







文章目录
前言
直接上题,由题理解各种思想以及函数,话不多说,直接开干
一、1126. 查询活跃业务
1.题目描述
事件表:Events
+---------------+---------+ | Column Name | Type | +---------------+---------+ | business_id | int | | event_type | varchar | | occurences | int | +---------------+---------+ 此表的主键是 (business_id, event_type)。 表中的每一行记录了某种类型的事件在某些业务中多次发生的信息。
写一段 SQL 来查询所有活跃的业务。
如果一个业务的某个事件类型的发生次数大于此事件类型在所有业务中的平均发生次数,并且该业务至少有两个这样的事件类型,那么该业务就可被看做是活跃业务。
查询结果格式如下所示:
Events table: +-------------+------------+------------+ | business_id | event_type | occurences | +-------------+------------+------------+ | 1 | reviews | 7 | | 3 | reviews | 3 | | 1 | ads | 11 | | 2 | ads | 7 | | 3 | ads | 6 | | 1 | page views | 3 | | 2 | page views | 12 | +-------------+------------+------------+ 结果表 +-------------+ | business_id | +-------------+ | 1 | +-------------+ 'reviews'、 'ads' 和 'page views' 的总平均发生次数分别是 (7+3)/2=5, (11+7+6)/3=8, (3+12)/2=7.5。 id 为 1 的业务有 7 个 'reviews' 事件(大于 5)和 11 个 'ads' 事件(大于 8),所以它是活跃业务。
2.解题思路
1)首先根据题目,必须要知道所有业务中的平均发生次数。所以需要计算每个业务的平均值,可以使用 AVG 函数和 GROUP BY 计算每个 event_type 的平均值。
2)拿到平均值后使用 JOIN 将新的数据和老数据根据 event_type 联合在一起。判断老数据的 occurences 是否大于平均值。
3)题目最后还要求至少有两个这样的事件类型,所以需要再用一次 GROUP BY 将每一个业务聚合并判断事件类型的数量。
3.代码实现
# Write your MySQL query statement below
SELECT e.business_id
FROM Events e
LEFT JOIN (
SELECT event_type, AVG(occurences) AS avgoc
FROM Events
GROUP BY event_type
) AS t
ON e.event_type = t.event_type
WHERE e.occurences > t.avgoc
GROUP BY business_id
HAVING COUNT(DISTINCT e.event_type) >= 2二、1532. 最近的三笔订单
1.题目描述
表:Customers
+---------------+---------+ | Column Name | Type | +---------------+---------+ | customer_id | int | | name | varchar | +---------------+---------+ customer_id 是该表主键 该表包含消费者的信息
表:Orders
+---------------+---------+ | Column Name | Type | +---------------+---------+ | order_id | int | | order_date | date | | customer_id | int | | cost | int | +---------------+---------+ order_id 是该表主键 该表包含id为customer_id的消费者的订单信息 每一个消费者 每天一笔订单
写一个 SQL 语句,找到每个用户的最近三笔订单。如果用户的订单少于 3 笔,则返回他的全部订单。
返回的结果按照 customer_name 升序排列。如果排名有相同,则继续按照 customer_id 升序排列。如果排名还有相同,则继续按照 order_date 降序排列。
查询结果格式如下例所示:
Customers+-------------+-----------+ | customer_id | name | +-------------+-----------+ | 1 | Winston | | 2 | Jonathan | | 3 | Annabelle | | 4 | Marwan | | 5 | Khaled | +-------------+-----------+Orders+----------+------------+-------------+------+ | order_id | order_date | customer_id | cost | +----------+------------+-------------+------+ | 1 | 2020-07-31 | 1 | 30 | | 2 | 2020-07-30 | 2 | 40 | | 3 | 2020-07-31 | 3 | 70 | | 4 | 2020-07-29 | 4 | 100 | | 5 | 2020-06-10 | 1 | 1010 | | 6 | 2020-08-01 | 2 | 102 | | 7 | 2020-08-01 | 3 | 111 | | 8 | 2020-08-03 | 1 | 99 | | 9 | 2020-08-07 | 2 | 32 | | 10 | 2020-07-15 | 