









分库分表的基础概念
什么是分库分表?
分库是把一个大的数据库分成若干个小的数据库,分表是把原先的大表分成若干个小表。
为什么要分库分表?
分库分表是为了解决由于数据量过大,而导致数据库性能降低的问题。使用分库分表能够有效的提高数据库的性能。
分库分表的分类:
- 垂直分表
- 垂直分库
- 水平分表
- 水平分库
垂直分表:
概念:
将一个表的按照字段分为多张表(访问较高的字段为一张表,访问较低的字段为一张表,拆分后表的关系是一对一)。
优点:
冷热数据分离,提高数据库表的操作效率;
避免IO过度争抢,并降低了锁表的机率,冷热数据查询互不影响。
原则:
冷热数据分离;
经常组合查询的数据放在一张表中(避免多表查询,单表查询效率最高);
垂直分库:
概念:
按照业务需求的不同,把不同的业务需求表分布在不同的数据库上(专库专用);
优点:
按照相同的业务需求进行垂直分库,使得数据的维护更加清晰简单;
不同的表分布在不同的数据库中,分摊了访问压力,提高了数据库访问性能;
原则:
按照业务需求来进行分库分表(避免跨库联查);
【注】:
公共表可以出现在各个数据库。
水平分表:
概念:
在同一个数据库中,把同一个表按照同一规则分成若干个表(如按照添加时间分)
优点:
优化了单一数据库数量过大的问题;
更加方便维护数据信息,降低IO争抢发生锁表的机率;
原则:
按照同一规则进行分表出来;
水平分库:
概念:
把同一张表按照同一规则分布在不同的数据上;
优点:
解决了单库数据量较大的问题;
原则:
需按照同一规则进行水平分表;
分库分表的具体实现
通过Sharding-jdbc实现分库分表(具体介绍请去官网):
inline模式下实现水平分表:
假设:一个专业招收的学生过多,需要按照id分为两个班级。
第一步新建数据库:
-- 新建数据库
CREATE DATABASE school;
-- 进入数据库
USE school;
-- 新建两张学生表
-- 判断student_01是否存在,若存在则删除
DROP TABLE IF EXISTS student_01;
CREATE TABLE student_01(
id INT PRIMARY KEY auto_increment,
name varchar(20) not null,
sex varchar(2) not null,
major varchar(50) not null -- 专业
);
DROP TABLE IF EXISTS student_02;
CREATE TABLE student_02(
id INT PRIMARY KEY auto_increment,
name varchar(20) not null,
sex varchar(2) not null,
major varchar(50) not null -- 专业
);第二步:在idea中的maven工程的pom.xml文件中导入sharding-jdbc的jar包
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>第三步:在yml文件中配置sharding-jdbc
# 分表配置
# 数据源名称,多数据源以逗号分隔
spring:
shardingsphere:
datasource:
props:
sql:
show: true #开启SQL显示,默认false
names: ds #{可以自定义}
ds: #数据源
type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池类名称
driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名
url: jdbc:mysql://192.168.0.105:3306/school?useSSL=false # 数据库 url 连接
username: root # 数据库用户名
password: root # 数据库密码
#sharding-jdbc配置水平分表
sharding:
tables:
student: #表名
actual-data-nodes: ds.student_0$->{1..2} # $:占位符 {1..2}:表示1或者2
# 行表达式分片策略
table-strategy:
inline:
sharding-column: id # 根据表的哪一列分
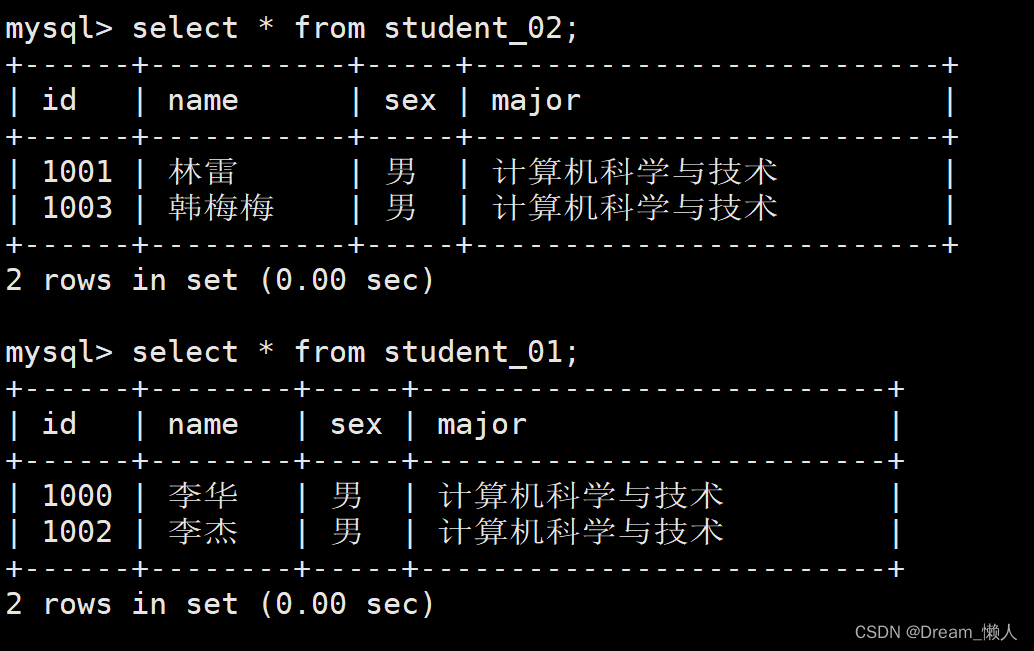
