







🥭 线程池
在之前的博客中,我们介绍到了进程,但是频繁的创建和销毁进程,资源消耗的非常大,于是我们引出了进程池和线程的概念,并详细的了解了线程的相关知识
线程虽然比进程轻量了不少,但是如果创建和销毁的频率进一步增加,资源的开销还是有的,为了把开销最小化我们又引出了线程池和协程的概念,协程我们不做过多介绍,我们主要了解线程池的概念
🥭线程池的原理
把创建好的线程,放到池子里,后面如果需要用到线程,直接从池子里取出,就不必利用系统进行申请了,就减少了资源的利用,当线程用完了,不会还给系统而是在放倒池子里,以备下次使用,这样创建和销毁线程就变的非常迅速了
到这里,我们不妨想一想,进程池也好线程池也罢,为什么放在池里就会比系统申请释放更高效呢?
在解决这个问题之前我们引进两个概念用户态和内核态
上图所示,这里面的应用程序就是我们的用户态,操作系统就是内核态.
在我们创造线程时,会调用start方法,这个方法就需要调用内核,代码进入内核时需要经过系统的调用,而且内核态中逻辑复杂,这样效率就大大降低了,而线程池是我们代码完成的,他是一个纯粹的用户态.
随之而来的问题-为什么用户态就比内核态操作效率要更高呢?
举个🌰
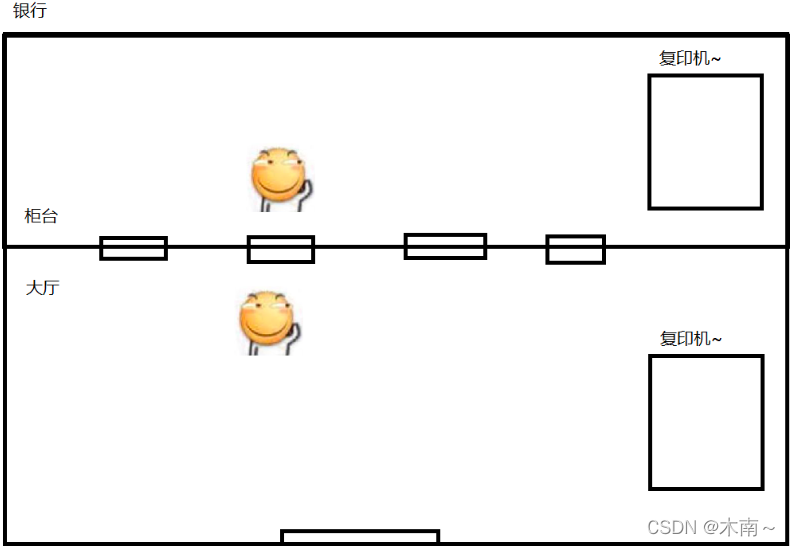
假设我们来银行办理业务,需要身份证的复印件,可是我们只带了原件,此时,银行人员和你说有两个方案
1.把身份证交给他,他去帮你复印,但是此时银行人员是不可控的,你不知道他在打印你的复印件之前做了什么,他可能去喝水,上厕所,或者去和妹子👧 聊天,然后再去打印你的复印件,于是你就像个小可爱😯 在那等了一下午,这就相当于内核态的操作,这种操作是不可控的
2.你自己去大厅的复印机去打印,不到十分钟你就回来了,业务也就办理完了,这种操作是可控的,也更高效
所以用户态的操作比内核态的操作更高效和迅速,同理使用线程池比系统自己调用更高效
🥭Java标准库的线程池
我们看一张图片来简单的了解一下
上述图片是ThreadPoolExecutor(线程池)的一个比较完整的构造方法,我们只需要了解第一个参数即可,其他的如果同学有兴趣可以自行了解
int corePoolSize(核心线程数)
在这里我么会引出一个经典的面试题,这不仅仅是一个面试题,也是日常开发中我们所需要了解的重要话题
使用线程池的时候,这里的线程数应该设为多少合适?
