







 Python的Pandas模块系统学习
Python的Pandas模块系统学习

1 pandas数据读取
Pandas需要先读取表格类型的数据,然后进行分析

1.1 读取文件和基础语句:
读取csv文件数据:
import pandas as pd
filepatch=r"C:\Users\radiomumm\Desktop\sucai\nba.csv"
#读取csv文件数据
ratings=pd.read_csv(filepatch)
#查看文件开头几行
print(ratings.head())
#查看文件行列属性,(行,列)
print(ratings.shape)
#查看列名,返回的是一个列表
print(ratings.columns)
#查看索引列
print(ratings.index)
#查看每列数据的数据类型
print(ratings.dtypes)
读取txt文件数据,txt文件需要以行列行使储存数据:
import pandas as pd
filepatch=r"C:\Users\radiomumm\Desktop\sucai\nba.txt"
#自定义读取文件,sep=设置分隔符,header=设置标题行有无,names=设置自定义列名。
ratings=pd.read_csv(filepatch,sep="\t",header=None,names=['NAME', 'state'])
print(ratings.head())
读取excel文件数据:
import pandas as pd
filepatch=r"C:\Users\radiomumm\Desktop\sucai\bhlh112.xlsx"
ratings=pd.read_excel(filepatch)
print(ratings.head())
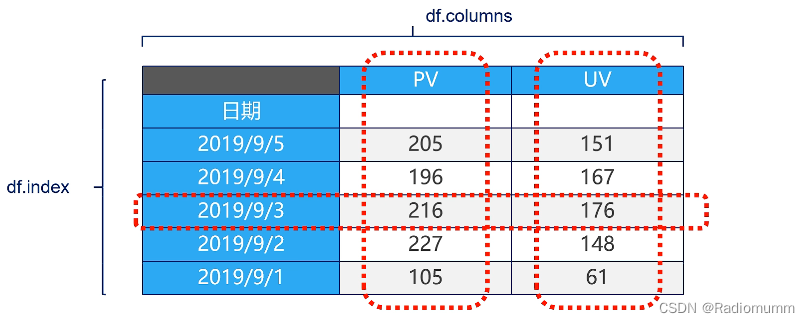
2 pandas数据结构(dataframe & series)
DataFrame:二维数据,整个表格,多行多列。
Series:一维数据,代表一行或一列。包含一组数据(不同数据类型)和一组与之相关的数据标签(索引)组成。
3 创建Series或Dataframe
3.1 series:
3.1.1 列表创建series:
import pandas as pd
sl=pd.Series([1,"A",23,5.4])
# [out]
# 0 1
# 1 A
# 2 23
# 3 5.4
# dtype: object
#获取索引
print(sl.index)#"RangeIndex(start=0, stop=4, step=1)"
# 获取值数列
print(sl.values)#[1 'A' 23 5.4]
#更换索引列,创建一个具有标签的Series.
