






1. 消息队列的基本介绍
1.1 消息队列产生的背景
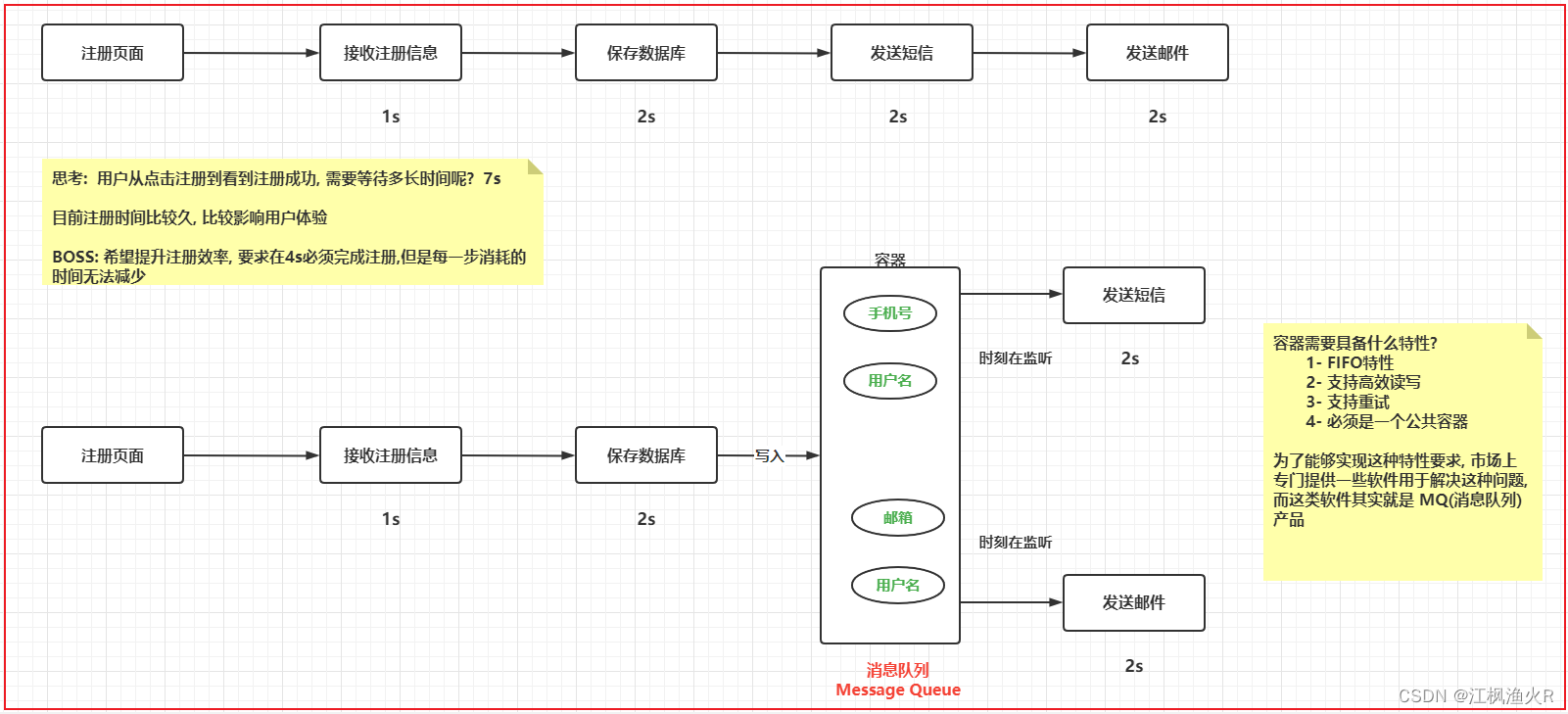
何为消息队列呢?