在网上会有许多不同的答案,其中最为常见的就是:假设你的机器是N核CPU,那么线程数就应该是1N,1.2N,1.5N…,这都是不正确的!!!只要回答出一个具体的数字就是不正确的!!!
正确的做法是,做个一个性能测试:
举个🌰 :
假设写一个服务器程序,服务器根据线程池,多线程的处理用户请求,此时就需要对服务器进行一些性能测试,比如构造一些请求,因为是性能测试,这里的请求就需要构造许多比如每秒发送500/1000/1500…根据一个合适的业务场景,构造一个合适的线程数
根据这里不同的线程数来观察程序处理的速度,还有CPU的占用率
- 线程数多了,速度就会变快,CPU占用率也会增加
2.线程数少了,速度就会变慢,CPU占用率也会减少
我们需要找到一个速度合理,CPU占用率也平衡的一个数值,而不是随意的就给出一个具体的数值来定义线程数的个数
在这里我们需要特意强敌一下,并不是线程数越多越好,我们也需要考虑CPU的占用率,并给CPU留下一定的空间,如果CPU占用率太高,此时虽然处理速度变快了但是CPU临近峰值忙、,如果CPU满了,系统可能也就挂了
标准库中还提供了一个简单版本的线程池
Executors,这是对Thread PoolExecutor的封装,提供了一些默认的参数,我们看一下这个Executors是咋用,然后模仿着自己写一个线程池
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(10);
pool.submit(new Runnable() {
@Override
public void run() {
System.out.println("aaa");
}
});
}
这是使用Executors实现的线程池,接下俩我们自己实现一个
🥭 自己实现一个线程池
- 直接使用Runnable来创建任务,并用阻塞队列来组织这些任务
class MyThreadPool{
//1.直接使用Runnable,不需要在创建类了;
//2.使用一个数据结构来组织这些任务
private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
}
- 描述一个线程,将队列中的任务取出来,放到线程里,并执行
// 3.描述一个工作线程,这个线程的工作就是把队列中的任务取出来并执行;
static class Worker extends Thread{
//当前线程中有若干Worker线程
private BlockingQueue<Runnable> queue = null;
public Worker(BlockingQueue queue){
this.queue = queue;
}
@Override
public void run() {
while(true){
try {
//循环的获取队列中的任务
//如果队列为空就堵塞,队列不为空,就获取到队列里的内容
Runnable runnable = queue.take();
//获取到执行任务
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
- 用List的数据结构将上面的这些线程组织起来
//4.创建一个数据结构来组织这些线程
private List<Worker> workers = new ArrayList<>();
public MyThreadPool(int n ){
for (int i = 0; i < n; i++) {
Worker worker = new Worker(queue);
worker.start();
workers.add(worker);
}
}
5.用一个方法把这些线程放到线程池中
//5.创建一个方法,允许程序猿把任务放到线程池中;
public void submit(Runnable runnable) {
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
这样一个简单的线程池就创建好了
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
class MyThreadPool{
//1.描述一个任务,直接使用Runnable,不需要额外创建类了;
// 2.使用一个数据结构来使用组织这些任务
private BlockingQueue<Runnable>queue = new LinkedBlockingQueue<>();
// 3.描述一个工作线程,这个线程的工作就是把队列中的任务取出来并执行;
static class Worker extends Thread{
//当前线程中有若干Worker线程
private BlockingQueue<Runnable> queue = null;
public Worker(BlockingQueue queue){
this.queue = queue;
}
@Override
public void run() {
while(true){
try {
//循环的获取队列中的任务
//如果队列为空就堵塞,队列不为空,就获取到队列里的内容
Runnable runnable = queue.take();
//获取到执行任务
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//4.创建一个数据结构来组织这些线程
private List<Worker> workers = new ArrayList<>();
public MyThreadPool(int n ){
for (int i = 0; i < n; i++) {
Worker worker = new Worker(queue);
worker.start();
workers.add(worker);
}
}
//5.创建一个方法,允许程序猿把任务放到线程池中;
public void submit(Runnable runnable) {
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
以上就是线程池的相关知识














 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









