







千呼万唤始出来,语音的 ChatGPT 时刻终于来了!当 ChatGPT 引爆世界后,语音的从业者就一直在期待、想象、实验、推进基于 LLM 的语音交互应用和技术,OpenAI 自己也推出了 Whisper 识别、合成的语音模型,但之前更多的是持续性的改进和小的创新,远未有当初 ChatGPT 那样颠覆性的体验和效果。今天,仍然是 OpenAI,AI 行业的风向标,他来了,带着 GPT-4o 来了!
GPT-4o 中有很多方面的改进,然而,最大最颠覆性的,还是在语音交互。
对语音交互来讲,GPT-4o 新在哪里?
现场的演示中,Mira 也提到了这个问题,亚裔小伙给出的答案是 1)支持打断 2)实时交互 3)懂你的情绪;在回复方面,则可以以更多的风格更多的情感合成声音。这里我们再进一步抽象和拓展一下几个特点。
极致端到端,交互体验非常酷炫,非常丝滑,并很好的支持打断。对比以前的交互系统,需要唤醒、识别、自然语言理解、查询、回复生成、TTS 多个模块,每个模块都是单独的模型、都是独立的团队在做,信息逐模块在损失,前面一个模块出错,后面基本就全错。例如识别模块是把语音转文字,交给下游处理,在转文字过程中,语音的其他信息全都丢掉了,例如说话人的音调、性别、情绪、背景音乐、噪声,有没有其他人说话等等。现在 GPT-4o 一个模型端到端全搞定,能极限的感知和理解,如现场演示中,GPT-4o 能理解和分辨到人大口的喘气、呼气和吸气。
极致低延迟,看现场的实时演示,模型反应极快。回看发布会的视频时,弹幕上清一色的好快!OpenAI 的技术博客中给出的数字是最低 232 ms,平均 320 ms 就能给出回复,已经非常接近真人交互时的响应速度。(这里引用了一篇文章,其在十个语种上统计了人类自然对话时延时大概在 250ms 左右)。
对称多模态,输入输出都可以是文本、语音和视觉,最终模型能力更全栈,更能做全场景的处理。语音是首次作为独立模态引入到 GPT 模型中,GPT-4o 是 OpenAI 第一次尝试做文本、视觉和语音的整合,从统一模态上来讲,这是迈向 AGI 的一大步。
GPT-4o 是如何做到的?
那么,GPT-4o 是怎么练成的,在语音交互中的几个特点是如何做到的呢?
如何做到端到端?个人觉得核心在于路径和节奏的把控。OpenAI 从成立之初,就把 AGI 作为自己的使命和终极追求,但在路径上,OpenAI 却是非常的务实。所以,我们看到刚开始有文本的 GPT,图像生成的 DALL.E,然后在 GPT-4 中做了图像模态的输入,可以做图像的理解了;在语音这个任务上,刚开始进攻语音交互中最重要的两个独立的任务,识别的 Whisper 和基于大模型的合成,这两个工作在识别合成的细分行业中,也是战术核弹的存在,直到今天水道渠成的把识别、合成等的语音能力集成进 GPT-4o,就成了战略核弹。在路径上,在今天,行业在积累了领域的知识,领域的技术,再往 LLM 中接入该模态和能力的时候,方法上已不是个特别大的问题,这样的工作特别多,对 OpenAI 来讲就更不是个问题。在节奏上,OpenAI 的每次新技术发布总是恰逢其时,每次都有不一样的创新,当行业陷入停滞的时候,大家仿佛都在等 OpenAI 放大招。
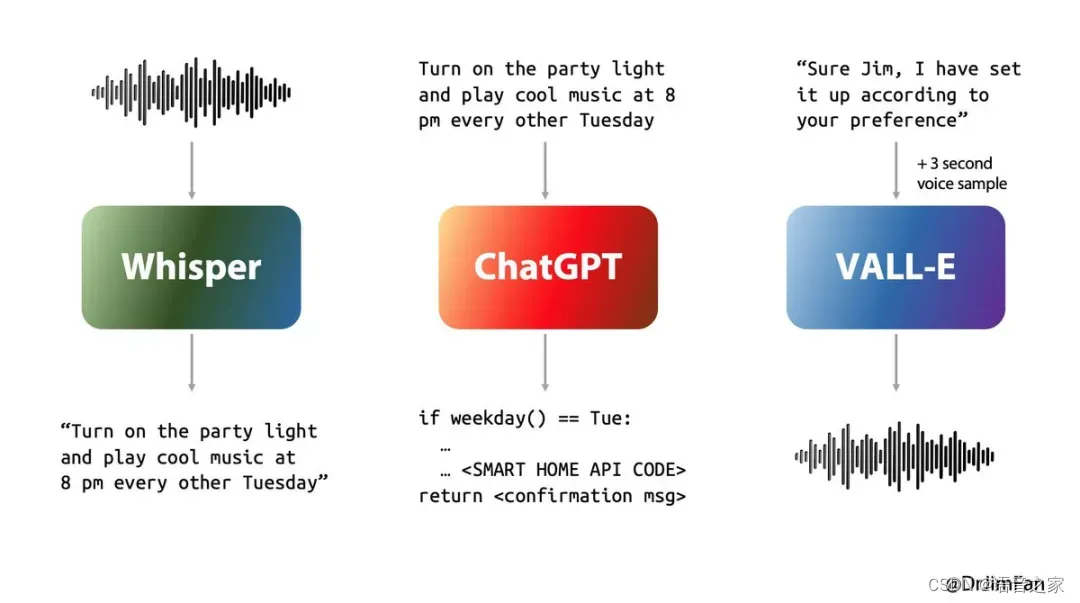
如何做到低延迟?核心还是来自于端到端。如下图,是上一代 ChatGPT 的交互,通过 Whisper 识别成文字(Speech -> Text),然后将文字喂给 ChatGTP 做理解并生成回复(Text -> Text),再喂给类似 OpenAI 的类似 VALL-E(行业猜) 这样的模型做合成(Text -> Speech),每一步都必须等到上一步完全执行完成才能开始下一步,累计的延迟非常大,博客中给了个数据,理解部分是 ChatGPT 的话平均延迟是 2.8s,GPT-4 的话 5.4s,加上识别部分等待时间会更长。所以我们看到初代 ChatGPT 那个圈不停的转,需要等很久。现在一步到位,直接 Speech -> Speech,用户感知到的延迟仅是合成的首字时间,平均 320 ms。这个速度,不仅远远超越了自己,也远远超越了所有的同行。