1 | 2 | +----------+------------+-------------+------+ Result table: +---------------+-------------+----------+------------+ | customer_name | customer_id | order_id | order_date | +---------------+-------------+----------+------------+ | Annabelle | 3 | 7 | 2020-08-01 | | Annabelle | 3 | 3 | 2020-07-31 | | Jonathan | 2 | 9 | 2020-08-07 | | Jonathan | 2 | 6 | 2020-08-01 | | Jonathan | 2 | 2 | 2020-07-30 | | Marwan | 4 | 4 | 2020-07-29 | | Winston | 1 | 8 | 2020-08-03 | | Winston | 1 | 1 | 2020-07-31 | | Winston | 1 | 10 | 2020-07-15 | +---------------+-------------+----------+------------+ Winston 有 4 笔订单, 排除了 "2020-06-10" 的订单, 因为它是最老的订单。 Annabelle 只有 2 笔订单, 全部返回。 Jonathan 恰好有 3 笔订单。 Marwan 只有 1 笔订单。 结果表我们按照 customer_name 升序排列,customer_id 升序排列,order_date 降序排列。
2.解题思路
1)获取每个用户的订单, 按照时间顺序逆序——使用
ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY order_date DESC) AS rnk2)找到每个用户的最近三笔订单。如果用户的订单少于 3 笔,则返回他的全部订单
LEFt JOIN Customers c
ON t.customer_id = c.customer_id
WHERE t.rnk <= 33)按照customer_name 升序排列 ustomer_id 升序排列 order_date 降序
3.代码实现
# Write your MySQL query statement below
SELECT
c.name AS customer_name,
t.customer_id,
t.order_id,
t.order_date
FROM (
SELECT
customer_id,
order_id,
order_date,
ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY order_date DESC) AS rnk
FROM Orders
) AS t
LEFt JOIN Customers c
ON t.customer_id = c.customer_id
WHERE t.rnk <= 3
ORDER BY customer_name, customer_id,order_date DESC三、1949. 坚定的友谊
1.题目描述
表名: Friendship
+-------------+------+ | 列名 | 类型 | +-------------+------+ | user1_id | int | | user2_id | int | +-------------+------+ (user1_id, user2_id) 是这个表的主键。 这张表的每一行都表示用户 user1_id 和 user2_id 是朋友。 请注意,user1_id < user2_id。
如果 x 和 y 为朋友且他们至少有三个共同的朋友 ,那么 x 和 y 之间的友谊就是坚定的。
写一个 SQL 查询来找到所有的坚定的友谊。
注意,结果表不应该包含重复,并且 user1_id < user2_id。
以任何顺序返回结果表。
查询结果的格式在下面的例子中。
示例 1:
输入: 表 Friendship: +----------+----------+ | user1_id | user2_id | +----------+----------+ | 1 | 2 | | 1 | 3 | | 2 | 3 | | 1 | 4 | | 2 | 4 | | 1 | 5 | | 2 | 5 | | 1 | 7 | | 3 | 7 | | 1 | 6 | | 3 | 6 | | 2 | 6 | +----------+----------+ 输出: +----------+----------+---------------+ | user1_id | user2_id | common_friend | +----------+----------+---------------+ | 1 | 2 | 4 | | 1 | 3 | 3 | +----------+----------+---------------+ 解释: 用户 1 和 2 有 4 个共同的朋友(3,4,5,和 6)。 用户 1 和 3 有 3 个共同的朋友(2,6,和 7)。 我们没有包括用户 2 和 3 的友谊,因为他们只有两个共同的朋友(1 和 6)。
2.解题思路
1)建立好友表t: 这表里面会反映每个用户他的id和他的好友的id 即运行代码如下:
WITH t AS (
SELECT user1_id AS user_id, user2_id AS friend
FROM Friendship
UNION ALL
SELECT user2_id, user1_id
FROM Friendship
)
2)寻找共同好友: 对于上面的好友表,我们同时命别名,使之称为两张表,这两张表连接时,用user_id进行连接,前表的id < 后表的id。这样的话我们就得到,我们的所有组合啦!!! 现在要把两张表后面的friend_id进行等值匹配,这样我们不就找到这些组合里面的哪些friend_id是相同的! 那么接下来,按照这个组合,对共同好友进行数理求和,那不就很简单了吗?
