






LZW的编码思想是不断从字符流中提取新的“词条”,然后用码字来表示这个“词条”,LZW编码是围绕“词典”转换表完成的。LZW编码器通过管理这个词典完成输入和输出之间的转换,输入是字符流,输出是n位表示的码字流。解码端输入码字流,边解码边建立词典,得到输出字符流。
编码原理
1:将词典初始化为包含所有可能的单字符,当前前缀P初始化为空 2:当前字符C=字符流中的下一个字符 3:判断P+C是否在词典中
如果“是”,则用C扩展P,即让P=P+C,返回Step 2
如果“否”,则输出与当前前缀P相对应的码字W,将P+C添加到词典中,令P=C,返回Step 2
LZW编码算法首先初始化词典,然后顺序从待压缩文件中读入字符并按照上述算法执行编码,最后将编得的码字流输出至文件中。
解码原理
1:在开始译码时词典包含所有可能的前缀根 2:令CW:=码字流中的第一个码字。
3:输出当前缀-字符串string.CW到码字流。 4:先前码字PW:=当前码字CW。
5:当前码字CW:=码字流的下一个码字。
6:判断当前缀-字符串string.CW 是否在词典中。
如果”是”,则把当前缀-字符串string.CW输出到字符流。当前前缀P:=先前缀-字符串string.PW,当前字符C:=当前前缀-字符串string.CW的第一个字符。把缀-符串P+C添加到词典。
如果”否”,则当前前缀P:=先前缀-字符串string.PW。 当前字符C:=当前缀-字符串string.CW的第一个字符。 输出缀-符串P+C到字符流,然后把它添加到词典中。
7:判断码字流中是否还有码字要译。
如果”是”,就返回步骤4。
如果”否”,结束。
代码:
词典树:

初始化词典树:
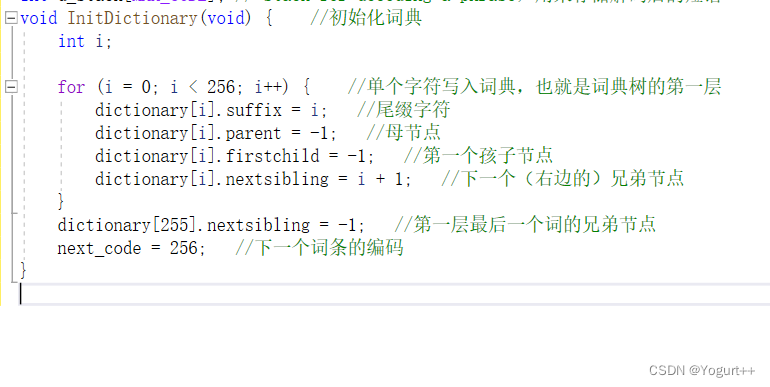
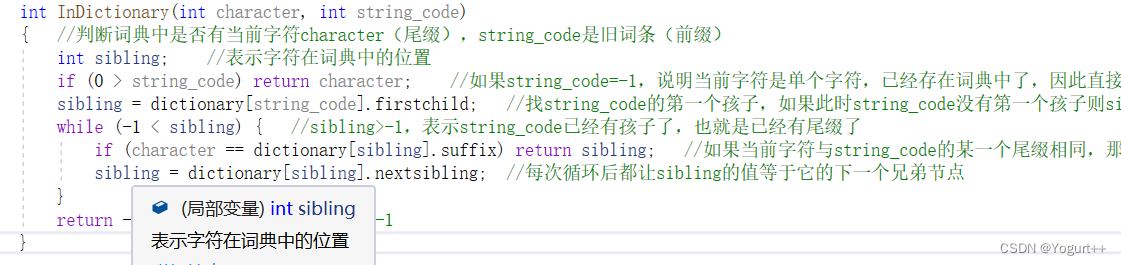
判断词典是否在该词典树中:
添加新字符:
编码:
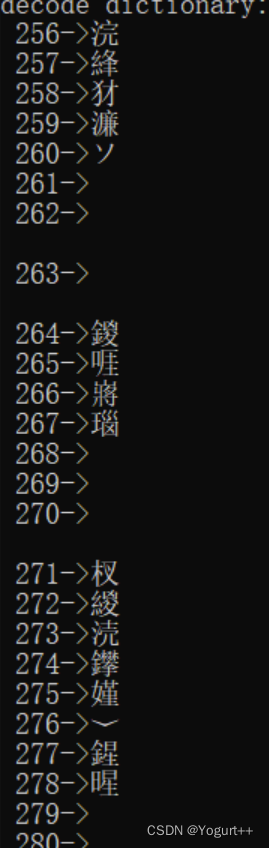
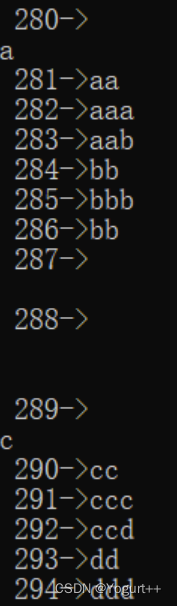
解码: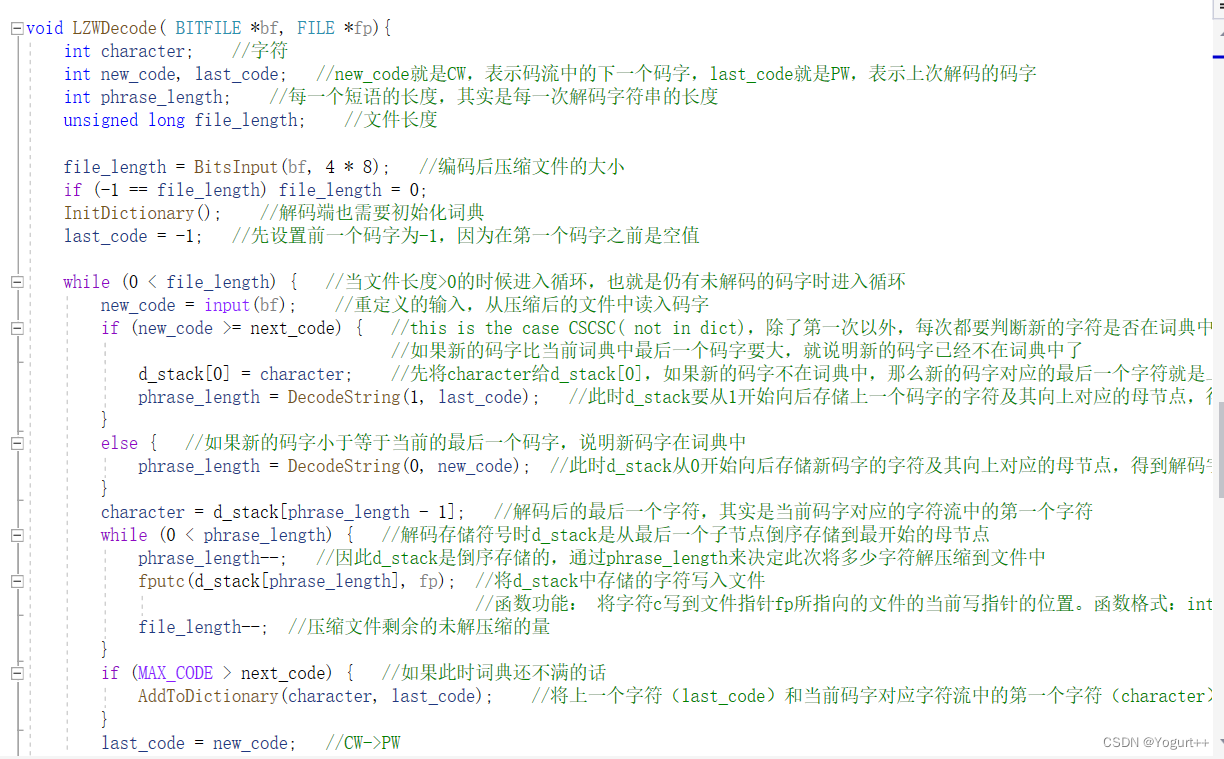 实验结果:
实验结果:
test.txt文件: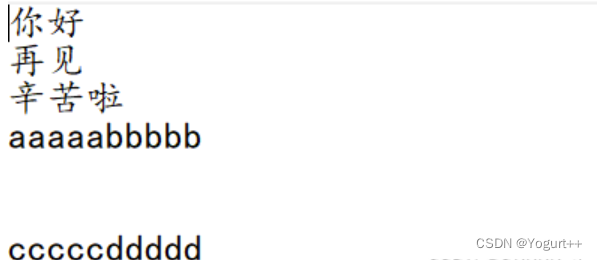















 2785
2785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