消息: 本质上就是数据 , 而且这个数据存在一种流动状态, 从某一端传递到另一端
队列: 本质上就是容器, 可以存储数据, 只不过这个容器具备 FIFO(先进先出) 特性
消息队列: 指的就是 将消息数据放置到队列, 通过队列实现数据传输的特性, 从队列的一端写入, 从另一端输出, 保持FIFO特性
1.2 常见的消息队列的产品
常见的消息队列产品有那些呢? 这类型产品也被称为中间件产品
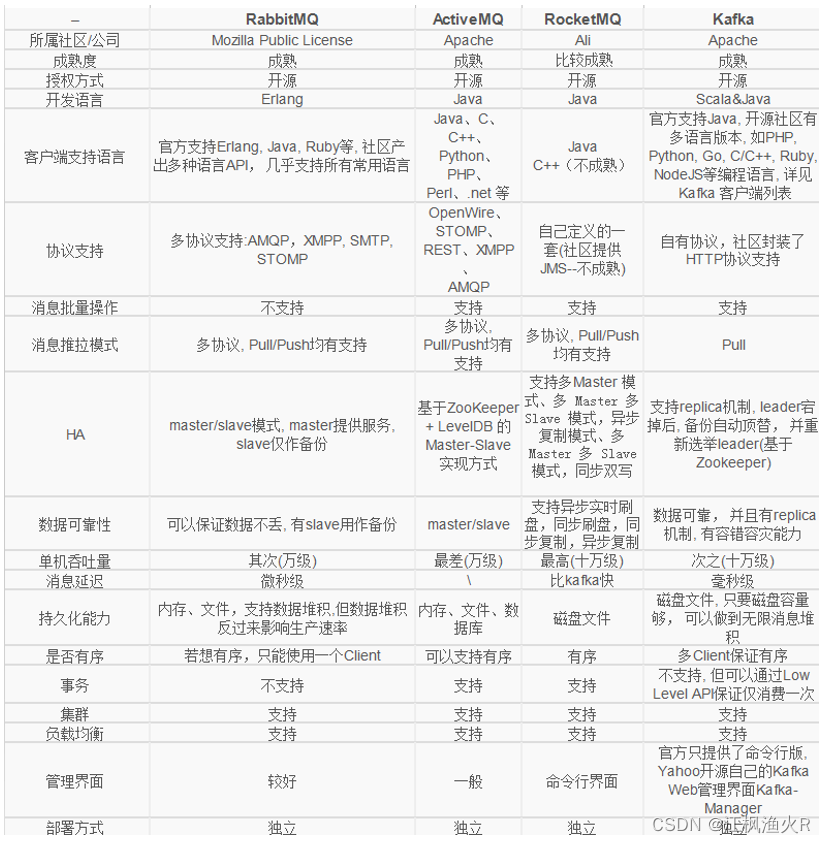
1- ActiveMQ: 出现时期比较早的一款消息队列中间件产品, 在早期使用人群是比较多, 目前整个社区活跃度严重下降, 适用人群基本很少
2- rabbitMQ: 此款目前使用人群比较多的一款消息队列产品, 社区活跃度较高, 主要是应用在业务领域
3- RocketMQ: 是由阿里推出一款消息队列的中间件, 目前主要是在阿里系环境中使用, 目前支持的客户端比较少, 主要在java中应用较多
4- pulsar: 目前是有streamnative公司维护一款产品, 目前已经是apache旗下顶级消息队列产品, 近一两年新起一款中间件产品
5- kafka: 也是apache 旗下顶级开源项目, 项目来源于领英, 是大数据体系中最为常用的消息队列的中间件产品(统一大数据消息组件)
1.3 消息队列的作用是什么
消息队列的作用:
- 1- 应用解耦合
- 2- 异步处理
- 3- 限流削峰: 应用高并发的场景, 通过消息队列对接高并发的请求, 提高系统稳定性, 降低硬件成本 (秒杀)
- 4- 消息驱动的系统
1.4 消息队列的两种消费模型
在Java中, 为了能够集成消息队列产品, 专门提供了一个消息队列的协议: JMS (java message server)
消息队列中两个角色: 生产者(producer) 消费者(consumer)
在JMS规范中, 专门规定了两种消息消费模型
1- 点对点消费模型: 指的一条消息最终只能被一个消费者所消费
2- 发布订阅消费模型: 指的一条消息最终被多个消费者所消费
2. kafka的基本介绍
kafka是一款消息队列的中间件的产品, 来源于领英公司, 后期将其贡献给了apache 目前是apache旗下的顶级来源项目, 采用语言是scala
官方网址: http://kafka.apache.org
kafka集群是依赖于zookeeper的, 意味着如果要启动kafka集群, 必须先启动zookeeper集群
kafka的特点:
- 1- 可靠性: 整个服务器不容易发生宕机的风险, 以及数据也不容易丢失
- 2- 可扩展性: kafka集群可以很方便的进行扩容, 不需要停机
- 3- 耐用性: 存储在kakfa数据, 可以持久化的保存到磁盘上
- 4- 性能: kafka具有高吞吐 高并发 整个效率是非常快, 可以保证 零停机 零数据丢失
3. kafka的架构
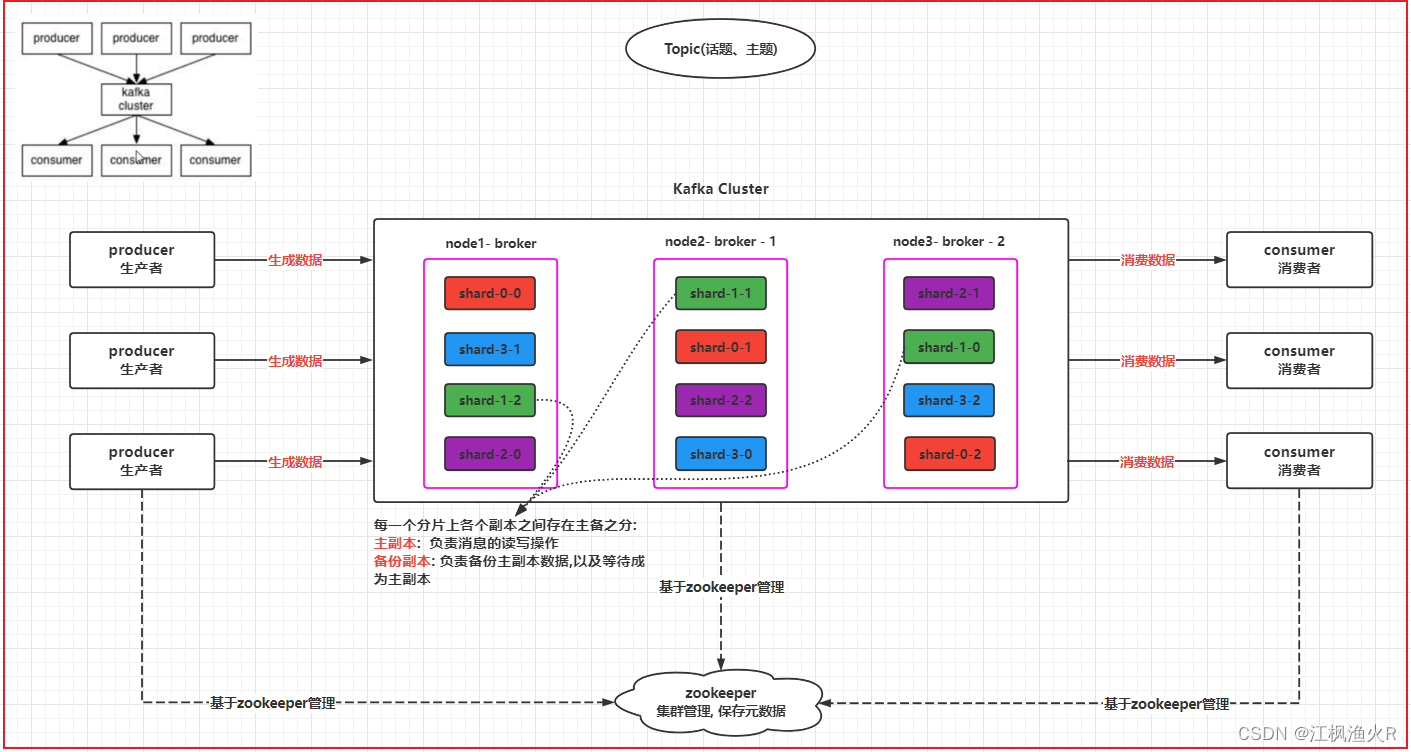
kafka cluster: kakfa的集群
broker: kafka集群中各个节点, 每个节点都是一个个broker, 每个broker都有唯一的标识ID
