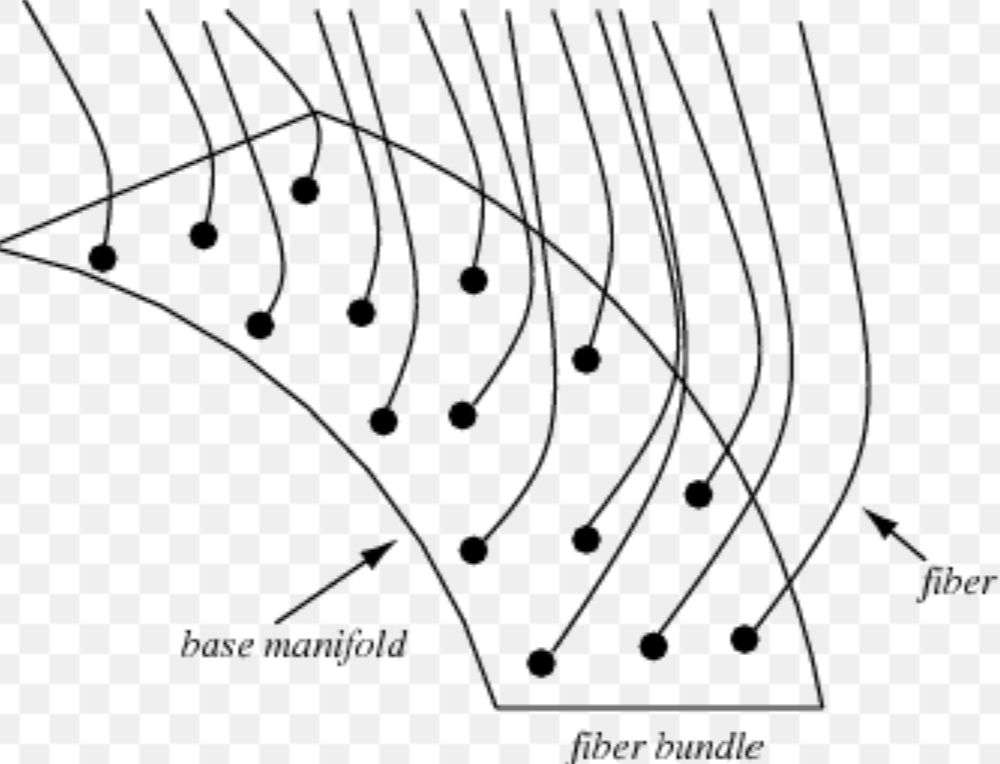
我们将每个网页在浏览器中渲染后,通过 js 计算出每个网页元素的一系列属性,主要包括元素的位置和大小。同时,我们构造了网页元素的更多有趣的隐含特征,譬如拓扑和语义相关的特征。目前,包括位置和大小在内,我们为每个网页元素构造了 100 多个独立特征。这样,一张网页可视作由很多个带属性的矩形组成的几何图形(Geometric graph),将全体网页压到一起,如同一捆报纸,万维网(WWW)可以被视作以三维流形为基空间的纤维丛。
你可以下载并试用:
// Given a portal url, automatically extract all the fields from out pages
java -jar exotic-standalone*.jar harvest https://shopee.sg/Computers-Peripherals-cat.11013247 -diagnose -refresh
更进一步,任意给一个列表页,我们能够对链出页面进行评估,来探测哪一组页面是由同一套模板生成的,从而其中的字段值能够被抽取出来。
// Auto arrange the links in a webpage
java -jar exotic-standalone*.jar arrange https://shopee.sg/Computers-Peripherals-cat.11013247
