








问 1:现在语音识别落地比较难的点?
答:目前来说,语音识别落地的难点有中英混、方言、预训练模型等。首先,中英混是一个语音识别落地的难点,现在有很多研究在做;其次,方言也是一个难点,这里面主要是数据的问题,像是低资源的模型的构建,就是在数据比较少的情景如何构建语音模型;其他的还有类似Wav2vec这种预训练模型,如果模型要做得比较大,如何去做实时的流式推理,这些都是目前研究的一些点,在最近也都有一些进展。
问 2:学了WeNet可以做点什么?比如说在科研实验方面,能够提供那些帮助?
答:WeNet这个工具包本身的定位不是提供一些基础的组件让大家去实践一些新的算法,它最大的特点是讲究落地性,它会总结并集成目前工业界最有效的一些实践的方式,相当于帮大家做了筛选,直接跳过一些坑。
对于语音识别的初学者来说,可以通过WeNet构建起自己对端到端的知识体系,虽然只通过使用WeNet不能把这个知识体系建立完全,但是它可以作为一个骨干,我们可以基于这个骨干补充更多的知识。
如果想要用WeNet做科研也没有问题,现在有很多实验室的同学和工业界的朋友都会在WeNet的基础上做一些改造,然后发一些文章。而且做科研试验肯定是需要了解一些基础的模型的架构和实现,虽然也有一些其它的工具包可以帮助我们来了解这些知识,但是WeNet会更全面,所以可以把WeNet作为一个基础的Framework,把它搞懂了对做科研试验肯定是有帮助的。
问 3:现在语音识别主流的方案是什么?主流的落地方案又是什么呢?
答:目前开源语音识别的主流的方案有Kaldi、 K2、PaddleSpeech、ESPnet 、WeNet。
关于主流的落地方案是什么,这个要分开说,如果想搞科研,那么ESPnet就会更适合一些,WeNet也可以;如果要产品落地的话,那么目前来说WeNet是走在最前面的。
首先,WeNet针对落地化的一些问题,提出了语言模型、热词等不少解决方案,接下来也会继续优化热词,后续可能会出一个热词增强的2.0,大家也可以关注一下。其次是能够很简单地把WeNet部署起来,用到一个真实的业务上面去。
问 4:如果想充分理解一个预训练模型的算法,比如aishell预训练模型,应该从哪入手?
答:如果是想去研究模型结构以及模型的训练,那么可以把WeNet的recipe跑通,然后再明确每一个脚本的输入、输出、模型结构。也可以尝试调参,观察模型的收敛效果,或者模型损失的下降速度会不会更快。
如果是想去研究一下Runtime的话,这门课(《WeNet语音识别实战》)会带大家去把整个Runtime跑通,其中也包括Runtime的调试。如果你想更深入的话,你也可以针对每一行代码,了解底层逻辑,只要你把整个调试跑起来之后,这个问题也都是比较简单的。
那么当你把整个Rimetime跑下来之后,大家也可以去参考WeNet公众号上面的一些推送。在整个WeNet的开发过程中,针对于每一个功能点,都会有一篇推送介绍这个功能点的实现过程,比如说热词的实现过程,你可以根据代码和推送理解WeNet的整个逻辑。在这个基础之上,如果你有一些比较好的想法,你也可以去做简单的改进。
Runtime的改动是比较简单的,即使对于C++不是太熟悉,也可以在代码里面找类似的部分,把它拷贝一下就能够去完成你的想法。大家也可以看一下我们Github上有不少的PR,也是一些其他同学的一些改动,不是特别复杂,代码量不多。
问 5:端到端模型对于领域文本优化有什么方案可以在实际应用中使用的?
答:可以使用领域的语言模型,比如在语音相关的场景可以使用语音识别的文本统计一个语言模型,在识别过程中对语言模型的内容进行增强。热词也可以一定程度上作为解决该问题的补充。
问6:当前最新的比较好的算法好像也就是 Conformer了,还有比这更好的吗? 如果找不到更好的算法,应该从哪些方面来优化预训练模型呢?
答:Conformer可以认为是Transformer的一个变种,Transformer在全局建模方面有比较好的性能。因为语音识别模型的性能不能只关注WER,还需要关注模型的大小和延迟,如果想要优化模型也可以从这两方面入手,因为对于模型的落地化来说,延迟是一个很重要的性能。如果你看过WeNet的论文之后发现WeNet的建模会让延迟比较大,并且有一个好的想法能够降低它的延迟,你也可以尝试修改。
问 7:WeNet有什么独特的地方吗?比如流识别方面。
答:WeNet里制作、使用了比U2更优化的U2++算法解决流式的问题。具体思想是做两次识别,第一遍利用CTC的结果,第二遍利用Attention Decoder做rescoring,整体实现模型架构上的流式。Conformer、Transformer模块中的Self-Attention本身是不能做流式识别的,在WeNet中通过dynamic chunk training的方式实现了Conformer和Transformer的流式。
问 8:热词增强和热词唤醒在实现上的区别是什么?