【关键/要点】 1)建立好友表 2)注意命成:user_id和friend_id,这样想象成一个是标识一个是属性,这样更容易解决这个问题,以不至于绕晕。 (这样命名的话,那么相当于一次考试中:user_id——学生姓名;friend_id——考试成绩)
3.代码实现
WITH t AS (
SELECT user1_id AS user_id, user2_id AS friend
FROM Friendship
UNION ALL
SELECT user2_id, user1_id
FROM Friendship
)
SELECT
t1.user_id AS user1_id,
t2.user_id AS user2_id,
COUNT(DISTINCT t1.friend) AS common_friend
FROM t t1
LEFT JOIN t t2
ON t1.user_id < t2.user_id AND t1.friend = t2.friend
WHERE (t1.user_id, t2.user_id) IN (
SELECT *
FROM Friendship
)
GROUP BY t1.user_id, t2.user_id
HAVING COUNT(DISTINCT t1.friend) >= 3四、1709. 访问日期之间最大的空档期
1.题目描述
表: UserVisits
+-------------+------+ | Column Name | Type | +-------------+------+ | user_id | int | | visit_date | date | +-------------+------+ 该表没有主键。 该表包含用户访问某特定零售商的日期日志。
假设今天的日期是 '2021-1-1' 。
编写 SQL 语句,对于每个 user_id ,求出每次访问及其下一个访问(若该次访问是最后一次,则为今天)之间最大的空档期天数 window 。
返回结果表,按用户编号 user_id 排序。
查询格式如下示例所示:
UserVisits 表:
+---------+------------+
| user_id | visit_date |
+---------+------------+
| 1 | 2020-11-28 |
| 1 | 2020-10-20 |
| 1 | 2020-12-3 |
| 2 | 2020-10-5 |
| 2 | 2020-12-9 |
| 3 | 2020-11-11 |
+---------+------------+
结果表:
+---------+---------------+
| user_id | biggest_window|
+---------+---------------+
| 1 | 39 |
| 2 | 65 |
| 3 | 51 |
+---------+---------------+
对于第一个用户,问题中的空档期在以下日期之间:
- 2020-10-20 至 2020-11-28 ,共计 39 天。
- 2020-11-28 至 2020-12-3 ,共计 5 天。
- 2020-12-3 至 2021-1-1 ,共计 29 天。
由此得出,最大的空档期为 39 天。
对于第二个用户,问题中的空档期在以下日期之间:
- 2020-10-5 至 2020-12-9 ,共计 65 天。
- 2020-12-9 至 2021-1-1 ,共计 23 天。
由此得出,最大的空档期为 65 天。
对于第三个用户,问题中的唯一空档期在 2020-11-11 至 2021-1-1 之间,共计 51 天
2.解题思路
对于一张表的一行数据而言,在其之上的是Lag, 在其之下的是Lead
+---------+------------+
LAG()
------------------------
current_row
------------------------
LEAD()
+-----------------------+
所以我们第一个想到就是用LEAD()函数。我们按照时间排序把下一行的时间找到,然后就可以算window差了。 解释一下参数:
LEAD(col, offset, default)
col - 指你要操作的那一列
offset - 偏移几行,如果是1就是下1行,以此类推
default - 如果下一行不存在,用什么值填充
在这道题中,我们刚好要算最后一个时间点和2021-01-01的windows_diff,所以直接填上即可 因此我们可以得到如下代码:
LEAD(visit_date, 1, '2021-1-1')
OVER (PARTITION BY user_id ORDER BY visit_date) AS next_day
我们已经算到了diff了,接下来只要按组求最大的那个即可,很容易联想到GROUP BY
3.代码实现
SELECT
user_id,
MAX(DATEDIFF(next_day, visit_date)) AS biggest_window
FROM (
SELECT
user_id,
visit_date,
LEAD(visit_date, 1, '2021-1-1') OVER(PARTITION BY user_id ORDER BY visit_date) AS next_day
FROM UserVisits
) AS T
GROUP BY user_id五、1867. 最大数量高于平均水平的订单
1.题目描述
OrdersDetails 表
+-------------+------+ | Column Name | Type | +-------------+------+ | order_id | int | | product_id | int | | quantity | int | +-------------+------+ (order_id, product_id) 是此表的主键。 单个订单表示为多行,订单中的每个产品对应一行。 此表的每一行都包含订单id中产品id的订购数量。