如何做到打断?现场演示的打断确实非常的快,非常的丝滑。传统的打断是依靠一个 VAD(Voice Active Detection) 的模块来做语音活动检测,一般需要较长的时间(0.5秒以上)确认用户有没有讲话,然后确定是不是要做打断。基本无法捕捉对于用户语音中的语气词、停顿、犹豫、重复、背景噪声等的信息,因此很容易出现插话、半天不说话等现象,用户体验非常糟糕。现在我们盲猜,GPT-4o 是在建模中显示的引入了用户语音结束 <EOU>(End of Utterance)、打断 <BARGE_IN> 两个建模单元,当模型输出 <EOU> 时,立即进入合成状态,当模型输出 <BARGE_IN> 时立即停止合成。
如何控制输入输出形态?在发布会上,OpenAI 宣布 GPT-4o 不仅可以在 ChatGPT 中使用,也可以在 API 中使用。在 ChatGPT 的 APP 和整个演示中,都是 Speech in, Speech Out,那在 API 中我们如何控制输出的模态呢?一种潜在的可能是目前输出模态是通过 prompt 控制的,在 ChatGPT APP 中我们指定输出为 Speech,在其他场景中我们则或指定,或让模型自动推导输出的模态。如想识别一段语音的文本,我们上传语音,并且通过文字的 prompt 告诉 API 我们想要文本形态的输出即可。
关于未来
语音交互的设计会去跟进和对标 GPT-4o,这点毋庸置疑。GPT-4o 确实做到了 10 倍的变化,此时整个端到端的体验,一些 corner case 的处理,当你的音箱、座舱等的语音助手不再答非所问,不在胡言乱语,有能力,有感情有温度,整个使用的活跃度相比现在肯定会有数量级的提升。相信在今天,肯定有不少产品已经开始了新一轮的立项和设计,语音交互也会开启新的历史进程。
大模型的军备竞赛越来越难,越来越残酷,轮为巨头的游戏。当初自研文本大模型的很多公司在 LLaMA 1/2/3 的一轮又一轮开源模型的攻势下,很快发现自己不但跟不起了,而且想跟也跟不上了。现在有文本、视觉、语音3种模态的输入,有文本、视觉、语音 3 种模态的输出,未来潜在就有 9 种可能的输入输出的组合,也就是数据、资源、人力上 9 倍 的投入,如何进行跟进。压力可能传递到 LLaMA 3 这里,LLaMA 3 还有个 400 B 的多模态的大模型还未发布,还未开源,不知是否会针对 GPT-4o 做一些调整。
最后,最近听了太多关于大模型在语音交互中价值的质疑,甚至很多是从业者的自我的怀疑,现在 GPT-4o 可谓一阵强心剂,确实是对语音行业的利好。然而,“莫听穿林打叶声,何妨吟啸且徐行”的豁然和坚持会更美!
参考链接
-
GPT-4o 博客链接 https://openai.com/index/hello-gpt-4o/
-
关于人类对话延时的研究 https://www.pnas.org/doi/10.1073/pnas.0903616106
-
ChatGPT 合成 https://openai.com/index/chatgpt-can-now-see-hear-and-speak/
-
Whisper 识别 https://openai.com/index/whisper/















 1636
1636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









