







这篇笔记是我2021年3月份还在读研时写的,今天上传到CSDN,留作个人备份。
笔记内容(按项目pull下来之后的调试顺序记录):
- python3: Permission denied

将python3 改为python
原因:在系统环境中,使用的是Anaconda环境配置工具里面的python版本,其命名应该是python.exe,所以输入python才可执行。
- UnicodeDecodeError: 'gbk' codec can't decode byte 0xab in position 2411: illegal multibyte sequence错误解决方案
解决方案:编码问题,打开文件时设置参数:UTF-8编码
with open(f_cipai,encoding='utf-8') as f:
with open(f_ci,encoding='utf-8') as f:
- RuntimeError: No CUDA GPUs are available
首先使用torch.cuda.is_available()验证python是否可正常识别已部署的CUDA GPU
发现可以正常返回true。
再经过排查,源码中设置了多GPU并行训练,而在train.sh中需要设置参数来确认使用GPU阵列中的第几个GPU进行训练。
把train.sh文件首行的参数设置改为0
CUDA_VISIBLE_DEVICES=1 \
CUDA_VISIBLE_DEVICES=0 \
tips:若还是不行,重新按照系统环境及cuda版本,到pytorch官网搜索相关命令,安装Pytorch:
C:\Users\57839>conda install pytorch torchvision torchaudio cudatoolkit=11.0 -c pytorch
- RuntimeError: CUDA out of memory. Tried to allocate 36.00 MiB (GPU 0; 8.00 GiB total capacity; 5.95 GiB already allocated; 3.77 MiB free; 6.22 GiB reserved in total by PyTorch)
调小batchsize 32-》16 仍然报错
RuntimeError: CUDA out of memory. Tried to allocate 62.00 MiB (GPU 0; 8.00 GiB total capacity; 5.65 GiB already allocated; 15.77 MiB free; 6.21 GiB reserved in total by PyTorch)
考虑GPU显存没有释放,关闭终端后重启终端,仍然报错GPU显存不足,而利用
nvidia-smi
命令查询在GPU0上正在使用GPU显存的进程:
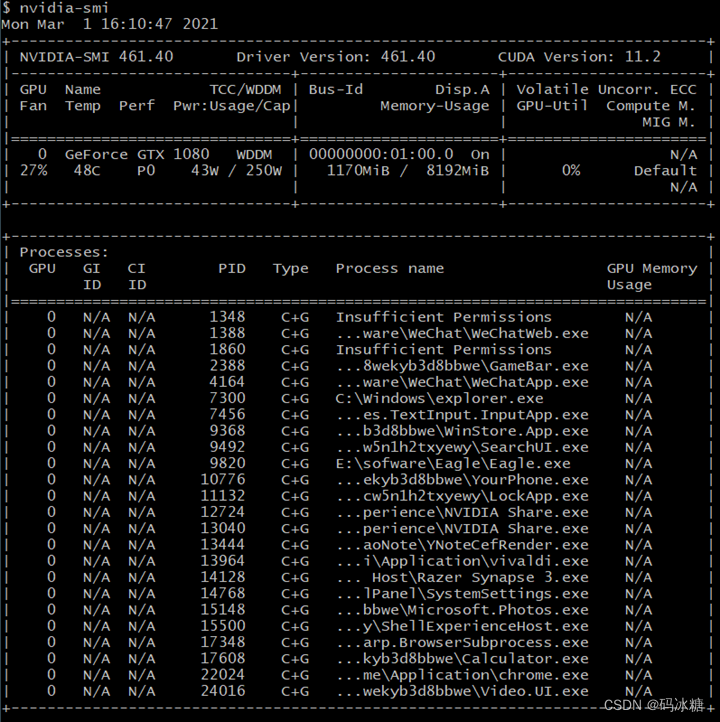
显示CPU显存占用仅为1170MB
于是可以确定并不是GPU显存未释放,于是为了确定是否是batch size的问题,直接将batch size调到极小值batch size = 1进行试验,发现可以运行,于是确定是batch size大小问题,逐步减小batchsize,最终确定batchsize = 4。