答:热词唤醒即为Hot Word或者Wake-up Word,是一个轻量级的关键词检测,通常部署在端侧的设备上,如音响、手机等。它占用资源很小,网络规模一般在几十k到几百k。而热词增强是语音识别中的一项技术,它对一些特定场景中特定名词做实时的定向增强,一般会部署在算力比较强劲的端侧。
问 9:目前WeNet的时间戳方案不太准确(一是静音的判断不准确,二是字与字的时间戳是连着的,无论中间静音有多大),请问有什么方案可以提高时间戳的准确度吗?
答:时间戳是根据CTC判断,本身CTC在这方面有一定的滞后性或者漂移,这个是导致时间戳不准确的一个原因。在后处理时,初版WeNet考虑到字与字之间的时间戳是连着的这样的问题,在最新版的WeNet已经修正合并到master的分支中。
问 10:请问现在工业上用传统的技术多还是端到端的技术多啊?
答:目前来说这两种都有。但是现在有一种趋势,这种趋势大致是从去年开始的,就是从传统的混合框架迁移到端到端的框架上面去。有一些公司研究的比较快或者说技术迭代的比较快,已经完成迁移了;有一些公司还在验证或者说迁移的过程中,可能再过一两年基本上大部分就都迁移到端到端了。
因为端到端这个框架优势比较明显:第一,搭系统的门槛低了,第二,端到端在性能方面已经超越了传统的混合框架,虽然端到端还有它本身的一些问题,如在工业上落地的时候需要考虑很多的问题,包括领域迁移的问题、热词的问题等等。但是大的趋势肯定是往端到端上迁移的。
问 11:WeNet 转 onnx 的时候要拆成几个模型导出,可以合并为一个吗?
答:不可以,因为onnxruntime 不支持。
问 12:热词的文件是什么结构?
答:一个文本文件,每一行表示一个热词,不需要提前分词。
问 13:web socket server 怎么启用热词?
答:指定两个参数:--context_path 和 --context_score
问 14:-context_score 这个值是什么范围?一般多少合适?
答:需要手动调,可以设置为 3 ~ 10。
问 15:web socket server支持语言模型吗?
答:支持,参数的定义都在 decoder/params.h 里面,可以仔细看一下。
问 16:在流式识别中,如何解决背景噪音带来的干扰?
答:通常的做法是给训练集加噪声,真实的加噪数据训练更好,也可以模拟加噪数据。
问 17:一般外呼场景都是8k采样率的录音, 假设模型都一样 ,8k和16k不同采样率训练出的模型准确率会有差距吗?
答:在模型、语料、信道等信息相同的情况下,如果只是经过降采样后训练模型,两种采样率的模型结果是有差距的,正常情况下,8k的结果没有16k的好。
问 18:不把16k降到8k维护一套8k的是因为16k准确率高吗?如果有存储需求16k意味着存的音频占的硬盘翻倍了,rtf也会下降吧?
答:维护两套肯定比维护一套的成本高。存的时候按原始采样率存就行了,不会有额外存储,8k转16k这个过程代价不高。
问 19:WeNet进行一些简单的优化rtf大概能到多少?
答:0.1左右。
问 20:web socket server,用的onnx的模型,加上热词后,score从3-10都试了下,没有起作用。onnx模型,是从非流模型导出的,会是这个原因吗?