producer: 生产者
consumer: 消费者
topic: 话题, 主题, 这是一个逻辑的架构
shard: 分片, 一个topic可以被分为多个分片, 分片的数量与broker的数量是没有关系的
replicas: 副本, 每一个分片都可以构建多个副本, 副本数量最多和节点的数量是相等的(分片本身也是一个副本)
zookeeper: kafka集群的管理者, 负责元数据的管理
4. kafka的安装操作
易错点:
-
- 启动的时候, server.properties中 路径不要写错了
-
- 配置文件中监听地址的前面的注释不要忘记打开
-
- 分发之后, 不要忘记修改每个server.properties的 id 和 监听地址
-
- 没有启动zookeeper, 或者仅仅启动了其中一台
如何启动
1) 启动zookeeper: 需要保证zookeeper是启动良好的
2) 启动kafka集群: 三个节点都需要执行的
cd /export/server/kafka_2.12-2.4.1/bin
前台启动:
./kafka-server-start.sh ../config/server.properties
后台启动:
nohup ./kafka-server-start.sh ../config/server.properties 2>&1 &
注意: 在启动的时候, 建议先进行前台启动, 如果没有报出任何错误, 直接挂载在后台
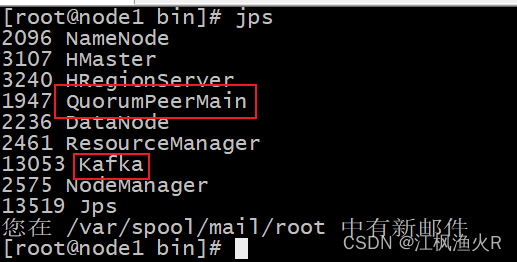
3) 如何查看 kafka是否已经启动:
方式一: 通过JPS 三个节点都得测试
方式二: 通过zookeeper来检查
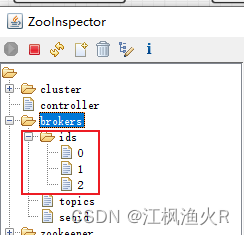
- kafka的一键化启动脚本:
第一步: node1节点 在Linux中创建一个目录:
mkdir -p /export/onekey
cd /export/onekey
第二步: 脚本编写
ka1_start:
#!/bin/bash
cat /onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & "
}&
wait
done
ka2_2stop:
#!/bin/bash
cat /onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9"
}&
wait
done
slave:
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
第三步: 赋权限
chmod 755 *
第四步: 即可测试
注意: 使用一键化脚本, 也得需要先启动zookeeper
5. kafka的相关使用
5.1 kafka的shell命令操作
kafka本质上就是一个消息队列的中间件的产品, 主要负责消息数据的传输, 也就是说, 学习kafka, 也就是学习kafka如何生产数据, 以及如何消费数据操作
- 1- 如何使用kafka的命令来创建Topic