您正在运行一个电子商务网站,该网站正在寻找不平衡的订单。不平衡订单的订单最大数量严格大于每个订单(包括订单本身)的平均数量。
订单的平均数量计算为(订单中所有产品的总数量)/(订单中不同产品的数量)。订单的最大数量是订单中任何单个产品的最高数量。
编写SQL查询以查找所有不平衡订单的订单id。
按任意顺序返回结果表。
查询结果格式如下例所示。
示例:
输入: OrdersDetails 表: +----------+------------+----------+ | order_id | product_id | quantity | +----------+------------+----------+ | 1 | 1 | 12 | | 1 | 2 | 10 | | 1 | 3 | 15 | | 2 | 1 | 8 | | 2 | 4 | 4 | | 2 | 5 | 6 | | 3 | 3 | 5 | | 3 | 4 | 18 | | 4 | 5 | 2 | | 4 | 6 | 8 | | 5 | 7 | 9 | | 5 | 8 | 9 | | 3 | 9 | 20 | | 2 | 9 | 4 | +----------+------------+----------+ 输出: +----------+ | order_id | +----------+ | 1 | | 3 | +----------+ 解释: 每份订单的平均数量为: - order_id=1: (12+10+15)/3 = 12.3333333 - order_id=2: (8+4+6+4)/4 = 5.5 - order_id=3: (5+18+20)/3 = 14.333333 - order_id=4: (2+8)/2 = 5 - order_id=5: (9+9)/2 = 9 每个订单的最大数量为: - order_id=1: max(12, 10, 15) = 15 - order_id=2: max(8, 4, 6, 4) = 8 - order_id=3: max(5, 18, 20) = 20 - order_id=4: max(2, 8) = 8 - order_id=5: max(9, 9) = 9 订单1和订单3是不平衡的,因为它们的最大数量超过了它们订单的平均数量。
2.解题思路
本题关键在于建立一个临时表来使得问题简单化:
WITH t AS (
SELECT order_id, MAX(quantity) AS maxq, AVG(quantity) AS avgq
FROM OrdersDetails
GROUP BY order_id
)3.代码实现
# Write your MySQL query statement below
#将复杂问题简单化 使用临时表
WITH t AS (
SELECT order_id, MAX(quantity) AS maxq, AVG(quantity) AS avgq
FROM OrdersDetails
GROUP BY order_id
)
SELECT order_id
FROM t
WHERE maxq > (SELECT MAX(avgq) FROM t)六、1459. 矩形面积
1.题目描述
表: Points
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | x_value | int | | y_value | int | +---------------+---------+ id 是该表主键 每个点都用二维坐标 (x_value, y_value) 表示
写一个 SQL 语句,报告由表中任意两点可以形成的所有 边与坐标轴平行 且 面积不为零 的矩形。
结果表中的每一行包含三列 (p1, p2, area) 如下:
p1和p2是矩形两个对角的id- 矩形的面积由列
area表示
请按照面积 area 大小降序排列;如果面积相同的话, 则按照 p1 升序排序;若仍相同,则按 p2 升序排列。
查询结果如下例所示:
Points 表: +----------+-------------+-------------+ | id | x_value | y_value | +----------+-------------+-------------+ | 1 | 2 | 7 | | 2 | 4 | 8 | | 3 | 2 | 10 | +----------+-------------+-------------+ Result 表: +----------+-------------+-------------+ | p1 | p2 | area | +----------+-------------+-------------+ | 2 | 3 | 4 | | 1 | 2 | 2 | +----------+-------------+-------------+
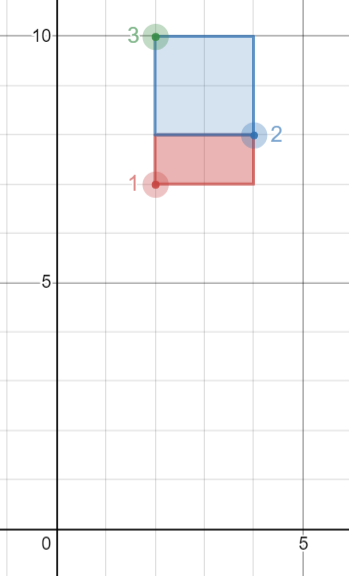
p1 = 2 且 p2 = 3 时, 面积等于 |4-2| * |8-10| = 4 p1 = 1 且 p2 = 2 时, 面积等于 ||2-4| * |7-8| = 2 p1 = 1 且 p2 = 3 时, 是不可能为矩形的, 面积等于 0
2.解题思路
本题主要使用ABS()函数进行绝对值运算,下面是整体思路:
题目说是任意两点,但其实有一些限制在其中:
1)首先不能和自身组合,其次不能向两边延伸,否则会出现重复计算,所以我们只能使用不等式连接
2)其次,面积不得为0,面积其实就是两点横纵坐标之差的绝对值的乘积