algorithm-expression: student_0$->{id % 2 +1} # 分片算法行表达式测试:
@Test
public void text() {
Student student = new Student(1000,"李华","男","计算机科学与技术");
Student student1 = new Student(1001,"林雷","男","计算机科学与技术");
Student student2 = new Student(1002,"李杰","男","计算机科学与技术");
Student student3 = new Student(1003,"韩梅梅","男","计算机科学与技术");
studentMapper.insert(student);
studentMapper.insert(student1);
studentMapper.insert(student2);
studentMapper.insert(student3);
}结果:
inline模式下实现水平分库:
第一步:新建两个数据库school_01和school_02;
第二步:配置yml文件
# 分库配置
# 数据源名称,多数据源以逗号分隔
spring:
main:
allow-bean-definition-overriding: true # bean重定义时覆盖前面定义的
shardingsphere:
datasource:
props:
sql:
show: true #开启SQL显示,默认false
names: ds1,ds2 #{可以自定义}
ds1: #数据源
type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池类名称
driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名
url: jdbc:mysql://192.168.0.105:3306/school_01?useSSL=false # 数据库 url 连接
username: root # 数据库用户名
password: root # 数据库密码
ds2: #数据源
type: com.alibaba.druid.pool.DruidDataSource # 数据库连接池类名称
driver-class-name: com.mysql.cj.jdbc.Driver # 数据库驱动类名
url: jdbc:mysql://192.168.0.105:3306/school_02?useSSL=false # 数据库 url 连接
username: root # 数据库用户名
password: root # 数据库密码
#sharding-jdbc配置水平分库
sharding:
tables:
student: #表名
actual-data-nodes: ds$->{1..2}.student # $:占位符 {1..2}:表示1或者2
# 行表达式分库策略
database-strategy:
inline:
sharding-column: id # 根据表的哪一列分
algorithm-expression: ds$->{id % 2 +1} # 分库算法行表达式测试:
@Test
public void text() {
Student student = new Student(1000,"李华","男","计算机科学与技术");
Student student1 = new Student(1001,"林雷","男","计算机科学与技术");
Student student2 = new Student(1002,"李杰","男","计算机科学与技术");
Student student3 = new Student(1003,"韩梅梅","男","计算机科学与技术");
studentMapper.insert(student);
studentMapper.insert(student1);
studentMapper.insert(student2);
studentMapper.insert(student3);
} 结果: 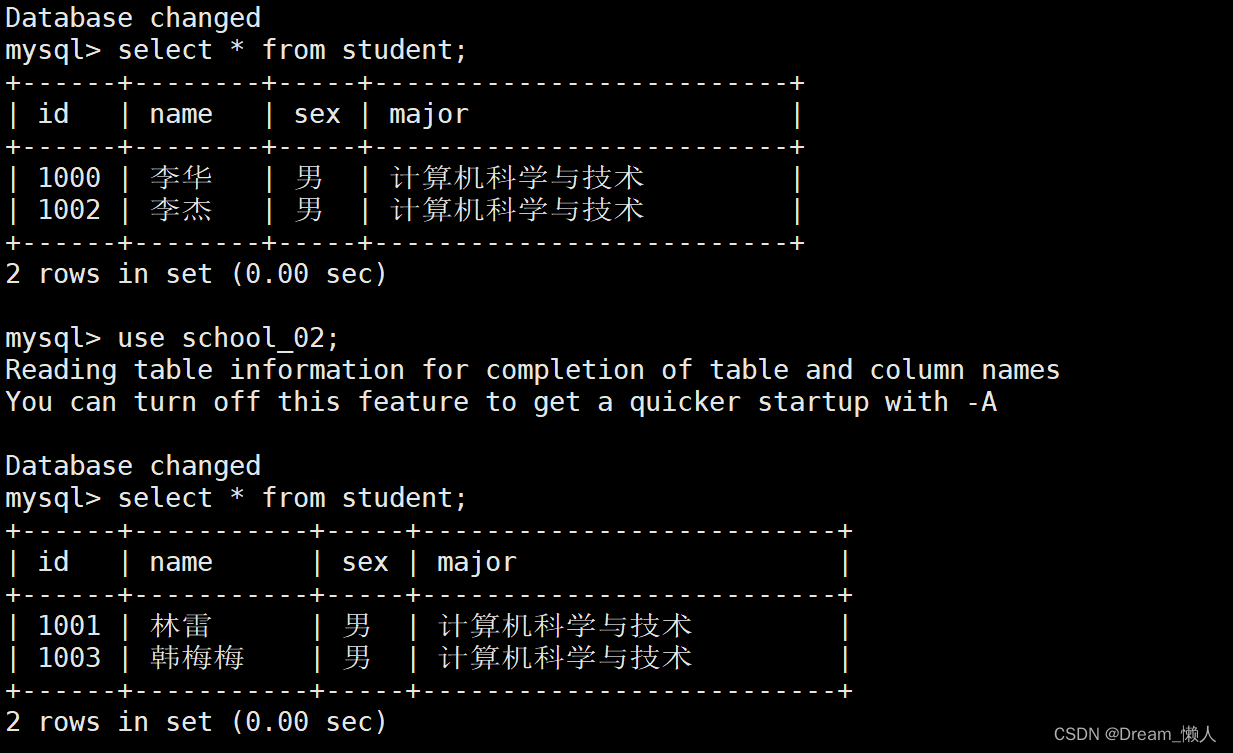
【注】:自己动手实现分库分表的结合。















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









