







Spark概述

1.什么是RDD
Spark RDD(Resilient Distributed Dataset)是 Spark 中最基本的数据抽象,它代表一个不可变、可分区、元素可以并行计算的数据集合。
RDD 是 Spark 中数据处理的核心概念,提供了一种高效的分布式数据处理模型。

2.RDD特性
1.不可变性(Immutable)
- RDD 是不可变的数据结构,一旦创建就不能被修改。
- 任何对 RDD 的转换操作都不会改变原始的 RDD,而是会生成一个新的 RDD。
- 这种不可变性使得 RDD 具有良好的容错性和并发性。
2.可分区性(Partitioned)
- RDD 中的数据集合可以分为多个逻辑分区,每个分区可以在集群中的不同节点上进行并行处理。
- 分区的数量决定了 RDD 的并行度,可以根据需要手动设置分区数或让 Spark 自动根据数据源进行分区。
RDD分区详解
在 Spark 中,RDD 的分区是指将数据集按照一定的规则分割成若干个部分,每个部分称为一个分区,这些分区可以分布在集群中的不同节点上进行并行处理。RDD 的分区方式对于 Spark 的性能和并行度具有重要影响。
1.分区的作用:
- 分区决定了数据在集群中的分布方式,直接影响了并行度和任务执行效率。
- 合理的分区可以使得数据能够均匀地分布在集群中的各个节点上,从而实现更好的并行处理效果。
2.默认分区规则:
- 当创建 RDD 时,如果没有指定分区数,Spark 会根据默认的分区规则来确定分区数。对于一些输入数据源(如 HDFS 文件、本地文件),Spark 会根据数据源的大小和块大小来自动计算分区数。


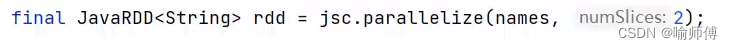
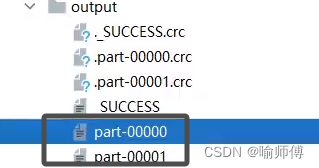


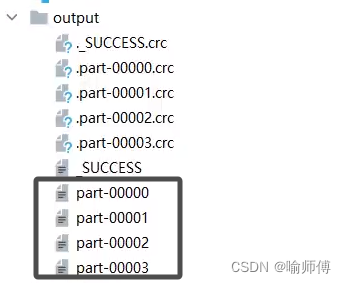

3.手动指定分区数:
- 在创建 RDD 时,可以通过参数指定所需的分区数,例如 parallelize() 方法可以接收一个参数来指定分区数,而 repartition() 和 coalesce() 等操作也可以用来调整 RDD 的分区数。

4.常见的分区方法:
- 哈希分区(Hash Partitioning):根据数据的哈希值将数据分配到不同的分区中。相同的键(如相同的键值对)会被哈希到同一个分区中,从而保证相同键的数据被处理在同一个节点上,适用于需要按键进行聚合操作的场景。
- 范围分区(Range Partitioning):根据数据的范围将数据分配到不同的分区中。例如,可以根据数字大小范围将数据划分到不同的分区,适用于有序数据的处理场景。
- 自定义分区:用户可以根据自己的需求实现自定义的分区方法,通过继承 Partitioner 类并重写 getPartition() 方法来实现自定义的分区逻辑。
5.分区数的选择:
- 分区数的选择需要考虑数据量、集群规模、任务并行度等因素。通常情况下,可以根据数据量和集群的核心数来选择一个合适的分区数,以实现数据均匀分布和充分利用集群资源。
6.分区的优化:
- 在数据倾斜等情况下,可能会导致某些分区数据量过大,从而影响任务的执行效率。针对这种情况,可以通过一些优化手段来解决,如在特定的键上使用自定义分区、使用 repartition() 或 coalesce() 方法重新分区等。
通过合理地选择和设计分区方式,可以提高 Spark 作业的性能和效率,从而更好地应对大规模数据处理任务。
3.容错性(Fault Tolerant)
- RDD 具有容错性,可以通过记录每个分区的转换操作来实现容错。
- 当某个分区的数据丢失时,Spark 可以通过重新计算该分区来恢复数据,从而保证计算的正确性。
4.惰性计算(Lazy Evaluation)
- RDD 支持惰性计算,即转换操作不会立即执行,而是在遇到行动(Action)操作时才会触发计算。
- 这种惰性计算可以优化计算过程,避免不必要的计算开销。
5.可持久化(Persistence)
- RDD 支持持久化操作,可以将 RDD 缓存在内存或磁盘上,以便重用。
- 通过持久化可以避免重复计算,提高计算性能。
6.支持多种数据源
- RDD 支持从多种数据源创建,包括 HDFS、本地文件系统、HBase、Cassandra、Amazon S3 等,也可以通过并行化集合或从其他 RDD 转换而来。
7.数据操作
- RDD 提供了一组丰富的转换操作和行动操作,可以对数据集合进行各种复杂的处理和分析。
- 通过 RDD,用户可以灵活地编写分布式数据处理程序,实现各种大规模数据处理任务。
3.RDD的理解
RDD(弹性分布式数据集)在 Spark 中可以被看作是一个分布式的数据集合,它们可以在不同的节点上进行并行操作,类似于一个数据流水线,可以流转数据并对其进行转换、过滤、聚合等操作。
RDD 并不直接保存数据,而是通过一系列的转换操作来构建出一个数据处理的流程。
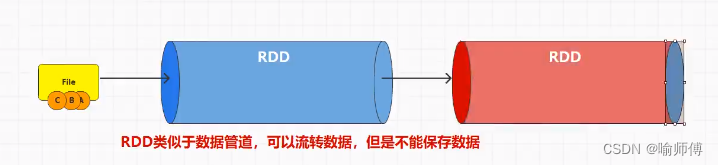
RDD 是惰性计算的,只有当遇到行动操作时才会触发实际的计算。
另外,虽然 RDD 本身不会保存数据,但是它们可以通过持久化(Persistence)操作将中间结果保存在内存或磁盘上,以便后续的复用,这样可以提高计算效率。
Spark 提供了多种不同级别的持久化选项,如 MEMORYONLY、MEMORYANDDISK、DISKONLY 等,开发人员可以根据需求选择适合的持久化级别。

















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