./kafka-topics.sh --create --zookeeper node1:2181,node2:2181,node3:2181 --topic test01 --partitions 3 --replication-factor 2
参数说明:
--create: 表示创建操作
--zookeeper: 指定zookeeper的地址
--topic: 指定topic名称
--partitions: 指定分片数
--replication-factor: 指定每个分片的副本数量
- 2- 如何查看topic:
# 2.1 如何查看有那些topic:
./kafka-topics.sh --list --zookeeper node1:2181,node2:2181,node3:2181
# 2.2 查看某一个topic的详细信息:
./kafka-topics.sh --describe --zookeeper node1:2181,node2:2181,node3:2181 --topic test01
结果:
Topic: test01 PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: test01 Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: test01 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: test01 Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1
说明:
第一行: 总览信息 含有: topic名称 分片的个数 副本的个数 配置信息
后几行: 表示每一个分片的详细信息
topic名称 分片的编号 主副本的brokerID 所有副本放置broker位置ID 可以的副本的brokerID
这些信息来源于哪里呢? zookeeper
- 3- 如何修改topic:
# 增加分片数量: 可以 无法减少分片的数量 不支持副本的修改
./kafka-topics.sh --alter --zookeeper node1:2181,node2:2181,node3:2181 --topic test01 --partitions 5
- 4- 如何删除topic
./kafka-topics.sh --delete --zookeeper node1:2181,node2:2181,node3:2181 --topic test01
信息显示:
Topic test01 is marked for deletion. (topic test01 被标记删除, 这是一种逻辑删除, 实际并没有删除)
当标记后, 检查到topic中压根都没有数据, 会直接将目录删除了
如果有数据, 仅仅作为标记, 不会删除
- 5- 如何模拟一个生产者:
./kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic test01

- 6- 如何模拟一个消费者:
./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test01

