







 本文探讨了MapReduce中ReduceTask并行度的决定因素,如任务数量、输入数据分区、处理能力,以及数据倾斜问题。作者提供了详细的实验步骤,以找出在特定环境和数据集下最佳的ReduceTask数量,以提升性能和资源利用效率。
本文探讨了MapReduce中ReduceTask并行度的决定因素,如任务数量、输入数据分区、处理能力,以及数据倾斜问题。作者提供了详细的实验步骤,以找出在特定环境和数据集下最佳的ReduceTask数量,以提升性能和资源利用效率。
MapReduce—ReudceTask并行度决定机制
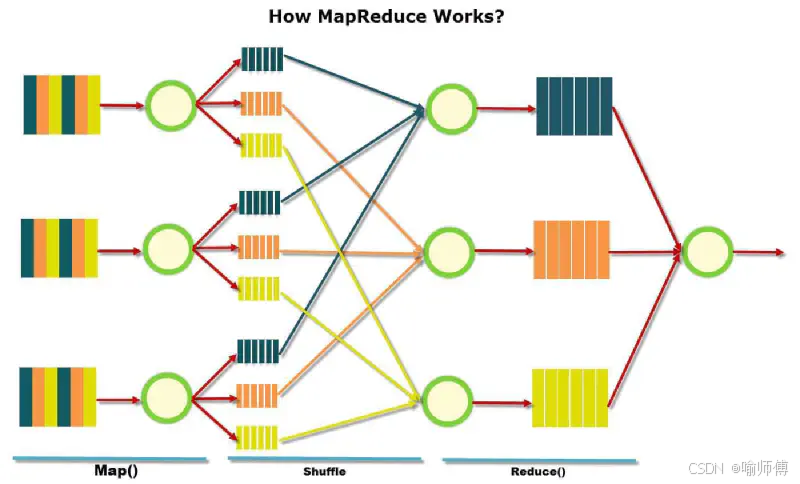
1. Reduce任务的数量(reduce task count):
- 这是最基本的决定因素之一。
- 在作业启动时,用户可以指定Reduce任务的数量。更多的Reduce任务意味着更多的并行度,因为每个Reduce任务可以在不同的数据分区上独立运行。
2. 输入数据的分区数(number of input partitions):
-
Reduce任务的输入来自于Map任务的输出,而Map任务的输出会根据用户指定的分区函数将数据划分为不同的分区。
-
如果输入数据被划分为更多的分区,那么每个Reduce任务将会处理更少的数据,从而提高了并行度。
3. Reduce任务的处理能力(reduce task processing capacity):
- Reduce任务的处理能力指的是Reduce任务所在节点的计算资源。
- 如果Reduce任务所在的节点具有更多的CPU核心、内存和网络带宽等资源,那么它可以同时处理更多的数据,从而增加并行度。
4. 数据倾斜(data skew):
- 在实际的数据处理中,可能会出现数据倾斜的情况,即某些数据分区的大小远远大于其他分区。
- 为了避免某些Reduce任务成为性能瓶颈,可以通过增加Reduce任务的数量来缓解数据倾斜问题,提高整体的并行度。
5.实验:寻找合适的并行度
-
初始设置:首先,需要选择一个适当的数据集和一个具体的MapReduce作业。确保有足够的数据量和充足的计算资源来运行实验。
-
选择不同数量的ReduceTask:在相同的数据集和环境下,尝试运行相同的作业,但使用不同数量的ReduceTask。可以从较低的数量开始,比如1个ReduceTask,然后逐步增加数量,观察每次增加ReduceTask数量对作业性能的影响。
-
性能评估:在每个设置下,记录作业的执行时间、资源利用率以及任何其他你认为重要的性能指标。也可以观察作业是否有任何失败或者出现错误的迹象。
-
分析结果:比较不同设置下的性能指标,包括作业执行时间和资源利用率。寻找一个性能最优的配置,即使增加ReduceTask数量不再显著提高性能,或者增加ReduceTask数量导致资源利用率下降。
-
验证结果:在确认了最佳ReduceTask数量后,可以进一步验证实验结果,确保它适用于不同的数据集和环境。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