调小为batch size =
进步训练,显存占用接近90%。
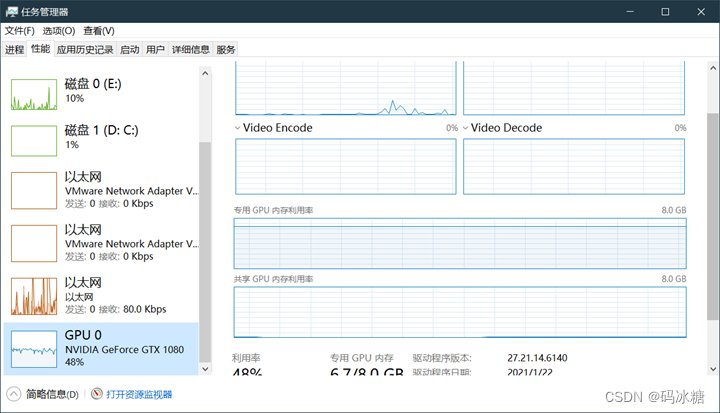
训练过程中发生中断,报错如下
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa5 in position 8: illegal multibyte sequence
根据提示可发现还是字符编码的问题,根据bash的traceBack回溯到出错的代码行,改变读取数据时的代码参数为utf-8
继续运行训练,发现跑一半显存又溢出了
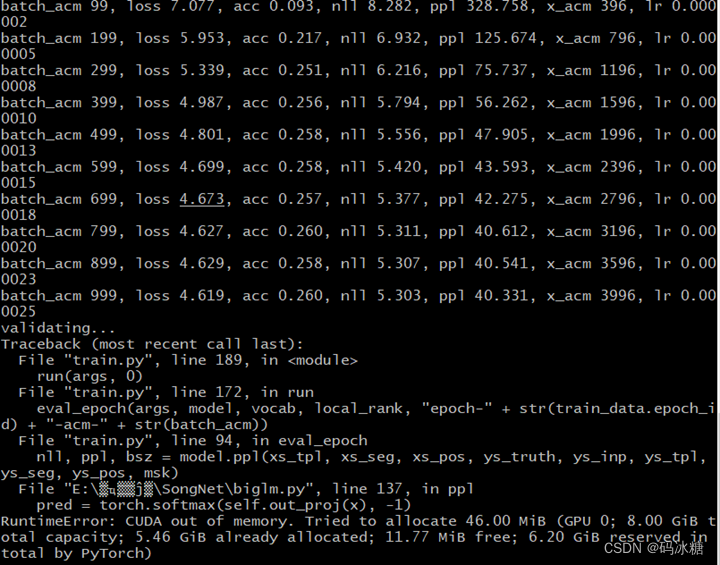
于是,只能考虑减少网络的参数数量:
在train.sh文件中对如下超参数进行设置:
--embed_dim 768 改为 600 //注意这个参数必须是 num_heads 超参数的整数倍,否则会报错
AssertionError: embed_dim must be divisible by num_heads
--ff_embed_dim 3096 改为 1024
--layer 12 改为 10
至此,网络可正常训练。
训练结束后:
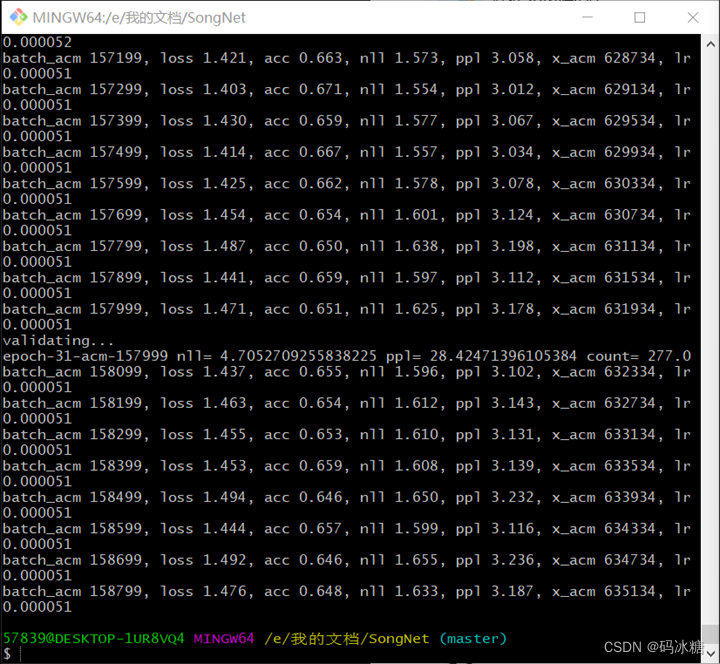
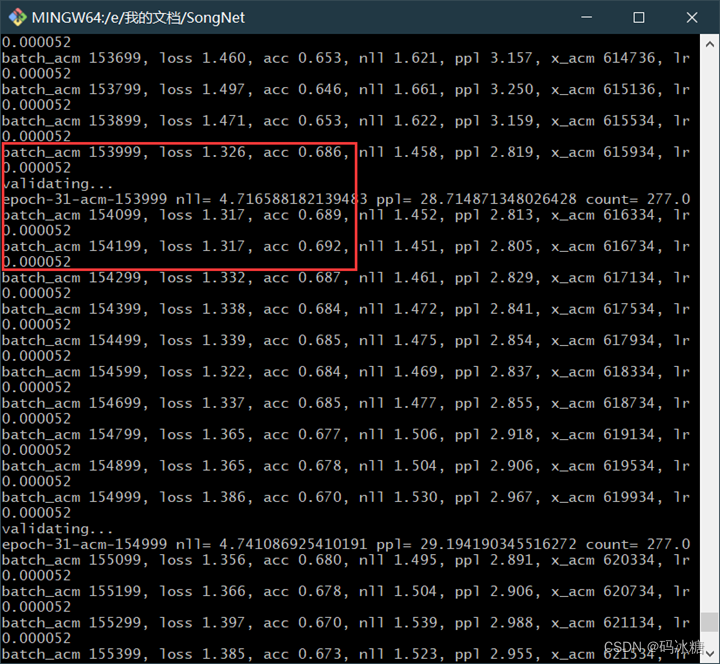
由于训练过程中每迭代1000次保存一次模型,模型共88GB。
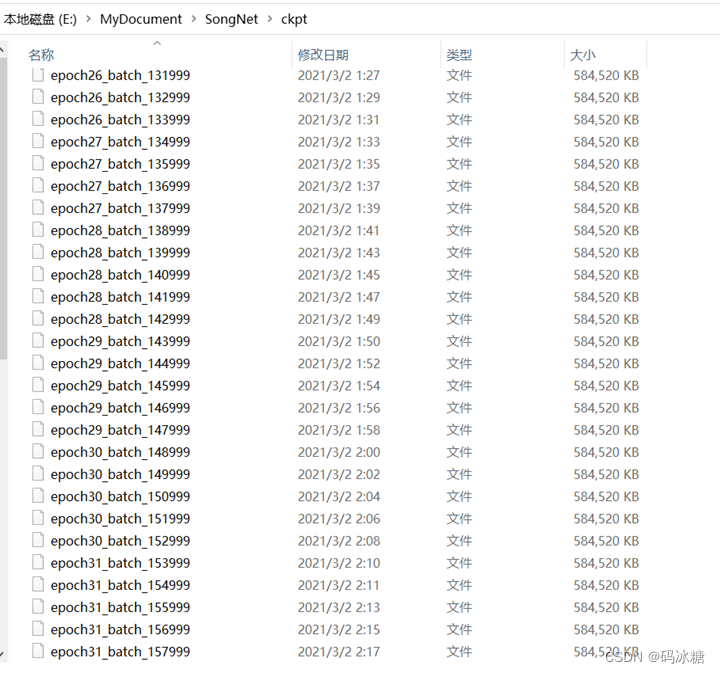
取损失最小的模型,后缀号为153999。
——————————模型测试:

1 .依旧是GPU设备参数不对导致无法正确识别:
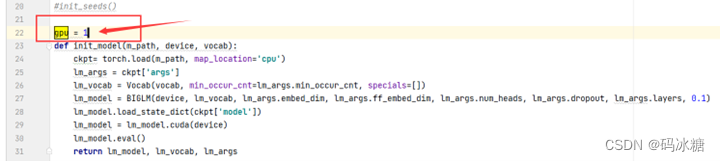
gpu改为 = 0
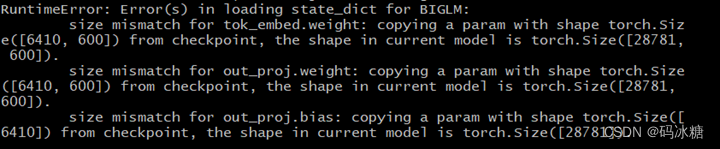
看情况应该是修改了模型维度导致的参数量不匹配,但是不知道测试过程中哪个代码段出了问题。看了下traceback提示,看不出所以然。
——————————————————————————————
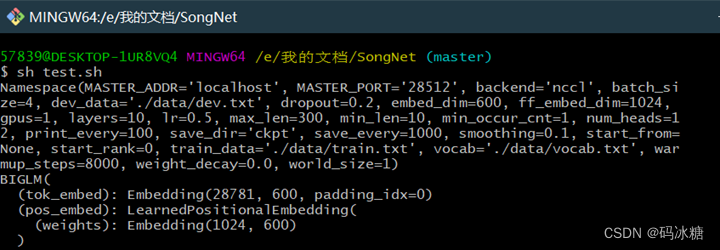
- 经过几天调试,根据报错定位model的文件中的代码及相关参数,把网络初始化时的参数打印出来细致观察,发现:
而在biglm.py中对BIGLM类的定义如下:
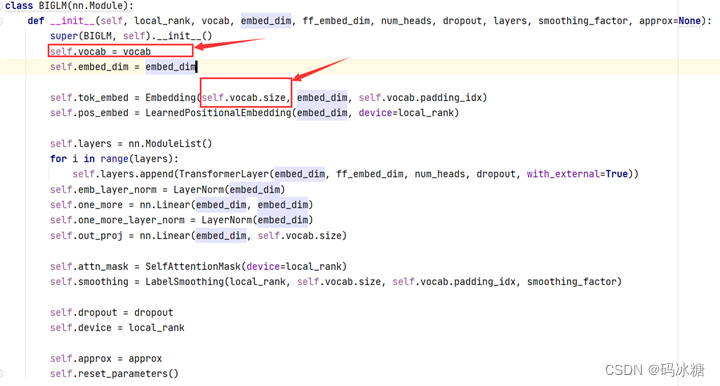
使用了字符集vocab.txt的vocab.size来初始化参数tok_embed,而回过头去观察使用的字符集:
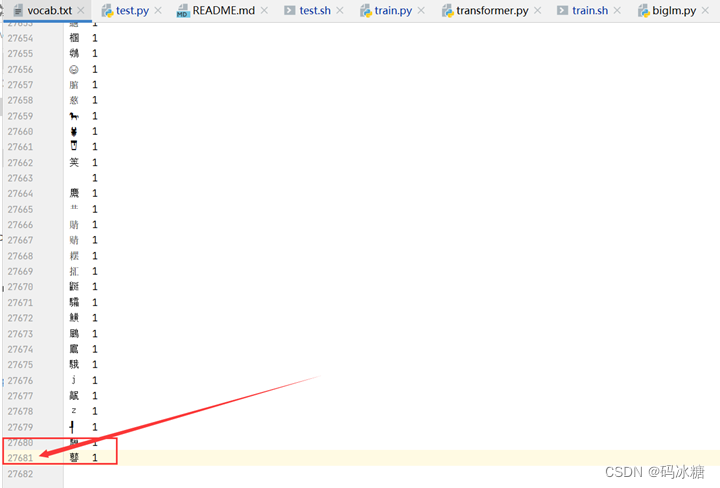
这个字符集的行数的尾数好像和报错信息中的28781有点像,
于是先备份了一份原始字符集,然后再试着删去几行,发现报错的数据28781果然也跟着变化了,于是确定vocab.size这个数据与字符集文本vocab.txt文件的行数有关。两者之间的差应该是1100。
根据报错,模型需要的参数量应该是6410,所以应该把字符集删减为6410-1100 = 5310行。
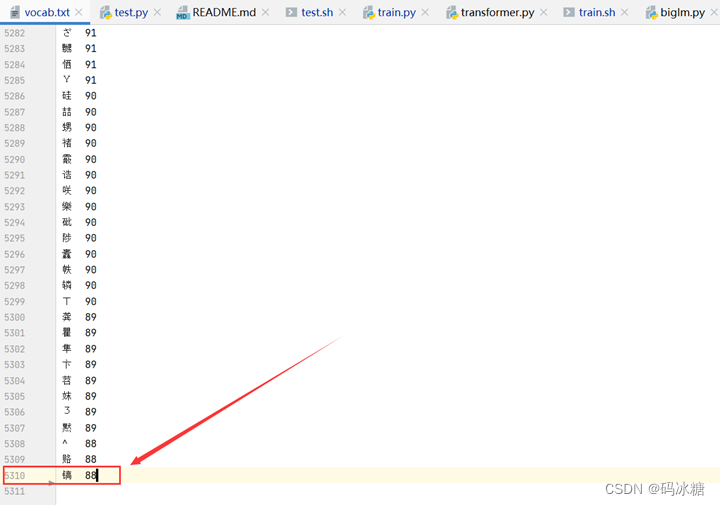
再使用命令 sh test.sh,参数规模不匹配的报错终于解决。又出现了常见的字符文件的解码错误