这样,原本需要手工编写几个甚至几十个正则表达式或者 CSS PATH 的网页抽取问题,现在只需要告诉系统列表页链接就行了,而满足这种要求的网页占据了互联网上绝大多数网页。
最后,我们为爬虫系统和数据分析系统配备了 SQL 引擎,这样,我们可以仅仅使用一条 SQL 语句就实现监控一个网站栏目,实时提取关键数据。事实上,配备 SQL 引擎后,互联网和本地数据库几乎就可以同等待了(除了互联网数据响应时间较久外)。
一个典型网页局部
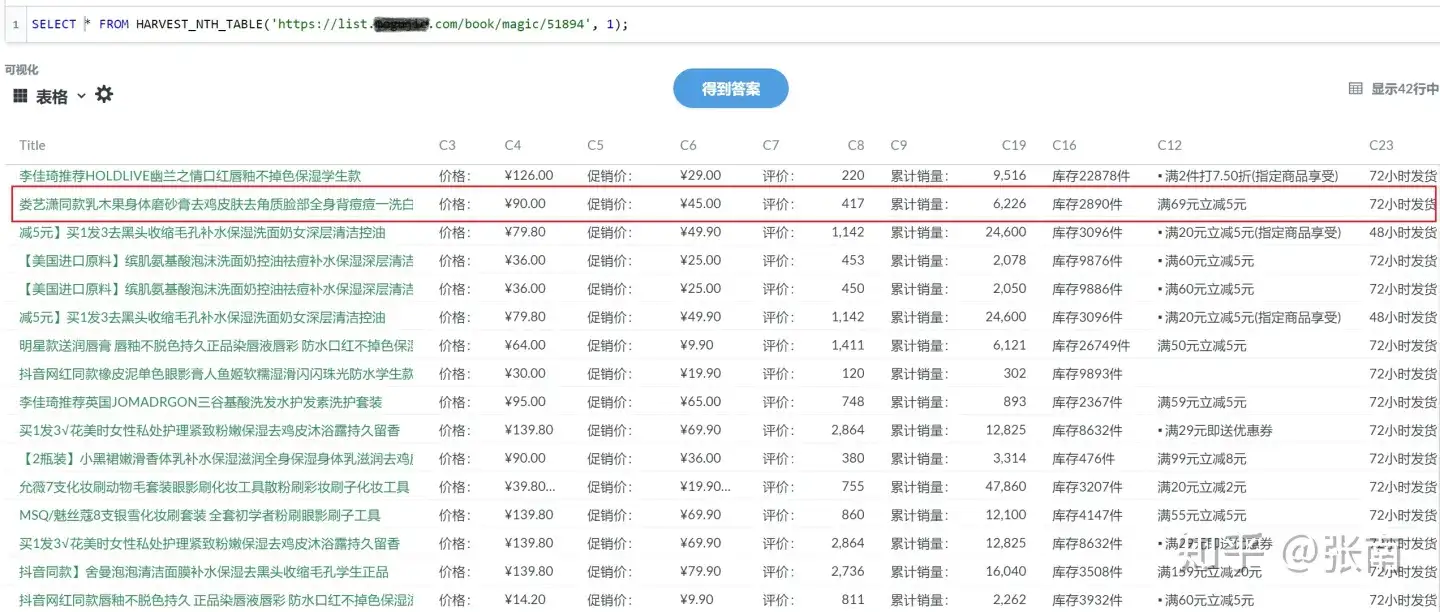
使用 PulsarRPA 的自动提取技术提取的数据
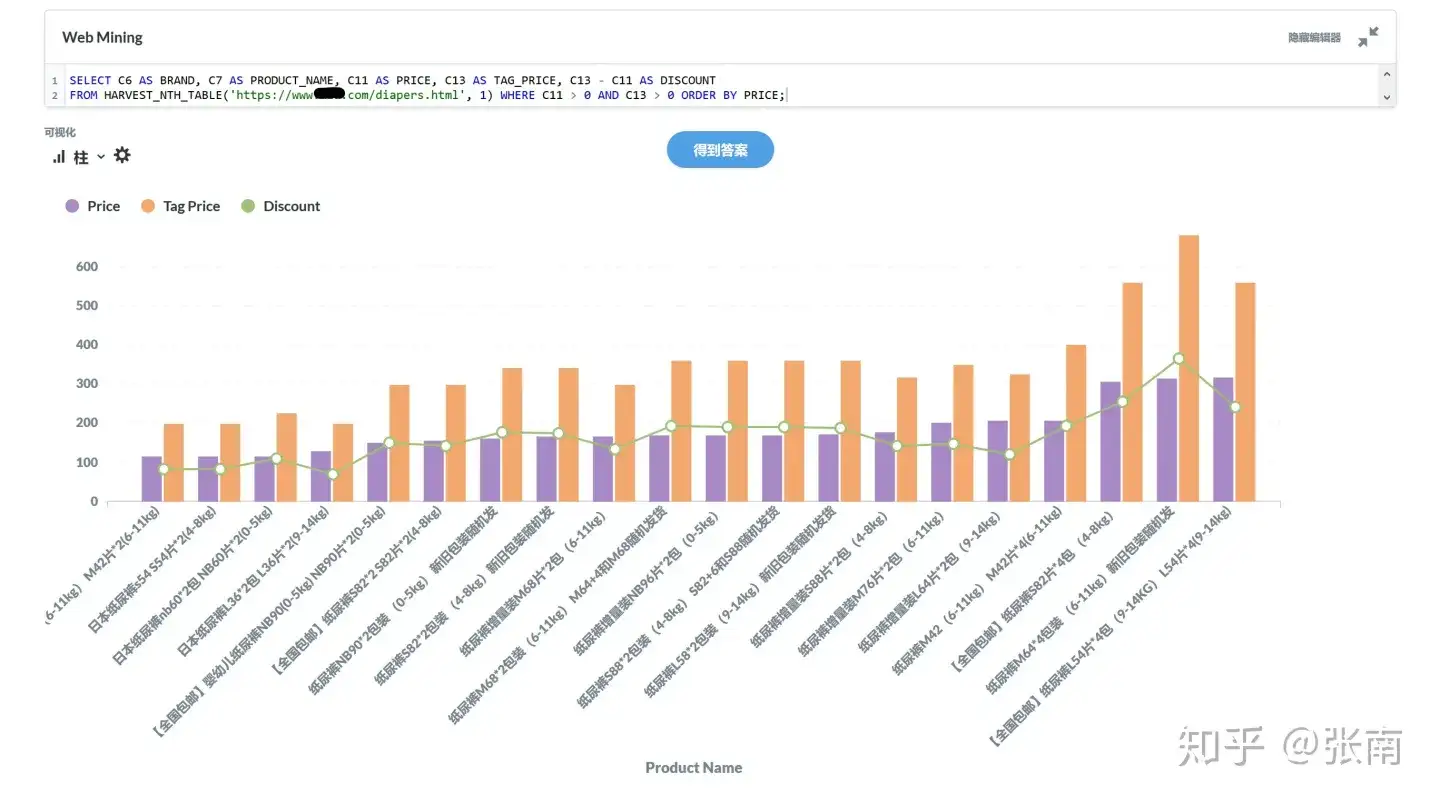
使用 PulsarRPA 的自动提取技术和 SQL 完全自动将互联网转变为图表
参考文献:
- WebFormer: The Web-page Transformer for Structure Information Extraction | Proceedings of the ACM Web Conference 2022
- OpenCeres for extract knowlege graph from Web
- FreeDOM: A Transferable Neural Architecture for Structured Information Extraction on Web Documents
相关文章:














 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









