







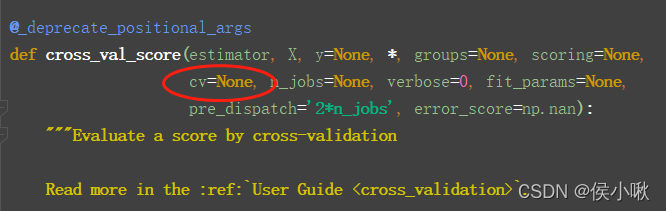
小啾在测试中发现,cross_val_score()的cv参数,
该参数在源码中默认值为None,但是在实际使用时,默认值为5,默认效果为K-Fold交叉验证(K即cv)。
即默认将数据分成大小相同的K份,即5个子集,
从中随机选择4个作为训练集,另1个是测试集。该过程重复进行,所以共有5个组合。
即验证后得到一个装有5个元素的一维数组。
以检验准确率为例:
对比以下代码及其输出结果:
- 不设cv
scores = cross_val_score(estimator, X, y, scoring='accuracy')
print(scores, '\n', len(scores))
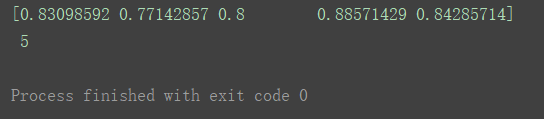
- cv=5
scores = cross_val_score(estimator, X, y, scoring='accuracy', cv=5)
print(scores, '\n', len(scores))

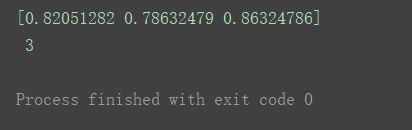
- cv=3
scores = cross_val_score(estimator, X, y, scoring='accuracy', cv=3)
print(scores, '\n', len(scores))
虽然照此法代码能使用,但是小啾不明白其原因,对此各位大佬怎么看?















 2634
2634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