接下来 在生产者中生产数据, 观察消费者是否可以消费者的到数据, 如果可以 说明可以正常生产消费了
5.2 kafka的基准测试
kafka的基准测试 主要是用于测试kafka集群的吞吐量, 每秒钟可以最大可以生产多少条消息, 以及每秒钟最大可以消费多少条消息
在测试过程中, 由于吞吐量受topic的分片和副本的数量影响非常大, 需要在测试的过程中, 需要基于不同的分片和副本的情况进行多次的测试, 以测出一个最准确的结果
测试生产效率:
- 1- 创建Topic:
./kafka-topics.sh --create --zookeeper node1:2181,node2:2181,node3:2181 --topic test02 --partitions 6 --replication-factor 1
- 2- 执行测试命令: 本次测试将会新增4GB
cd /export/server/kafka/bin
./kafka-producer-perf-test.sh --topic test02 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=node1:9092,node2:9092,node3:9092 acks=1
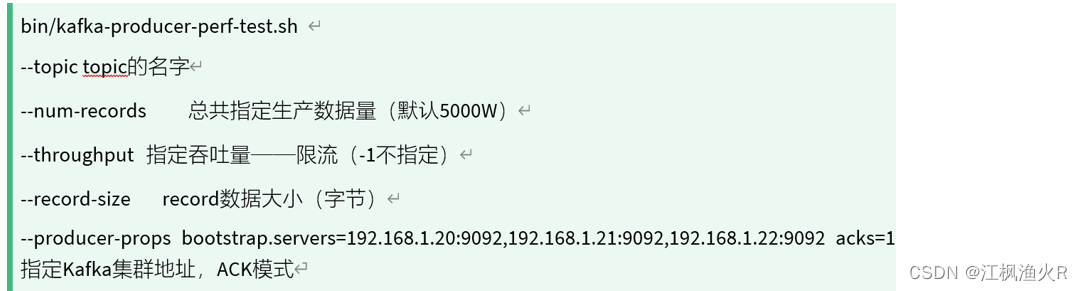
执行结果:

测试消费效率:
- 执行测试命令:
cd /export/server/kafka/bin
./kafka-consumer-perf-test.sh --broker-list node1:9092,node2:9092,node3:9092 --topic test02 --fetch-size 1048576 --messages 5000000

结果为:

总结:
假设broker的节点数量是无限的:
topic的分片数量越多, 性能越好, topic的副本越多, 会越影响性能
5.3 kafka的Python API的操作
准备工作:
- 1- 由于使用远端环境, 所以 需要在node1的节点上安装一个 python用于操作kafka的库, 如果是本地环境, 那么直接在本地安装这个库
python -m pip install kafka-python
- 2- 使用pycharm创建项目, 进行开发操作
5.3.1 使用python api 完成生产者代码
from kafka import KafkaProducer
if __name__ == '__main__':
# 1- 创建 kafkaProducer对象
producer = KafkaProducer(
bootstrap_servers=['node1:9092','node2:9092','node3:9092'],
acks=-1
)
# 2- 生产数据到kafka
# 同步方式 :
#producer.send('test01',b'hello kafka...').get()
# 异步方式:
producer.send('test01',b'hello kafka...')