将对应文件的302行读取命令处加上encoding=‘utf-8’即可。

出现了新错误:

猜测输出的目录及文本文件需要手动创建:

手动创建后报错修复,可以开始测试生成歌词诗句了。
由于忘记改控制台的输出字符编码为UTF-8,所以控制台的打印乱码了,文本文档里UTF-8编码查看中文字符是没问题的。

测试后未润色的词句非常奇怪,模型的测试效果很差。。。

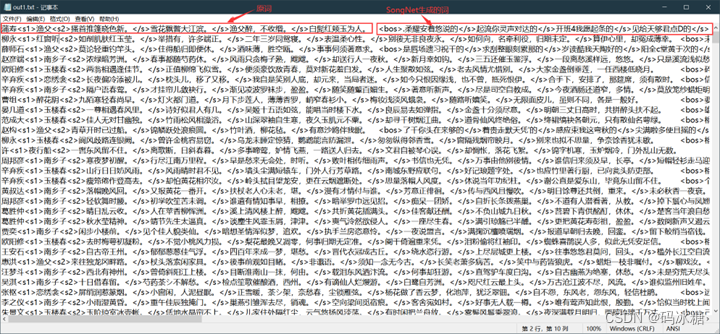
运行润色模块,出现报错

复制训练好的模型到相应目录,改为tmp.ckpt,出现字符编码错误,只能又改为utf-8

修改命令行窗口的字符编码后运行润色模块polish.py,润色效果如下,效果也很差。
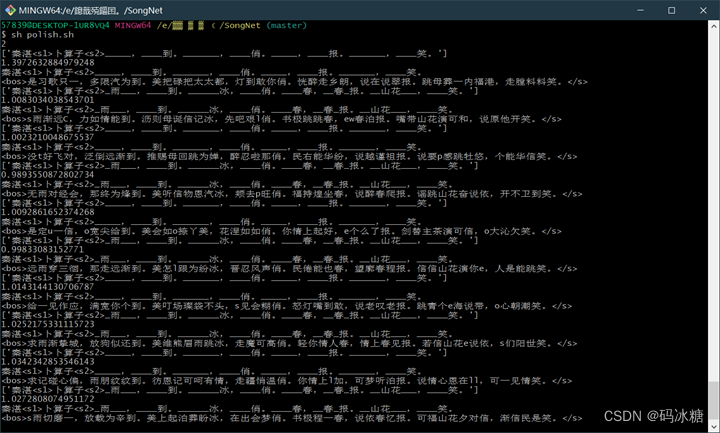
可能原因:1.在我的设备环境下,显存明显不足,为了让网络能够正常训练,修改了多项模型的参数,导致了模型训练效果不好。
2.字典文件有问题。
我查看了data文件夹下的字典文件vocab.txt发现与model文件下的字典vocab.txt有区别,且这个字典正好是5310行,并且里面只有标点符号和中文字符,所以我尝试将原代码中加载的字典文件从model文件夹换为data文件夹:

重新测试模型,发现效果好了很多。(突然好像意识到前面用错字典了,然而只能说,官方提供的demo里用的就是错的字典)
调试到这一步,终于模型生成诗词的句式通顺了,也不存在非中文的不正确字符。
















 2150
2150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