3)最简单的方法是使用HAVING子句,因为面积是查询之后得到的字段信息,通过HAVING才能对其进行限制,所以我们使用HAVING > 0就能解决
4)其实WHERE的写法性能会更好一些,因为HAVING是针对所有计算出来的结果进行限制,而WHERE则是在计算之前进行限制,所以节省了部分开销,所以我选择使用看起来更麻烦的WHERE
3.代码实现
# Write your MySQL query statement below
#WHERE 的算法性能好过HAVING
SELECT a.id AS p1,
b.id AS p2,
ABS((a.x_value - b.x_value) * (a.y_value - b.y_value)) AS area
FROM Points a
LEFT JOIN Points b
ON a.id < b.id
WHERE a.x_value != b.x_value
AND a.y_value != b.y_value
ORDER BY area DESC, p1, p2七、1747. 应该被禁止的 Leetflex 账户
1.题目描述
表: LogInfo
+-------------+----------+ | Column Name | Type | +-------------+----------+ | account_id | int | | ip_address | int | | login | datetime | | logout | datetime | +-------------+----------+ 该表是没有主键的,它可能包含重复项。 该表包含有关Leetflex帐户的登录和注销日期的信息。 它还包含了该账户用于登录和注销的网络地址的信息。 题目确保每一个注销时间都在登录时间之后。
编写一个SQL查询语句,查找那些应该被禁止的Leetflex帐户编号 account_id 。 如果某个帐户在某一时刻从两个不同的网络地址登录了,则这个帐户应该被禁止。
可以以 任何顺序 返回结果。
查询结果格式如下例所示。
示例 1:
输入: LogInfo table: +------------+------------+---------------------+---------------------+ | account_id | ip_address | login | logout | +------------+------------+---------------------+---------------------+ | 1 | 1 | 2021-02-01 09:00:00 | 2021-02-01 09:30:00 | | 1 | 2 | 2021-02-01 08:00:00 | 2021-02-01 11:30:00 | | 2 | 6 | 2021-02-01 20:30:00 | 2021-02-01 22:00:00 | | 2 | 7 | 2021-02-02 20:30:00 | 2021-02-02 22:00:00 | | 3 | 9 | 2021-02-01 16:00:00 | 2021-02-01 16:59:59 | | 3 | 13 | 2021-02-01 17:00:00 | 2021-02-01 17:59:59 | | 4 | 10 | 2021-02-01 16:00:00 | 2021-02-01 17:00:00 | | 4 | 11 | 2021-02-01 17:00:00 | 2021-02-01 17:59:59 | +------------+------------+---------------------+---------------------+ 输出: +------------+ | account_id | +------------+ | 1 | | 4 | +------------+ 解释: Account ID 1 --> 该账户从 "2021-02-01 09:00:00" 到 "2021-02-01 09:30:00" 在两个不同的网络地址(1 and 2)上激活了。它应该被禁止. Account ID 2 --> 该账户在两个不同的网络地址 (6, 7) 激活了,但在不同的时间上. Account ID 3 --> 该账户在两个不同的网络地址 (9, 13) 激活了,虽然是同一天,但时间上没有交集. Account ID 4 --> 该账户从 "2021-02-01 17:00:00" 到 "2021-02-01 17:00:00" 在两个不同的网络地址 (10 and 11)上激活了。它应该被禁止.
2.解题思路
根据题意,对banned account的定义是,如果一个account在不同ip下的登录时间出现交集,则会被判定为banned.
这里所谓的登录时间出现交集是比较关键的信息。
如果我们用ab来表示同一账号的不同ip地址,那么ab的登录时间满足如下关系:
A.login <= B.logout AND A.Logout >= B.login则可以说明ab这两个ip地址的登录时间发生了交集,所以这个账号是banned account.
所以可以使用自连接进行连接,让每一个账号的不同ip地址进行两两对比,选出有时间交集的账号。
3.代码实现
SELECT DISTINCT A.account_id
FROM LogInfo A, LogInfo B
WHERE A.account_id = B.account_id
AND A.ip_address !=B.ip_address
AND A.login <= B.logout
AND A.Logout >= B.login















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