#producer.flush()
# 3- 关闭生产者
producer.close()
5.3.2 使用 python api完成消费者代码
from kafka import KafkaConsumer
if __name__ == '__main__':
# 1- 创建 消费者的实例对象
consumer = KafkaConsumer(
'test01',
bootstrap_servers=['node1:9092','node2:9092','node3:9092'],
group_id='g_01',
enable_auto_commit=True,
auto_commit_interval_ms=1
)
# 2- 获取消息数据
for msg in consumer:
topic = msg.topic
partition = msg.partition
offset = msg.offset
key = msg.key
value = msg.value.decode('UTF-8')
print(f'topic为:{topic}, 分片为:{partition},偏移量为:{offset},消息key为:{key}, 消息value:{value}')
6. kafka核心原理
6.1 kafka的分片和副本机制
何为分片? 分片有什么用呢?
分片: 分片是对topic的一种划分操作, 通过分片 kafka可以实现对消息数据分布式的存储
作用:
1- 提供读写效率
2- 解决单台节点存储容量有限的问题
注意: 分片数量与集群的节点数量是没有关系的 分片数量可以构建多个
何为副本? 副本有什么用呢?
副本: 副本是针对的每一个topic下每一个分片, 可以将分片的数据通过副本方式存储多份
作用: 提高数据可靠性, 避免数据的丢失
注意: 副本的数量最多和节点的数量是相等的, 一般副本为1~3个 副本越多会导致数据大量的冗余存储, 同时影响写入的效率
6.2 kafka的消息存储和查询机制
6.2.1 存储机制

1- 在每个分片中, 数据都是以分文件的形式来存储的
2- 每个文件的片段都是由二个核心文件构成的, 一个是log文件 一个是index文件
log文件: 存储的真实消息数据
index文件: 是log文件的索引文件, 用于加快查询log消息
文件名: 表示当前这个文件片段是从那个消息偏移量开始存储数据 一个消息偏移量表示一条消息
3- 消息默认是达到168小时后 就会被kafka自动删除, kafka在删除的时候, 校验log文件的最后修改时间,因为kafka仅仅是临时存储
相关的配置:
log.retention.hours=168 (168小时 7天)
log.segment.bytes=1073741824 (1GB)
index文件中存储了什么?
在index文件中, 主要是存储每个消息的偏移量在log文件中对应的物理偏移量
例如共计有五条消息数据: hello kafka wo hen hao 1 2 3
hello kafkawo hen hao123
index文件: 消息偏移量 物理偏移量
0 11
1 21
2 22
3 23
4 24
6.2.2 查询机制

查询流程:
1- 确定消息在那个片段中: 第二个
2- 查询index文件, 这个偏移量数据在log文件的那个偏移量上
3- 查询log文件 按照顺序查找方案, 遍历对应位置, 将对应范围内数据获取到即可
磁盘查询策略: 顺序查找 和 随机查找 那个效率快呢? 一定是顺序查询















 5881
5881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