sl=pd.Series([1,"A",23,5.4],index=["a","b","c","d"])
print(sl.index)#Index(['a', 'b', 'c', 'd'], dtype='object')
3.1.2 字典创建series:
#使用字典创建Series
dictdata={
"a":123,"b":3234,"c":1.2,"d":"end"}
sl2=pd.Series(dictdata)
print(sl2)
# [out]
# a 123
# b 3234
# c 1.2
# d end
# dtype: object
3.1.3 查询Series中的数据
print(sl2["a"])#查询一个值时,返回原生数据。
print(sl2[["a","b"]])#查询两个值时,返回一个Series。
3.2 Dataframe
3.2.1 创建Dataframe:
①.常见的方法为第一章中的Pandas读取excel/csv/mysql
②.使用多个字典文件创建Dataframe
import pandas as pd
dataf={
"name":["xiaohong","xiaozhang","xiangqiang"],
"age":[21,23,22],
"gender":["female","male","female"],
"school":["1s","3s","2s"]}
df=pd.DataFrame(dataf)
print(df)
# [out]
# name age gender school
# 0 xiaohong 21 female 1s
# 1 xiaozhang 23 male 3s
# 2 xiangqiang 22 female 2s
print(df.index)#RangeIndex(start=0, stop=3, step=1)
print(df.columns)#Index(['name', 'age', 'gender', 'school'], dtype='object')
3.2.2 查询Dataframe中的数据:
如果只查询一列、一行,返回的是Series。
如果查询的说多列、多行,返回的是一个Dataframe。
print(df["age"])#返回的是Series
print(df[["age"]])#返回的是Dataframe
print(df[["age","school"]])
4 pandas数据查询
4.1 loc和iloc的用法
4.1.1 loc
loc 基于行标签和列标签(x_label、y_label)进行索引,主要查询方法:
1.使用单个labe伯查询数据
2.使用值列表批查询
3.使用数伯区间进行范围查询
4.使用条件太达式查向
5.调用函数查询
loc先行后列,中间用逗号(,)分割。
4.1.1.0 数据准备
传入NBA球员薪资情况表:
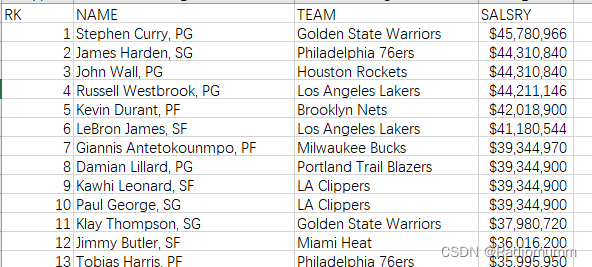
import pandas as pd
# 0.数据的预处理
filepatch=r"C:\Users\radiomumm\Desktop\sucai\nba.csv"
#读取csv文件数据
df=pd.read_csv(filepatch)
#设置列索引,inplace=True直接改变df格式
df.set_index("NAME",inplace=True)
#将"SALSRY"中的"$45,780,966"格式修改为"45780966"数值格式,以便于就绪操作。
df.loc[:,"SALSRY"]=df["SALSRY"].str.replace("$","").str.replace(",","").astype("int32")
4.1.1.1 使用单个label值查询数据
# 查询"Stephen Curry, PG"的薪资
print(df.loc["Stephen Curry, PG","SALSRY"])#返回单一值,"45780966"
# 查询"Stephen Curry, PG"的薪资和队伍
print(df.loc["Stephen Curry, PG",["SALSRY","TEAM"]])#返回一个Series
4.1.1.2使用值列表批量查询数据
# 查询"Stephen Curry, PG"/"James Harden, SG"/"John Wall, PG"的薪资
print(df.loc[["Stephen Curry, PG","James Harden, SG","John Wall, PG"],"SALSRY"])#得到一个series
print(df.loc[["Stephen Curry, PG","James Harden, SG","John Wall, PG"],["SALSRY","TEAM"]])#得到一个Dataframe
4.1.1.3使用数值区间批量查询数据
【区间既包含开始,也包含结束】
print(df.loc["Stephen Curry, PG":"John Wall, PG","SALSRY"])#行index查询,前三行的薪资
print(df.loc["Stephen Curry, PG","TEAM":"SALSRY"])#列index查询,第一行的两列数据
print(df.loc["Stephen Curry, PG":"John Wall, PG","TEAM":"SALSRY"])#行和列同时使用区间查询
4.1.1.4使用条件表达式查询
【bool列表的长度得等于行数或者列数】
# 查询薪资大于41018900的球员
print(df.loc[df["SALSRY"]>41018900,:])
# 查询薪资大于41018900的球员,且在"Los Angeles Lakers"队中。【每个条件由括号分隔】
print(df.loc[(df["SALSRY"]>41018900)&(df["TEAM"]=="Los Angeles Lakers"),:])
4.1.1.5使用函数查询
# 直接调用lambda函数,输入整个df,然后按条件筛选。
print(df.loc[lambda df :(df["SALSRY"]>41018900)&(df["TEAM"]=="Los Angeles Lakers"),:])