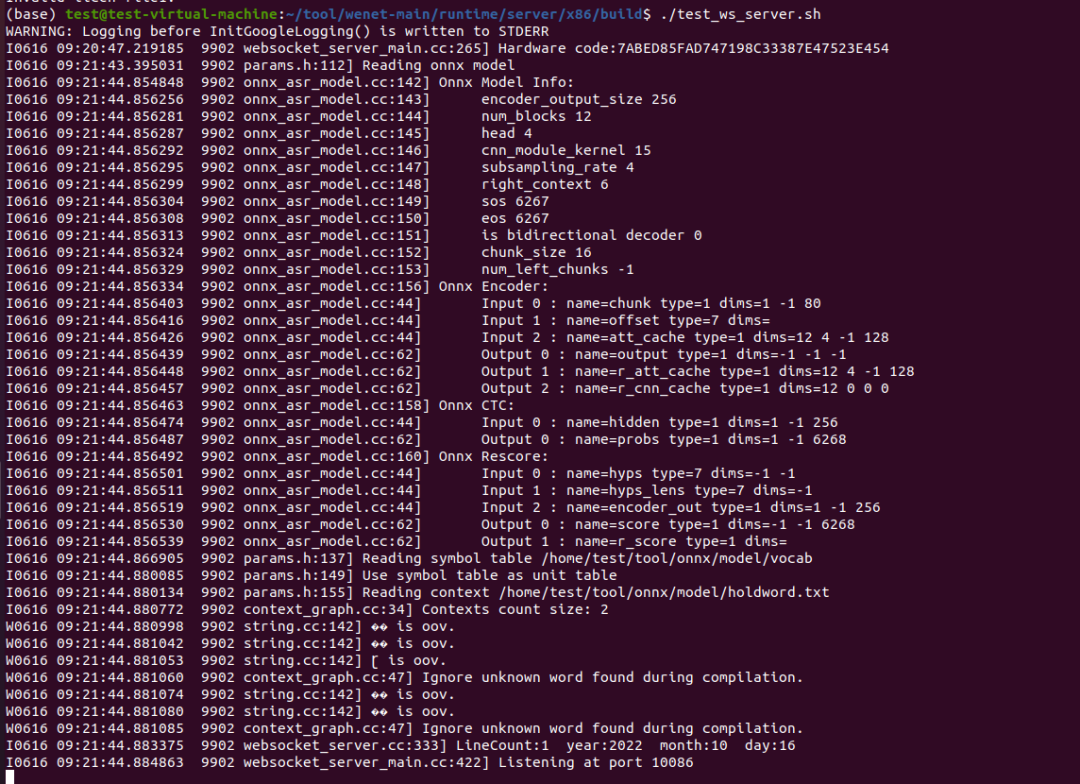


答:热词跟是否流式没有关系,根据运行结果来看,两个热词里均包含OOV,都被跳过了。热词文件格式有问题,应该是UTF-8。
问 21:热词标记,但是最后没有实现是因为什么?
答:热词并不能确保一定成功,因为解码过程中首先取了概率前十的字,如果热词不在这里面,分数再高也没用。
问 22:CTC的尖峰效应,是不是可以理解为:目标函数约束前面的神经网络,将一个词的多帧信息,集中到了'尖峰'这一帧。
答:在输出中如果输出错误会有较大的罚分,将不确定的结果不指定到具体的帧,输出blank,确定的结果输出,迭代过程中正确的结果就越突出,准确率越高。
问 23:web socket server 配置了 热词的文本文件后,如果有追加或更新,需要重启服务么?还是自动就生效了?
答:需要重启重新构图的,如果希望热更新,需要自己做一些开发的工作,如通过增加一个 热词更新 的命令,让web socket server重新构图。
问 24:为什么这里算概率一定要把这些全部加起来,为什么不能像一个一个地算,求出最大概率为声学对齐结果呢?
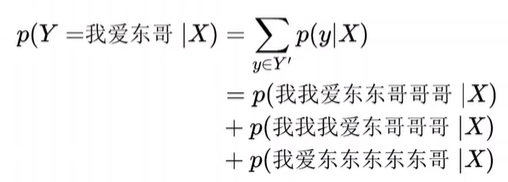
答:如果你的模型参数已经优化好了,最大概率是声学对齐,如果是一个随机初始化的模型,最大概率的那个系列只是一个随机对齐。
假如你的初始模型,在标注约束下预测出的是“我我我我我我我爱东哥”,然后你又把这个输出当作是正确对齐,那你的模型无论怎么学。学到的还是这个输出。
如果只是从概率公式上看,“文本标注=我爱东哥”这个事件,等价于其“所有个可能的对齐”组成的事件,所以可以写成这些子事件的概率之和。
问 25:一般这种websocket 如何做高并发,有没有好的解决方案?
答:需要再包装一层上层服务,可以用nginx代理,nginx可以代理ws,后面部署多个ws server。
热词并不能确保一定成功,因为解码过程中首先取了概率前十的字,如果热词不在这里面,分数再高也没用。
WeNet是目前工业界最流行的开源端到端语音识别系统,也是学习端到端语音识别的最佳实践项目(代码运算)。语音识别的学习者和从业者,可以通过学习课程高效全面的掌握Wenet的基本原理和实战方法,降低自己摸索的成本,快速构建出高性能的语音识别系统。

语音之家社区为了更好地服务AI语音开发者,推出了AI工匠学堂——助力AI语音开发者从0到1的学习平台,提供更符合语音技术开发者的体系化课程,从语音识别、语音合成、声纹识别、语音唤醒、开源工具、开源数据、前沿技术七大研究领域中梳理出阶梯式学习路径。适用于不同层级的语音技术开发者,从入门到高级进阶完成整个技术体系的学习。















 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