# 编写自己的函数进行查询,所有属于"Golden State Warriors"队的球员
def choose_maydata(df):
return df["TEAM"]=="Golden State Warriors"
print(df.loc[choose_maydata,:])
4.1.2 iloc
iloc 基于行索引和列索引(index,columns)都是从 0 开始
如果数据的行标签和列标签名字太长或不容易记,则用 iloc 很方便,只需记标签对应的索引即可。
print(df.iloc[0,2])#取出Stephen Curry, PG的薪资数据,"45780966"
print(df.iloc[0:2])#取前两行对应数据
print(df.iloc[:,0:2])#取前两列对应数据
print(df.iloc[0:2,0:2])#取前两行和前两列对应数据
print(df.iloc[[0,2],[0,1,2]])#取第一行和第三行、第一列和第四列对应的数据
5 Pandas新增数据列
【直接赋值/apply/assign/分条件赋值】
5.0 数据预处理
import pandas as pd
# 0.数据的预处理
filepatch=r"C:\Users\radiomumm\Desktop\sucai\nba.csv"
#读取csv文件数据
df=pd.read_csv(filepatch)
5.1直接赋值
和上文提到的修改数值方法相同,将Series格式看作为dictionary直接赋值。
# 选中df中的"SALSRY"列,对改列进行重新赋值,赋值内容为去除"$"和","并转化为int32格式
df.loc[:,"SALSRY"]=df["SALSRY"].str.replace("$","").str.replace(",","").astype("int32")
# 新增列,球员上场位置。
df.loc[:,"positions_TYPE"]=df["NAME"].str.replace("\w* \w*,","")
# 修改球员名字后的上场位置。
df.loc[:,"NAME"]=df["NAME"].str.replace(",.*","")
5.2 df.apply方法
这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数 会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
实例:添加一列实例:薪资大于40000000的为高薪,低于10500000的为底薪,否则就是正常薪资。
def get_SALSRY(df):
if df["SALSRY"]>=40000000:
return "high"
elif df["SALSRY"]<=10500000:
return "low"
else:
return "normal"
df.loc[:,"hight_low"]=df.apply(get_SALSRY,axis=1)#第0轴沿着行的垂直往下,第1轴沿着列的方向水平延伸。
#使用value_counts()函数对该列进行计数
x=df["hight_low"].value_counts()
print(x)
5.3 df.assign方法
能够同时新增多个列,返回一个新列,该对象除新列外,还包含所有原始列。【assgin不会改变原有df,因此需要重新赋值】
实例:添加一列球员人民币薪资
df=df.assign(RMB=lambda x :x["SALSRY"]*6.72)
5.4 按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
实例:PG球员薪资超过30000000认为是球星。
df["superstar"]=""
df.loc[df["SALSRY"]>=30000000,"superstar"]="star"
df.loc[df["SALSRY"]<30000000,"superstar"]="normal_player"
# print(df.head(120))
x=df["superstar"].value_counts()
print(x)
6 Pandas对缺值的处理
三类函数完成以上操作:
●isnll和notnull: 检测是否是空值,可用于df和series。
●dropna: 丢弃、删除缺失值
axis :删除行还是列,{0 or "index', 1 or 'columns’}, default 0
how :如果等于any则任何值为空都删除,如果等于al则所有值都为空才删除。
inplace :如果为True则修改当前df,否则返回新的df。
●fllna: 填充空值
value:用于填充的值,可以是单个值,或者字典(key是列名,value是值)。
method :等于il使用前一个不为空的值填充forword fll;等于bil使用后一个不为空的值填充backword fill。
axis: 按行还是列填充,{0 or index', 1 or 'columns'}
inplace :如果为True则修改当前df,否则返回新的df。
6.0 准备数据
录入qPCR的分析数据(excel):
其中skiprows=num这一参数能够忽略设置的行数,即skiprows=1:忽略第一行。
import pandas as pd
filepatch=r"C:\Users\radiomumm\Desktop\sucai\qpcr.xlsx"
df=pd.read_excel(filepatch,skiprows=1)#skiprows=num,忽略前num行读取。
6.1检测数据集中的空值
isnull返回的值均为True/False,适用于Dataframe和Series。
print(df.isnull())#返回整个Datafream中True/False,对应是否为空值。
print(df 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1927
1927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









